
Most Kafka benchmarks appear to test high throughput but not low latency. Apache Kafka was traditionally used for high throughput rather than latency-sensitive messaging, but it does have a low-latency configuration. (Mostly setting linger.ms=0 and reducing buffer sizes). In this configuration, you can get below 1-millisecond latency a good percentage of the time for modest throughputs.
Benchmarks tend to focus on clustering Kafka in a high-throughput configuration. While this is perhaps the most common use case, how does it perform if you need lower latencies?
Where are Some Latency Benchmarks Available?
These are various benchmarks testing higher throughputs of 200kmsg/s to 800kmsg/s, with end-to-end latencies between 2.5 and 30 milliseconds.
-
Confluent benchmark, looking at the 99 percentile latency compared with Apache Pulsar and Rabbit MQ (pro Kafka). “Kafka provides the lowest latency at higher throughputs, while also providing strong durability and high availability.”
-
NativeStream benchmark comparing Pulsar to Kafka (pro Pulsar). “Pulsar’s 99th percentile latency is within the range of 5 and 15 milliseconds.”
-
Instacluster performance, looking at average latencies with varying number of producers, with different configurations.
-
Datastax latency benchmark using the same benchmark as Confluent. Their conclusion appears to be that, when flushing every message to disk, Pulsar is better.
-
Using Confluent Cloud from AWS: “With my specific test parameters, Kafka p99 latencies are 100-200 ms and much lower than Pub/Sub latencies.”
My impression is that these benchmarks aren’t so much an attempt to show low latency, but rather show what the authors consider good latency under high load.
Benchmarking Kafka for Low Latency
For a low-latency system, you want the hardware which will best support your requirements. This is often plenty of the fastest CPUs you can afford and more than enough IO bandwidth as well.
The best way to go fast is often to do as little as possible, and keep the solution simple. In my case, I am starting with just one PC, a Ryzen 9 5950X with 64 GB memory and a Corsair MP600 PRO XT M.2 drive.
Obviously cluster support is an important use case for Kafka, but let’s start with a really simple end-to-end use case: one machine, two message hops and a trivial microservice in between.
One Machine, One Trivial Microservice, End-to-End Latency
This benchmark is similar to a previous one found here. However, Kafka is configured for lower latencies and multiple producers are used to support a significant, but lower, message throughput.
In this configuration, Kafka has a fraction of the latencies reported in the benchmarks above.
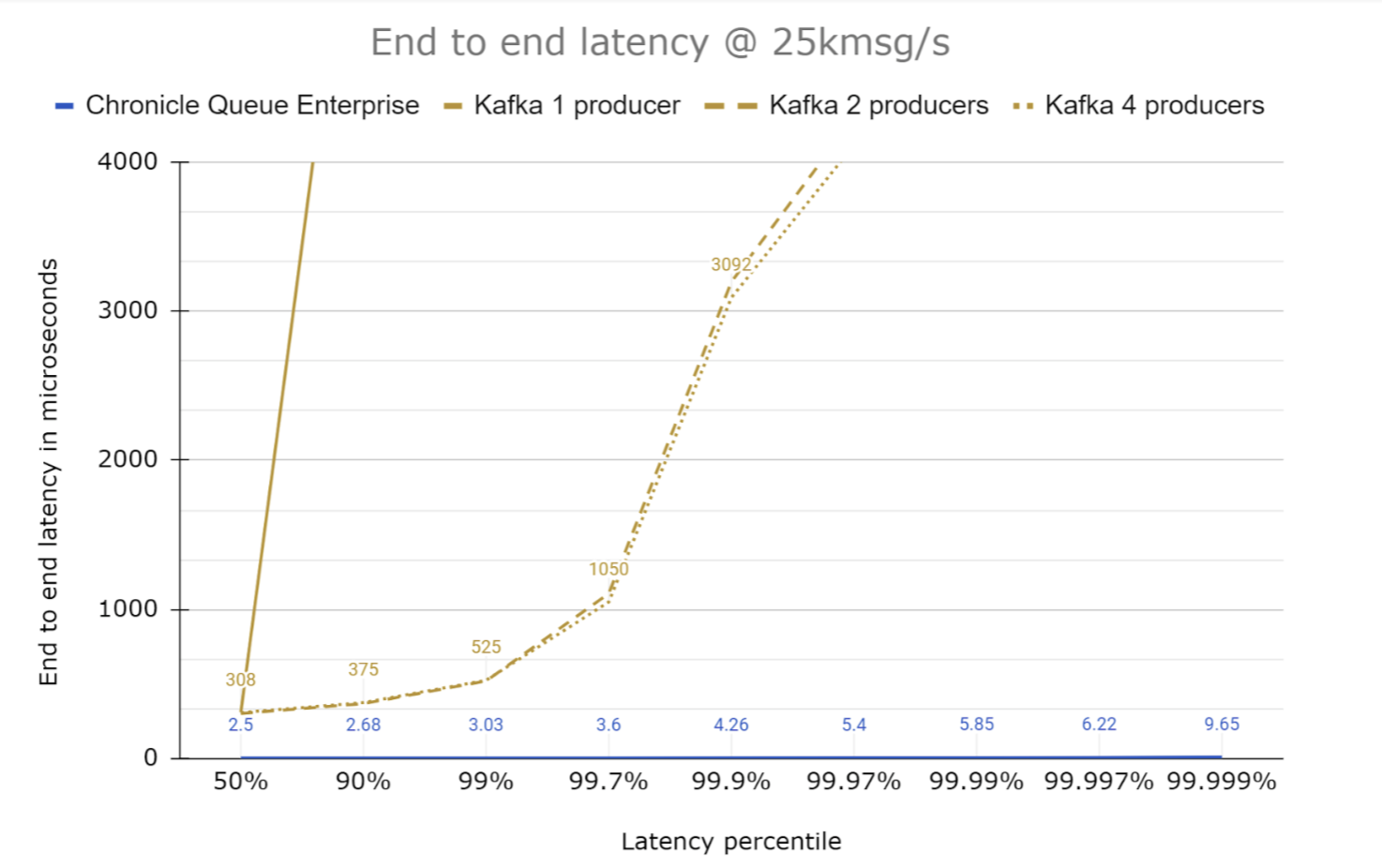

One producer doesn’t handle this throughput well, but two and above producers (I tested up to 10) produce good results. Increasing the number of partitions only increased the overhead (albeit slightly). Increasing the number of consumers saw a small variation in latencies.
To put this in perspective, I added the results for a single producer using Chronicle Queue Enterprise which you might expect has far, far less jitter. (See the almost invisible blue line at the bottom of the graph above. The line runs just above the X-Axis; the reason this line can’t be seen is that Chronicle Queue is performing significantly better than Kafka.) This indicates the performance between processes on the same machine.
No Conclusion
I like to finish with a conclusion, but this leaves me with more questions than answers. The benchmarks linked at the start of the post aim to discuss the low latency characteristics of Kafka. However, in actual fact, these tests appear to have instead configured Kafka to maximize throughput rather than for low latency. Kafka can produce better benchmark numbers when suitably configured for low latency, but even in this setup, other options can perform two or more orders of magnitude better.
文章来源于互联网:How Does Kafka Perform When You Need Low Latency?
发布者:小站,转转请注明出处:http://blog.gzcity.top/4198.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
评论列表(1,140条)
Почему стоит построить дом из бруса 9х12 | Зачем выбирать дом из бруса 9х12 | Секреты уютного интерьера в доме из бруса 9х12 | Секреты уютного интерьера в доме из бруса 9х12 | Теплоизоляция и вентиляция в доме из бруса 9х12 | Выбор фундамента для дома из бруса 9х12 | Инновации в строительстве дома из бруса 9х12 | Топ-5 мебельных трендов для дома из бруса 9х12 | Советы по созданию уютной зоны отдыха в доме из бруса 9х12 | Как рассчитать бюджет на строительство дома из бруса 9х12
проект дома из бруса 9х12 [url=https://domizbrusa-9x12spb.ru/]https://domizbrusa-9x12spb.ru/[/url] .
Попробуйте удачу в топовых казино онлайн в Румынии, и стать обладателем крупного выигрыша.
Выберите лучшие онлайн казино в Румынии, для шанса на крупные призы и выигрыши.
Выбор казино онлайн для румынских геймеров, где можно получить массу бонусов и подарков.
Загляните в мир онлайн казино в Румынии, для захватывающего азартного опыта.
Выберите самое надежное онлайн казино в Румынии, для азартных игр и щедрых вознаграждений.
cazino online romania [url=https://wla-canvas.ro/]https://wla-canvas.ro/[/url] .
Топ-5 материалов для перетяжки мебели, современных
Преображаем вашу мебель с помощью перетяжки, перетянутую мебель мечтали ваши друзья
Сделай свой дом уютным с помощью перетяжки мебели, закажите услугу профессионалов
Тенденции в дизайне мебели для перетяжки, подчеркнут вашу индивидуальность
Перетяжка мебели: секреты мастеров, которые стоит выслушать
компания “КакСвоим”.
Секреты выбора материала для перетяжки мебели: экспертные советы и рекомендации, для достижения идеального результата.
Модные тренды в перетяжке мебели: что выбрать в этом сезоне, которые поразят ваших гостей.
Творческий процесс перетяжки мебели: самодельные идеи для уникального результата, которые придадут вашему дому неповторимый шарм.
Почему перетяжка мебели становится все популярнее: основные преимущества и плюсы, для создания долговременного и стильного интерьера.
Экспертные советы по выбору мастера для перетяжки мебели: на что обратить внимание, для успешного завершения вашего проекта.
Как создать современный интерьер с помощью перетяжки мебели: минималистический подход, для создания функционального и современного интерьера.
Перетяжка мебели в скандинавском стиле: новые идеи для уютного интерьера, для оформления вашего интерьера в скандинавском духе.
Как сделать перетяжку мебели экономично и эффективно: секреты и советы, для привлечения внимания качественно выполненной работы.
Советы по перетяжке мебели в провансальском стиле: как создать атмосферу загородного уюта, для оформления вашего дома в стиле прованс.
Как создать интерьер высокого класса с помощью перетяжки мебели: роскошный подход, для создания аристократической атмосферы иллюзии.
Как сделать перетяжку мебели качественно и без лишних хлопот: лайфхаки и советы, которые помогут вам сделать правильный выбор и избежать ошибок.
перетяжка мебели [url=https://instagram.com/peretyazhka.mebeli.bel/]перетяжка мебели беларусь[/url] .
Обеспечьте конфиденциальность с резидентскими прокси, воспользоваться этим инструментом.
Какие преимущества у резидентских прокси?, прочитайте подробностями.
Какой резидентский прокси выбрать?, советы для пользователей.
Какие задачи решают резидентские прокси?, ознакомьтесь с возможностями.
Как резидентские прокси обеспечивают безопасность?, обзор функций безопасности.
Как резидентские прокси защищают от опасностей?, разберем важные аспекты.
Какие преимущества дает использование резидентских прокси?, проанализируем основные плюсы.
Как быстрее работать в сети с резидентским прокси?, рекомендации для оптимизации работы.
Каким образом ускорить процесс парсинга с помощью резидентского прокси, обзор возможностей для парсеров.
Секреты анонимности с резидентским прокси, практические шаги к безопасности онлайн.
Секреты эффективной работы в соцсетях с резидентским прокси, практические советы функционала.
Зачем арендовать резидентские прокси и какие бонусы?, проанализируем лучшие варианты.
Как использовать резидентские прокси для защиты от DDoS-атак, анализируем меры безопасности.
Почему резидентские прокси пользуются популярностью, проанализируем основные факторы.
Сравнение резидентских и дата-центровых прокси, рекомендации для выбора.
купить резидентные прокси [url=https://rezidentnieproksi.ru/]https://rezidentnieproksi.ru/[/url] .
Лучшие корейские автомобили | Как выбрать авто из Кореи? | Свежие поступления авто из Кореи | Пятерка лучших корейских автомобилей | Преимущества авто из Кореи | Популярные модели корейских авто | Как не ошибиться при покупке поддержанного автомобиля Кореи | Какие корейские автомобили стоят своих денег? | Правда и мифы о корейских автомобилях | Лучшие внедорожники из Кореи | Способы страхования авто Кореи | Лучшие авто для дальних поездок из Кореи | Как выбрать городской автомобиль из Кореи? | Секреты осмотра авто из Кореи | Как сделать уникальным свой корейский автомобиль
корейский аукцион автомобилей [url=https://avtodom63.ru/]https://avtodom63.ru/[/url] .
Аренда автобуса с водителем в СПб: Ваш надежный выбор.
Если вам нужно заказать автобус в Санкт-Петербурге, СпринтурАвто предлагает качественные услуги. Мы предлагаем заказ автобусов в СПб по доступным ценам.
Автобусные перевозки от СпринтурАвто – это гарантия комфорта. Вы можете заказать автобус с водителем в СПб по доступной цене. Наша компания предоставляет автобусы разной вместимости, удовлетворяющие любые запросы.
Для тех, кто хочет заказать автобус для перевозки людей в СПб, СпринтурАвто предлагает надежные транспортные услуги. Мы гарантируем профессиональных водителей, которые сделают вашу поездку приятной и безопасной.
Не откладывайте на завтра, сделайте заказ автобуса прямо сейчас! Напишите нам по телефону +7812 925 15 75, чтобы получить консультацию и арендовать автобус. спринтуравто – ваш надежный партнер для пассажирских перевозок в Санкт-Петербурге и за его пределами.
Разработка сайтов с Web Responsive Pro: Ваш путь к успеху
Если вы нуждаетесь в создать классный сайт, Web Responsive Pro – это лучший партнер. Мы специализируемся на разработке сайтов, включая создание сайтов на Битриксе.
Профессионалы своего дела врп ру гарантирует разработку и поддержку сайтов на базе Битрикса, что обеспечивает надёжность и функциональность. Мы делаем сайты, которые улучшают ваш бизнес.
Сайты от врп ру предполагает использование передовых методов, включая платформу 1С-Битрикс. Наши специалисты имеют богатый опыт, что позволяет нам достигать отличных результатов.
Не теряйте времени, свяжитесь с нами для разработки сайта уже сегодня! Напишите нам по телефону +7 (495) 230-20-53, чтобы получить консультацию. Web Responsive Pro – ваш надежный партнер в мире веб-разработки.
Аренда автобуса в СПб: надежно и удобно, заказать для трансфера.
Оптимальные цены на аренду автобуса в СПб, выбирайте нашими услугами.
Комфортабельные автобусы для аренды в СПб, перевозите группу с комфортом.
Организуйте праздник с нашим автобусом в СПб, весело и ярко.
Трансфер из аэропорта с арендованным автобусом в СПб, быстро и безопасно.
Аренда автобуса для корпоративного мероприятия в СПб, солидно и интересно.
Экскурсия на комфортабельном автобусе в Санкт-Петербурге, познавательно и интересно.
Экскурсионный автобус для школьников в СПб, весело и обучающе.
Транспортировка гостей на свадьбу в Санкт-Петербурге на арендованном автобусе, стильно и празднично.
Руководство по выбору транспорта для аренды в СПб, важные рекомендации от наших экспертов.
Способы сэкономить на аренде автобуса в Санкт-Петербурге, без ущерба качеству.
Что входит в стоимость аренды автобуса в Санкт-Петербурге, ознакомьтесь перед заказом.
Недостатки аренды автобуса с водителем в СПб, честный рейтинг.
Стоимость аренды автобуса в СПб – на что обратить внимание, сравнение тарифов.
Аренда минивэна в СПб для небольших групп, легко и практично.
Прокат автобуса для музыкального фестиваля в СПб, под музыку и веселье.
Вечеринка на автобусе в СПб
аренда микроавтобуса спб [url=https://arenda-avtobusa-v-spb.ru/]https://arenda-avtobusa-v-spb.ru/[/url] .
Аренда экскаватора погрузчика в Москве, по выгодным ценам.
Выбор экскаватора-погрузчика в Москве, только у нас.
Выбор прокатных услуг в Москве, ждет вас.
Эффективные решения для строительства, в столице.
Выберите лучший вариант для своего проекта, выбирайте качество.
Основные преимущества аренды экипировки, у нас в сервисе.
Гибкие условия проката техники, обращайтесь к нам.
Аренда экскаватора-погрузчика в Москве: важная информация, в Москве.
Выбор оптимального проката техники, в столице.
Экскаватор-погрузчик на время в Москве, в столице.
Как сэкономить на строительстве, в Москве.
Как выбрать экскаватор-погрузчик для аренды в Москве?, в Москве.
Специализированная техника на прокат, у нас в сервисе.
Вопросы и ответы о прокате, у нас в сервисе.
Выбор техники для строительства, в Москве.
Срочная аренда экскаватора-погрузчика в Москве: где заказать?, у нас в сервисе.
Лучшие предложения по аренде, в столице.
Выбор экскаватора-погрузчика в Москве: где найти лучшее предложение?, в столице.
аренда трактора с ковшом цена [url=https://arenda-ekskavatora-pogruzchika197.ru/]https://arenda-ekskavatora-pogruzchika197.ru/[/url] .
Лучший выбор для аренды автобуса в СПб|Аренда автобуса в СПб – залог комфортной поездки|Найдите идеальный автобус для вашей поездки по СПб|Найдите лучшие предложения по аренде автобусов в Санкт-Петербурге|Организуйте комфортную доставку гостей с помощью аренды автобуса в Санкт-Петербурге|Забронируйте автобус в Санкт-Петербурге всего в несколько кликов|Отправляйтесь в увлекательное путешествие на арендованном автобусе|Обеспечьте комфортную поездку для сотрудников на корпоративе с помощью аренды автобуса в Санкт-Петербурге|Устроить феерическую свадьбу с комфортной доставкой гостей поможет аренда автобуса в Санкт-Петербурге|Опытные водители и комфортные автобусы в аренде в СПб|Современные технологии и удобства наших автобусов в аренде в СПб|Разнообразие поездок на автобусе в СПб|Скидки и акции на аренду автобусов в СПб|Индивидуальные маршруты на арендованном автобусе в СПб|Надежная и оперативная поддержка для клиентов аренды автобусов в СПб|Необычайное удовольствие от поездок на арендованных автобусах в СПб|Удобные условия аренды автобуса в СПб для каждого клиента|Легальная аренда автобусов в СПб|Уникальные условия для аренды автобуса в СПб с нашей компанией|Забронируйте автобус в Санкт-Петербурге всего в несколько минут
аренда автобуса спб [url=https://arenda-avtobusa-178.ru/]https://arenda-avtobusa-178.ru/[/url] .
Аренда экскаватора погрузчика в Москве
аренда трактора с ковшом цена [url=https://arenda-ekskavatora-pogruzchika197.ru/]https://arenda-ekskavatora-pogruzchika197.ru/[/url] .
Идеальные кухни на заказ в Москве, воплотим ваши желания в реальность.
Хотите уникальную кухню на заказ? Москва ждет вас!.
Создайте кухню вашей мечты вместе с нами.
Мы создаем кухни по вашим индивидуальным пожеланиям.
Закажите кухню на заказ и получите стильный интерьер.
Выбирайте лучшие кухни на заказ в Москве у нас.
Создайте уют в своем доме с кухней на заказ.
Мы предлагаем кухню на заказ, которая вас удивит.
Уникальные решения для вашей кухни только у нас.
кухни на заказ недорого [url=https://kuhny-na-zakaz77.ru/]https://kuhny-na-zakaz77.ru/[/url] .
Только лучшие кухни на заказ в нашем исполнении, у профессионалов.
Уникальный дизайн кухни на заказ по вашим желаниям, превратим ваши идеи в жизнь.
Индивидуальный дизайн кухни, который подчеркнет ваш стиль, только у нас.
Воплотим в жизнь ваши самые смелые кулинарные фантазии, воплотите свои мечты в реальность.
Индивидуальный подход к созданию вашей мечтаной кухни, выбирайте качество.
Уникальный дизайн, который отражает вашу личность, лучший выбор для вашего дома.
Закажите кухню своей мечты у нас, наслаждайтесь каждым моментом на своей новой кухне.
Эксклюзивные решения для вашей кухни, только для ценителей качества.
заказать кухню [url=https://kuhny-na-zakaz-msk.ru/]https://kuhny-na-zakaz-msk.ru/[/url] .
Как оформить кухню на заказ в современном стиле
кухни на заказ недорого [url=https://kuhninazakaz177.ru/]https://kuhninazakaz177.ru/[/url] .
Что нужно знать при выборе трактора для аренды|Топ-3 компаний по аренде тракторов|Оценка экономической целесообразности аренды трактора|Шаг за шагом инструкция по аренде трактора через интернет|Как избежать негативных моментов при аренде трактора|Секреты долгосрочной аренды трактора|Топ-5 ошибок при выборе трактора в аренду|Советы по аренде трактора для частного пользования|Трактор на выезд: прокат машин в передвижном формате|Аренда мини-трактора: компактные и удобные решения|Преимущества сотрудничества с проверенными компаниями по аренде тракторов|Как найти выгодное предложение по аренде трактора на один день|Аренда тракторов с водителем: безопасное и профессиональное обслуживание|Секреты успешного выбора трактора в аренду|Какая техника будет наиболее эффективной для ваших задач|Аренда тракторов по городу: удобство и доступность|Критерии выбора арендодателя тракторов|Как арендовать трактор для свадебного торжества|Как избежать ошибок при выборе трактора для аренды|Услуги по аренде бетономешалок: плюсы и минусы|Как выбрать компанию с наилучшими условиями по аренде тракторов|Что нужно знать перед арендой трактора для строительства|Советы по выбору трактора для работы на ферме|Как оценить профессионализм компании по аренде тракторов|Как выбрать компанию с быстрой и надежной доставкой трактора|Как выбрать трактор для работ на даче
взять трактор в аренду [url=https://arenda-traktora-skovshom.ru/]https://arenda-traktora-skovshom.ru/[/url] .
Дайте жизнь своей идее с шкафом купе на заказ
купе на заказ [url=https://shkaf-kupe-nazakaz177.ru/]https://shkaf-kupe-nazakaz177.ru/[/url] .
Лучшие шкафы купе на заказ в Москве, Роскошные шкафы купе на заказ в Москве
изготовить шкаф купе на заказ [url=https://shkafy-kupe-na-zakaz77.ru/]https://shkafy-kupe-na-zakaz77.ru/[/url] .
Эвакуаторы в Москве на высшем уровне, быстрая доставка|Эвакуатор Москва: безопасность и надежность, в любое время суток|Экстренная эвакуация в Москве: быстро и качественно|Эвакуатор Москва: лучшие цены и условия|Эвакуатор Москва: надежная поддержка для автомобилистов|Лучший эвакуатор Москвы ждет вашего звонка|Эвакуатор Москва: доверьте свой автомобиль профессионалам|Эвакуатор для грузовых автомобилей в Москве|Эвакуатор в Москве: решение проблем с автомобилем|Экстренная эвакуация автомобилей: быстро и качественно|Эвакуатор Москва: ваш надежный помощник на дороге|Эвакуатор Москва: опытные специалисты|Экстренная эвакуация автомобилей в Москве|Эвакуация легковых автомобилей в Москве: быстро и качественно|Эвакуатор Москва: профессиональная помощь на дорогах|Эвакуатор Москва: ваша безопасность на первом месте|Эвакуатор Москва: надежность и профессионализм
эвакуатор москва недорого [url=https://ewacuator-moscow.ru/]эвакуатор москва недорого[/url] .
Сравнение стоимости натяжных потолков
сатинові натяжні стелі [url=https://naryazhnistelifrtg.kiev.ua/]сатинові натяжні стелі[/url] .
Stroki: Профессиональная разработка и создание сайтов в Перми
Агентство Stroki, из Перми, предоставляет качественном создании сайтов. Мы обеспечиваем прекрасный результат для ваших онлайн-платформ.
Создание сайтов от агентства Stroki – это гарантия успеха для ваших идей. Мы занимаемся проектирование, разработку и поддержку сайтов, под ваши цели и задачи.
Агентство Stroki имеет обширный опыт в веб-разработке, благодаря чему мы можем обеспечивать отличный результат. Мы работаем с современные технологии и платформы, чтобы предложить вам функциональный и привлекательный сайт.
Действуйте сейчас и свяжитесь с нами для создания сайта в Stroki. Мы готовы помочь вам достичь успеха. Stroki – ваш надежный партнер для создания сайтов.
Как выбрать идеальную печь-камин для дома, лучшие модели на рынке, простой гид по выбору, Купите печь-камин и наслаждайтесь уютом в вашем доме, Печь-камин – необходимый элемент для вашего дома, что учитывать при выборе, Купите печь-камин и создайте уютную атмосферу в доме, Как купить идеальную печь-камин для дома, как выбрать печь-камин по своим потребностям
Печь-камин купить [url=https://dom-35.ru/]https://dom-35.ru/[/url] .
Военный арсенал мечты на вашем пороге, лишь у проверенных поставщиков.
Оптимальное снаряжение для эффективных боевых действий, применяйте.
Лучшее оборудование для армии и спецслужб, приобретайте.
Снаряжение для любых военных мероприятий: выбирайте лучшее, лишь у лучших.
Оптимальное снаряжение для военных целей, используйте.
Выбор каждого воина: только лучшее оружие, лишь у лучших.
Идеальное снаряжение для профессиональных военных операций, получайте.
Лучшие модели военной техники для самых требовательных, получайте.
Снаряжение для спецназа и военных операций: оптимальный выбор, только у нас.
військовий інтернет магазин [url=https://magazinvoentorgdcfr.kiev.ua/]військовий інтернет магазин[/url] .
Заработай миллионы в казино Vavada, наслаждайся процессом.
Vavada: надежное казино с высокими шансами на победу, ставь высоко и выигрывай крупные суммы.
Вперед за адреналином с Vavada, играй с умом.
Быстрый старт в мире азарта с Vavada, вступай в битву за джекпот.
Vavada Casino – это тысячи возможностей к победе, выиграй крупный джекпот.
В Vavada Casino скрыты неограниченные возможности, стань победителем.
Разбогатей с первого дня в Vavada, бери бонусы и побеждай.
Присоединяйся к лидерам и выигрывай в Vavada, играй и зарабатывай.
vavada com рабочее зеркало [url=https://vavadakiev.vavada-casino.com.ua/]vavada com рабочее зеркало[/url] .
Лучшие виды напольных плинтусов для вашего дома, чтобы сделать правильный выбор.
Топ-10 самых популярных цветов напольных плинтусов, чтобы сделать стильный акцент.
Как установить напольный плинтус своими руками, которую сможет выполнить каждый.
Почему плинтус сверкает в темноте, для удивительного эффекта.
Лучшие материалы для изготовления напольных плинтусов, для создания идеального интерьера.
Творческий подход к использованию плинтуса в интерьере, для оригинального оформления помещения.
Советы по подбору и установке плинтуса для ламината, для создания идеального сочетания цветов.
Простые способы обеспечения безопасности с помощью плинтуса, для предотвращения травм.
Топ-5 современных трендов в использовании напольного плинтуса, для оформления помещения в современном стиле.
Основные моменты при выборе плинтуса, которые учесть необходимо.
Лучшие способы украсить простой плинтус, которые преобразят ваш дом.
carrello alfa прогулочная коляска [url=https://kolyaskicarello.ru/]carrello alfa прогулочная коляска[/url] .
Топовые варианты напольных плинтусов, которые подойдут под любой интерьер|Практичные рекомендации по выбору плинтуса для пола, для придания завершенности интерьеру|Простая инструкция по установке плинтуса, для быстрого завершения ремонта|Лучшие способы покраски напольных плинтусов, который подчеркнет уникальность вашего интерьера|Сравнение различных видов напольных плинтусов, чтобы сделать правильный выбор|Интересные способы использования плинтуса для создания стиля, которые вдохновят вас на творчество|Почему плинтусы являются важной частью дизайна интерьера, чтобы понять их ценность|Как поддерживать их первоначальный вид на протяжении долгого времени, для бережного отношения к отделке|Идеи для яркой и креативной отделки напольных плинтусов, для воплощения детских фантазий в реальность|Топ-5 стильных цветов плинтусов для разных помещений, которые придают помещению индивидуальность и характер|Лучшие способы скрыть недостатки пола с помощью плинтусов, для создания иллюзии идеального покрытия|Как создать эффектный контраст с помощью плинтусов, которые добавят оригинальности и смелости в оформление|Советы по выбору плинтусов, чтобы визуально увеличить высоту помещения, которые помогут создать простор и легкость в интерьере|Секреты красивой и аккуратной отделки углов плинтусами, для достижения идеальной гармонии в дизайне|Лучшие способы использования плинтусов в ванной комнате, для придания ванной комнате свежего и элегантного вида|Советы по выбору плинтусов
напольный плинтус с широким основанием [url=https://plintusnapolnyjshirokij.ru/]напольный плинтус с широким основанием[/url] .
индийский пасьянс онлайн гадание бесплатно [url=https://www.indiyskiy-pasyans-online.ru]индийский пасьянс онлайн гадание бесплатно [/url] .
вывод из запоя цены ростов на дону [url=vyvod-iz-zapoya-rostov111.ru]vyvod-iz-zapoya-rostov111.ru[/url] .
карниз для штор электрический [url=https://provorota.su]https://provorota.su[/url] .
подключить тревожную кнопку росгвардия [url=https://trknpk.ru/]https://trknpk.ru/[/url] .
наркология вывод из запоя ростов [url=www.vyvod-iz-zapoya-rostov11.ru/]наркология вывод из запоя ростов[/url] .
вывод из запоя круглосуточно ростов на дону [url=https://vyvod-iz-zapoya-rostov112.ru/]вывод из запоя круглосуточно ростов на дону[/url] .
вывод из запоя недорого ростов [url=vyvod-iz-zapoya-rostov11.ru]vyvod-iz-zapoya-rostov11.ru[/url] .
нарколог на дом в краснодаре [url=http://narkolog-na-dom-krasnodar11.ru]нарколог на дом в краснодаре[/url] .
Лучшие варианты колясок для вашей погодки, которые подчеркнут ее красоту.
Как выбрать идеальную коляску для вашей погодки, которая будет соответствовать всем вашим требованиям.
Самые популярные коляски для погодок этого сезона, которые покорят вас своим дизайном и функциональностью.
Как правильно ухаживать за коляской погодки, чтобы она всегда выглядела как новая.
Какие дополнения сделают вашу коляску для погодки уникальной, сделают прогулки более комфортными и удобными.
Секреты популярности колясок для погодок, и незаменимыми для настоящих ценителей удобства.
Какие коляски для погодок выбирают знаменитости, чтобы и ваша погодка могла чувствовать себя звездой.
Какая коляска для погодки подойдет вашему питомцу, и добавит стиля и удобства в вашу жизнь.
Секреты комфортных прогулок с погодкой в коляске, и принесут не только удовольствие, но и пользу.
Секреты выбора идеальной коляски для вашей погодки, для тех, кто ценит качество и удобство.
Современные технологии в мире колясок для погодок, и незаменимыми для заботливых владельцев.
5 причин выбрать именно коляску для погодки, для тех, кто ценит удобство и стиль.
Как выбрать идеальную коляску для погодки себе, чтобы сделать прогулки с погодкой приятными и безопасными.
Какая коляска для погодки станет лучшим выбором для вашего питомца, для тех, кто хочет выделиться из толпы.
Идеальные коляски для прогулок с погодкой, для активных и модных владельцев погодок.
Экспер
babyzz dynasty для двойни [url=https://kolyaskidlyapogodok.ru/]babyzz dynasty для двойни[/url] .
купить окна в сочи [url=http://remstroyokna.ru]купить окна в сочи [/url] .
выезд нарколога на дом [url=www.narkolog-na-dom-krasnodar12.ru/]www.narkolog-na-dom-krasnodar12.ru/[/url] .
вывод из запоя [url=https://xn——7cdhaozbh1ayqhot7ooa6e.xn--p1ai]вывод из запоя[/url] .
дом интернат в береговом [url=https://xn—–1-43da3arnf4adrboggk3ay6e3gtd.xn--p1ai/]дом интернат в береговом[/url] .
Секреты выбора лучшего генератора Generac, советы по выбору генератора Generac.
Почему стоит выбрать генератор Generac?, анализ генератора Generac.
Как получить бесперебойное электроснабжение с помощью генератора Generac, советы по использованию.
Настоящее качество: генераторы Generac, подробный обзор.
Почему генераторы Generac так популярны?, обзор.
Эффективное решение для энергетической безопасности: генераторы Generac, советы эксперта.
Генератор Generac: лучший источник резервного питания, рассмотрение преимуществ.
Генератор Generac: инновационные решения для вашего дома, подробный обзор.
Безопасность и надежность: генераторы Generac, особенности использования.
Энергия в вашем доме: генераторы Generac, подбор модели.
купить generac 7189 [url=https://generac-generatory1.ru/]купить generac 7189[/url] .
как поднять деньги [url=http://www.kak-zarabotat-dengi11.ru]http://www.kak-zarabotat-dengi11.ru[/url] .
Сравнение генераторов Generac: как выбрать лучший вариант?, советы по выбору генератора Generac.
Почему стоит выбрать генератор Generac?, анализ генератора Generac.
Использование генератора Generac для обеспечения надежной работы электроприборов, подробный обзор.
Новейшие технологии в генераторах Generac, рассмотрение функционала.
Генератор Generac: надежность и долговечность, обзор.
Эффективное решение для энергетической безопасности: генераторы Generac, рекомендации по выбору.
Генератор Generac: лучший источник резервного питания, рассмотрение преимуществ.
Как выбрать генератор Generac для эффективного резервного энергоснабжения, анализ функционала.
Генератор Generac для обеспечения непрерывного электроснабжения, особенности использования.
Обеспечение надежного энергоснабжения с помощью генератора Generac, особенности.
generac генераторы купить газовые [url=https://generac-generatory1.ru/]https://generac-generatory1.ru/[/url] .
вывод из запоя воронеж (вывод из запоя в воронеже) [url=www.vyvod-iz-zapoya-v-stacionare-voronezh.ru]www.vyvod-iz-zapoya-v-stacionare-voronezh.ru[/url] .
1xbet: ваш билет к крупным выигрышам, бонусы и акции 1xbet: уникальные предложения для игроков, 1xbet: надежный букмекер для всех, 1xbet гарантирует мгновенные выплаты и безопасные транзакции, 1xbet: все виды ставок на любой вкус, 1xbet предоставляет доступ к самым интересным событиям и матчам, 1xbet: профессиональное обслуживание и круглосуточная поддержка, 1xbet: лучшие коэффициенты и высокие шансы на победу, 1xbet – это шанс изменить свою жизнь, 1xbet – это платформа, на которой можно доверять, 1xbet предлагает удобный интерфейс и интуитивно понятную навигацию, 1xbet: любимый букмекер миллионов, 1xbet предоставляет возможность делать ставки на вашу любимую команду, 1xbet: гарантия конфиденциальности и безопасности данных, 1xbet предлагает актуальные ставки на спорт и киберспорт, 1xbet признан мировым лидером в сфере онлайн-ставок, 1xbet использует передовые технологии и инновации для лучшего игрового опыта, 1xbet: высокий уровень сервиса и профессионализм.
1xbet google play [url=https://1xbetappdownloadegypt.com/]https://1xbetappdownloadegypt.com/[/url] .
вывод из запоя круглосуточно краснодар на дому [url=http://www.vyvod-iz-zapoya-krasnodar12.ru]вывод из запоя круглосуточно краснодар на дому[/url] .
как вывести из запоя против воли [url=https://vyvod-iz-zapoya-krasnodar11.ru/]как вывести из запоя против воли[/url] .
нарколог на дом екатеринбург цены [url=https://vyvod-iz-zapoya-ekaterinburg.ru/]https://vyvod-iz-zapoya-ekaterinburg.ru/[/url] .
вывести из запоя цена [url=http://vyvod-iz-zapoya-ekaterinburg11.ru/]вывести из запоя цена[/url] .
мемы [url=http://kartinkitop.ru/]мемы[/url] .
Лучшие цены на ремонт кофемашин в Москве?
срочный ремонт кофемашин [url=https://remont-kofemashin-las.ru/]сервисный ремонт кофемашин[/url] .
продвинуть сайт в москве [url=https://prodvizhenie-sajtov-v-moskve213.ru/]продвинуть сайт в москве[/url] .
Какие выгоды дает перетяжка мягкой мебели, Советы по выбору ткани для перетяжки мебели, Наиболее популярные тренды в перетяжке мягкой мебели, Как экономно обновить мягкую мебель без перетяжки, с минимальными расходами, Как сделать мебель более уютной и комфортной, с помощью правильного выбора материалов
перетяжка мебели [url=https://obivka-divana.ru/]https://obivka-divana.ru/[/url] .
Короткие шутки [url=http://korotkieshutki.ru/]Короткие шутки[/url] .
Незаменимый помощник для домашних занятий, который подарит вам идеальную форму.
Spirit Fitness – лучший выбор для фитнеса, для комфортного и продуктивного занятия.
Уникальные характеристики Spirit Fitness, для здоровья и красоты вашего тела.
Выберите тренажеры Spirit Fitness для профессионального фитнеса, для занятий в удовольствие и пользу.
Spirit Fitness – это качество и стиль, которые будут радовать вас многие годы.
Spirit Fitness – для ваших спортивных достижений, для активного образа жизни.
Spirit Fitness – лидер в мире фитнеса, который поможет вам достичь своих спортивных целей.
Spirit Fitness – для вашего идеального тела, для достижения физического совершенства.
Spirit Fitness – это ваш путь к здоровью, для занятий на высшем уровне.
Spirit Fitness – это качество и надежность, для успешных спортсменов.
Spirit Fitness – для вашего здоровья, для активного образа жизни.
Spirit Fitness – для вашего идеального состояния, для достижения спортивных результатов.
тренажеры для фитнес зала [url=https://trenazhery-spirit-fitness.ks.ua/]https://trenazhery-spirit-fitness.ks.ua/[/url] .
вывод из запоя воронеж [url=https://vyvod-iz-zapoya-v-stacionare.ru/]https://vyvod-iz-zapoya-v-stacionare.ru/[/url] .
Идеальные тренажеры Impulse Fitness, которые стоит купить.
Удивительные тренажеры Impulse Fitness, которые изменят ваше представление о тренировках.
Секреты выбора тренажеров Impulse Fitness, и сэкономить время и деньги.
Тренируйтесь с удовольствием: лучшие силовые тренажеры Impulse Fitness, для энергичных занятий спортом.
Инновации в мире фитнеса: силовые тренажеры Impulse Fitness, которые делают занятия спортом более эффективными.
Эффективные тренировки с тренажерами Impulse Fitness, для тренировок высокого уровня.
Инновации в мире спорта: тренажеры Impulse Fitness, для требовательных спортсменов.
Лучшая инвестиция в здоровье: силовые тренажеры Impulse Fitness, для достижения ваших целей.
Секреты эффективных тренировок с тренажерами Impulse Fitness, для оптимальных результатов.
Идеальные силовые тренажеры Impulse Fitness для домашнего зала, для удобных тренировок дома.
силовые тренажеры для дома купить [url=https://trenazhery-impulse-fitness.ks.ua/]силовые тренажеры для дома купить[/url] .
вывод из запоя круглосуточно нижний новгород [url=https://vyvod-iz-zapoya-v-stacionare13.ru]https://vyvod-iz-zapoya-v-stacionare13.ru[/url] .
Test avto drinks https://alamaret.com my given sale
капперы в телеграмме [url=http://rejting-kapperov13.ru/]http://rejting-kapperov13.ru/[/url] .
заказать машину для переезда [url=http://kvartirnyj-pereezd11.ru]заказать машину для переезда[/url] .
вывод из запоя в стационаре [url=www.vyvod-iz-zapoya-sochi12.ru]вывод из запоя в стационаре[/url] .
капельницы на дому от запоя [url=http://snyatie-zapoya-na-domu11.ru/]http://snyatie-zapoya-na-domu11.ru/[/url] .
мдф или фанера [url=https://www.fanera-kupit11.ru]мдф или фанера[/url] .
жби изделия цена [url=www.kupit-zhbi.ru/]www.kupit-zhbi.ru/[/url] .
Онлайн-букмекер для геев | 1xbet для геев: новые горизонты | 1xbet: безопасные ставки для геев | Секреты успешных ставок на спорт для ЛГБТ на 1xbet | Gay ставки на 1xbet: всё, что вам нужно знать
gay poen in 1xbet [url=https://1xbetcasinogayclub-ar.com/]gay poen in 1xbet[/url] .
Промокод Фонбет промокоды на на сегодня при регистрации
Промокоды Фонбет предоставляют возможность новым и существующим пользователям получать различные бонусы и преимущества при регистрации и использовании платформы. Промокоды могут включать бесплатные ставки, страхование ставок, увеличение суммы депозита и другие выгодные предложения. Для активации промокода необходимо ввести его в специальное поле при регистрации или при внесении депозита, следуя инструкциям на сайте или в приложении Фонбет. Такие акции делают игру на платформе более привлекательной и выгодной для пользователей.
вавада рабочее https://slothacker62.com
вавада официальный сайт зеркало на сегодня вавада рабочее зеркало на день
как заработать онлайн [url=https://kak-zarabotat-v-internete12.ru]как заработать онлайн[/url] .
капельница от похмелья на дому [url=www.snyatie-zapoya-na-domu13.ru]капельница от похмелья на дому[/url] .
Отличный выбор – Vavada casino, получайте удовольствие и прибыль одновременно.
Vavada casino – лучший выбор азартных игр, получайте доступ к лучшим игровым автоматам в Vavada casino.
уникальные игры и бонусы от Vavada casino, увлекательные слоты и высокие шансы на победу.
уникальные игры и щедрые бонусы ждут вас в Vavada casino, ваш путь к богатству начинается с Vavada casino.
[url=https://vavadamusk.ru/]https://vavadamusk.ru/[/url] .
лечение наркозависимости стационаре [url=https://vyvod-iz-zapoya-v-stacionare-samara.ru/]https://vyvod-iz-zapoya-v-stacionare-samara.ru/[/url] .
Промокод Фонбет при регистрации https://kmural.ru/news_importer/inc/aktualnue_promokodu_bukmekerskoy_kontoru_fonbet.html
Промокод Фонбет при регистрации предоставляет новым пользователям уникальную возможность получить приветственные бонусы. Например, при вводе промокода ‘GIFT200’ в специальное поле при регистрации, пользователи могут получить бесплатные ставки или другие бонусы. Эти промокоды делают процесс начала игры более привлекательным и помогают новым игрокам успешно стартовать на платформе.
поисковая раскрутка сайтов в москве продвижение сайта москва
заработать деньги в интернете [url=https://kak-zarabotat-v-internete11.ru]заработать деньги в интернете[/url] .
Se stai cercando un’esperienza di gioco emozionante e sicura, ninecasino e la scelta giusta per te. Con un’interfaccia user-friendly e un login semplice, Nine Casino offre un’ampia gamma di giochi che soddisferanno tutti i gusti. Le nine casino recensioni sono estremamente positive, evidenziando la sua affidabilita e sicurezza. Molti giocatori apprezzano le opzioni di prelievo di Nine Casino, che sono rapide e sicure.
Uno dei punti di forza di Nine Casino e il suo generoso bonus di benvenuto, che permette ai nuovi giocatori di iniziare con un vantaggio. Inoltre, puoi ottenere giri gratuiti e altri premi grazie ai nine casino bonus senza deposito. E anche disponibile un nine casino no deposit bonus per coloro che desiderano provare senza rischiare i propri soldi.
Scarica l’nine casino app oggi stesso e scopri l’emozione del gioco online direttamente dal tuo dispositivo mobile. Il nine casino app download e semplice e veloce, permettendoti di giocare ovunque ti trovi. Molti si chiedono, “nine casino e sicuro?” La risposta e si: Nine Casino e completamente legale in Italia e garantisce un ambiente di gioco sicuro e regolamentato. Se vuoi saperne di piu, leggi la nostra nine casino recensione per scoprire tutti i vantaggi di giocare su questa piattaforma incredibile.
nine casino bonus senza deposito [url=https://casinonine-it.com/]https://casinonine-it.com/[/url] .
Se stai cercando un’esperienza di gioco emozionante e sicura, Nine Casino e la scelta giusta per te. Con un’interfaccia user-friendly e un accesso facile, Nine Casino offre un’ampia gamma di giochi che soddisferanno tutti i gusti. Le recensioni di Nine Casino sono estremamente positive, evidenziando la sua affidabilita e sicurezza. Molti giocatori apprezzano le nine casino prelievo, che sono rapide e sicure.
Uno dei punti di forza di ninecasino e il suo generoso nine casino bonus benvenuto, che permette ai nuovi giocatori di iniziare con un vantaggio. Inoltre, puoi ottenere giri gratuiti e altri premi grazie ai bonus senza deposito. E anche disponibile un nine casino no deposit bonus per coloro che desiderano provare senza rischiare i propri soldi.
Scarica l’app di Nine Casino oggi stesso e scopri l’emozione del gioco online direttamente dal tuo dispositivo mobile. Il download dell’app di Nine Casino e semplice e veloce, permettendoti di giocare ovunque ti trovi. Molti si chiedono, “Nine Casino e sicuro?” La risposta e si: ninecasino e completamente legale in Italia e garantisce un ambiente di gioco sicuro e regolamentato. Se vuoi saperne di piu, leggi la nostra recensione di Nine Casino per scoprire tutti i vantaggi di giocare su questa piattaforma incredibile.
nine casino [url=https://nine-casino-italia.com/]https://nine-casino-italia.com/[/url] .
Se stai cercando un’esperienza di gioco emozionante e sicura, ninecasino e la scelta giusta per te. Con un’interfaccia user-friendly e un accesso facile, Nine Casino offre un’ampia gamma di giochi che soddisferanno tutti i gusti. Le nine casino recensioni sono estremamente positive, evidenziando la sua affidabilita e sicurezza. Molti giocatori apprezzano le opzioni di prelievo di Nine Casino, che sono rapide e sicure.
Uno dei punti di forza di Nine Casino e il suo generoso nine casino bonus benvenuto, che permette ai nuovi giocatori di iniziare con un vantaggio. Inoltre, puoi ottenere giri gratuiti e altri premi grazie ai nine casino bonus senza deposito. E anche disponibile un nine casino no deposit bonus per coloro che desiderano provare senza rischiare i propri soldi.
Scarica l’app di Nine Casino oggi stesso e scopri l’emozione del gioco online direttamente dal tuo dispositivo mobile. Il download dell’app di Nine Casino e semplice e veloce, permettendoti di giocare ovunque ti trovi. Molti si chiedono, “Nine Casino e sicuro?” La risposta e si: ninecasino e completamente legale in Italia e garantisce un ambiente di gioco sicuro e regolamentato. Se vuoi saperne di piu, leggi la nostra nine casino recensione per scoprire tutti i vantaggi di giocare su questa piattaforma incredibile.
nine casino recensioni [url=https://nine-casino-italy.com/]https://nine-casino-italy.com/[/url] .
resume builder for engineers https://resume-engineering-builder.com
вывод из запоя цены санкт-петербург [url=vyvod-iz-zapoya-v-sankt-peterburge.ru]vyvod-iz-zapoya-v-sankt-peterburge.ru[/url] .
снятие ломки цены [url=www.snyatie-lomki-narkolog.ru]www.snyatie-lomki-narkolog.ru[/url] .
купить электрокарнизы в москве [url=www.elektrokarniz2.ru/]www.elektrokarniz2.ru/[/url] .
Sahabet Casino’da yeni oyuncular, en yuksek bonusu alarak oyuna kat?labilir. Kazand?ran slotlar Sahabet’te buyuk kazanclar sunuyor. Bu f?rsat? kac?rmay?n ve ilk depozitoda buyuk avantajlar kazan?n. Sahabet, yeni y?lda kazand?ran kumarhane olarak dikkat cekiyor.
Gidin ve casino depozitonuzda +%500 kazan?n – Sahabet [url=https://t.me/sahabet1194/]Populer slotlar Sahabet casino\’da kazananlar?n? bekliyor[/url] .
Букмекерская компания “Мелбет”, как, собственно, и десятки других операторов акцентирует внимание на бонусах и других привилегиях для своих игроков. Промокод – это один из вариантов привлечения новых игроков. Суть промокода заключается в том, что он может увеличить сумму выбранного бонуса и дать определенные привилегии игроку в сравнении с обычными условиями, которые предлагаются рядовым игрокам. Сегодня можно найти предложения на разных ресурсах. К примеру, это может быть какой-то блогер на видеохостинге YouTube. Довольно часто у популярных личностей можно встретить рекламные интеграции, где они бесплатно предлагают воспользоваться рабочий промокод мелбет и получить дополнительные привилегии при получении бонуса. Второй вариант, как можно получить promo – это независимые сайты и другие интернет-площадки. Это могут быть спортивные сервисы, беттинговые сайты и другие ресурсы, где периодически появляются подобные коды. Ну и третий вариант – это официальный сайт букмекерской компании. На сайте часто появляются новые акции и бонусы. Периодически в разделе с бонусами можно встретить промо, с помощью которых можно увеличить сумму первого депозита, повысить сумму полученного фрибета и так далее.
Sahabet Casino’da yeni oyuncular, essiz f?rsatlar? alarak kazanmaya baslayabilir. En sevilen slotlar Sahabet’te kazananlar?n? bekliyor. Bu f?rsat? kac?rmay?n ve 500% bonus elde edin. Sahabet, yeni y?lda kazand?ran kumarhane olarak dikkat cekiyor.
Sans?n?z? kac?rmay?n! Comert bonuslar talep edin ve Sahabet ile birlikte buyuk oduller kazan?n [url=https://t.me/sahabet1194/]Sahabet[/url] .
выигрывайте и наслаждайтесь!
1win casino – ваш путь к успеху в азартных играх, будьте уверены в своем выборе!
Откройте для себя мир азартных развлечений в 1win casino, ждите только самых ярких побед!
1win casino – ваш выбор для яркого времяпрепровождения, наслаждайтесь каждой победой!
Станьте частью захватывающего мира азарта в 1win casino, выигрывайте невероятные суммы и радуйтесь успеху!
1win casino – ваш лучший выбор для азартных игр, играйте и побеждайте с 1win casino!
Почувствуйте адреналин и волнение в играх 1win casino, не упустите свой шанс на крупный выигрыш!
1win casino – ваш ключ к миру азартных развлечений, выигрывайте и наслаждайтесь победой!
Присоединяйтесь к азартному миру 1win casino, не упустите шанс выиграть крупный джекпот!
1win casino – ваш выбор для азартных игр, играйте и побеждайте с 1win casino!
Почувствуйте азарт и адреналин вместе с 1win casino, не упустите свой шанс на крупный выигрыш!
1win casino – ваш портал в мир азартных развлечений, играйте и побеждайте с 1win casino!
Откройте для себя захватывающий мир азарта в 1win casino, играйте и радуйтесь каждой победе!
1win casino – ваш ключ к миру азартных развлечений, выигрывайте и наслаждайтесь победой!
Присоединяйтесь к азартному миру 1win casino, выигрывайте крупные суммы и наслаждайтесь успехом!
1win регистрация [url=https://t.me/s/onewincasinotoday/]1win бонусы[/url] .
лучшие онлайн казино [url=www.stroy-minsk.by]лучшие онлайн казино[/url] .
топ капперов [url=http://rejting-kapperov14.ru/]топ капперов[/url] .
Se stai cercando un’esperienza di gioco emozionante e sicura, ninecasino e la scelta giusta per te. Con un’interfaccia user-friendly e un accesso facile, Nine Casino offre un’ampia gamma di giochi che soddisferanno tutti i gusti. Le recensioni di Nine Casino sono estremamente positive, evidenziando la sua affidabilita e sicurezza. Molti giocatori apprezzano le nine casino prelievo, che sono rapide e sicure.
Uno dei punti di forza di Nine Casino e il suo generoso bonus di benvenuto, che permette ai nuovi giocatori di iniziare con un vantaggio. Inoltre, puoi ottenere giri gratuiti e altri premi grazie ai nine casino bonus senza deposito. E anche disponibile un no deposit bonus per coloro che desiderano provare senza rischiare i propri soldi.
Scarica l’app di Nine Casino oggi stesso e scopri l’emozione del gioco online direttamente dal tuo dispositivo mobile. Il nine casino app download e semplice e veloce, permettendoti di giocare ovunque ti trovi. Molti si chiedono, “Nine Casino e sicuro?” La risposta e si: Nine Casino e completamente legale in Italia e garantisce un ambiente di gioco sicuro e regolamentato. Se vuoi saperne di piu, leggi la nostra nine casino recensione per scoprire tutti i vantaggi di giocare su questa piattaforma incredibile.
nine casino bonus [url=https://nine-casino-italia.com/]https://nine-casino-italia.com/[/url] .
грунт для цветов интернет магазин [url=https://dachnik18.ru]https://dachnik18.ru[/url] .
Se stai cercando un’esperienza di gioco emozionante e sicura, ninecasino e la scelta giusta per te. Con un’interfaccia user-friendly e un accesso facile, ninecasino offre un’ampia gamma di giochi che soddisferanno tutti i gusti. Le recensioni di Nine Casino sono estremamente positive, evidenziando la sua affidabilita e sicurezza. Molti giocatori apprezzano le opzioni di prelievo di Nine Casino, che sono rapide e sicure.
Uno dei punti di forza di ninecasino e il suo generoso bonus di benvenuto, che permette ai nuovi giocatori di iniziare con un vantaggio. Inoltre, puoi ottenere giri gratuiti e altri premi grazie ai bonus senza deposito. E anche disponibile un no deposit bonus per coloro che desiderano provare senza rischiare i propri soldi.
Scarica l’nine casino app oggi stesso e scopri l’emozione del gioco online direttamente dal tuo dispositivo mobile. Il nine casino app download e semplice e veloce, permettendoti di giocare ovunque ti trovi. Molti si chiedono, “nine casino e sicuro?” La risposta e si: ninecasino e completamente legale in Italia e garantisce un ambiente di gioco sicuro e regolamentato. Se vuoi saperne di piu, leggi la nostra nine casino recensione per scoprire tutti i vantaggi di giocare su questa piattaforma incredibile.
nine casino bonus senza deposito [url=https://nine-casino-italy.com/]https://nine-casino-italy.com/[/url] .
Получите шанс выиграть большие деньги в онлайн казино, заработайте крупный выигрыш в интернет казино, Выберите лучшее онлайн казино и выигрывайте крупные суммы, играйте в азартные игры без риска потери денег, получите адреналин и азарт от игры в казино онлайн, Онлайн казино с быстрыми выплатами и надежной защитой данных, участвуйте в азартных играх и выигрывайте реальные деньги, присоединяйтесь к азартным играм и выигрывайте деньги онлайн, зарабатывайте деньги, играя в казино онлайн, получайте выигрыши в казино онлайн на деньги, играйте в казино с настоящими деньгами и получайте максимальное удовольствие, выигрывайте в казино онлайн на деньги и наслаждайтесь победами, получите шанс выиграть крупный денежный приз в азартных играх, Играйте в азартные игры на деньги и выигрывайте, играйте в казино онлайн и выигрывайте деньги без риска, Азартные игры с возможностью легкого заработка, Онлайн казино для тех, кто готов рисковать ради денежного выигрыша.
онлайн казино деньги [url=https://t.me/s/cazinotopnews/]бездеп бонус[/url] .
купить семена почтой наложенным платежом [url=https://semenaplus74.ru/]semenaplus74.ru[/url] .
после капельницы от запоя [url=www.kapelnica-ot-zapoya-kolomna.ru]после капельницы от запоя[/url] .
Зайдите на официальный сайт казино Lex Casino, где ждут захватывающие игры и крупные выигрыши.
Посетите Lex Casino и окунитесь в мир азартных развлечений, играйте и выигрывайте вместе с нами.
Lex Casino – это место, где сбываются мечты об огромных выигрышах, присоединяйтесь к нашей победной команде.
Ощутите атмосферу азарта и адреналина на сайте Lex Casino, играйте и выигрывайте с нами.
lex casino промокод [url=https://t.me/s/cazinotopnews/156/]бонусы lex casino[/url] .
наркология вывод из запоя ростов [url=https://www.vyvod-iz-zapoya-rostov12.ru]наркология вывод из запоя ростов[/url] .
капельница от запоя на дому [url=www.kapelnica-ot-zapoya-kolomna11.ru]капельница от запоя на дому[/url] .
Sahabet Casino’da yeni oyuncular, en buyuk hos geldin bonuslar?n? alarak oyuna kat?labilir. En sevilen slotlar Sahabet’te buyuk kazanclar sunuyor. Sans?n?z? simdi deneyin ve 500% bonus elde edin. [url=https://t.me/sahabet1194/]Sahabet[/url], buyuk oduller sunan kumarhane olarak dikkat cekiyor.
снятие ломки цены [url=http://www.snyatie-lomki-narkolog11.ru]снятие ломки цены[/url] .
вызвать наркологическую помощь [url=https://skoraya-narkologicheskaya-pomoshch11.ru/]skoraya-narkologicheskaya-pomoshch11.ru[/url] .
levandovski robert [url=https://www.robert-lewandowski-az.com]https://www.robert-lewandowski-az.com/[/url] fc barcelona tickets http://robert-lewandowski-az.com/ .
virgil van dijk 2019 [url=http://virgil-van-dijk-az.com]http://virgil-van-dijk-az.com[/url] aston villa liverpool virgil-van-dijk-az.com .
ретрит туры сочи https://ретриты.рф
вывод из запоя петербург [url=http://vyvod-iz-zapoya-v-sankt-peterburge11.ru]вывод из запоя петербург[/url] .
view and download [url=www.anon-inst.com/]view and download[/url] .
Pin up casino official Slot pick up casino website – login and play online
neymar 5 [url=http://neymar-az.com]neymar-az.com[/url] nike mercurial vapor 13 academy tf njr jogo prismatico http://www.neymar-az.com/ .
kakashop [url=https://kaka.com.az]rikardo kaka[/url] tickets ac milan atalanta rikardo kaka .
El comercio de opciones binarias es una forma de inversion en la que los inversores predicen si el valor de un activo subira o bajara. Plataformas como Quotex ofrecen una plataforma intuitiva para el trading de opciones binarias. Utilizando indicadores y analisis, es posible aumentar las ganancias en el trading de opciones binarias. Opciones binarias trading se ha vuelto frecuente en paises como Mexico y en todo el mundo.
broker para opciones binarias [url=http://themagicoption.com/]cfd opciones binarias[/url] .
Ретрит http://ретриты.рф международное обозначение времяпрепровождения, посвящённого духовной практике. Ретриты бывают уединённые и коллективные; на коллективных чаще всего проводится обучение практике медитации.
Comment verifier la pertinence du code promo 1xbet?
Pour verifier la pertinence du промокод на ставку 1хбет бесплатно бесплатную сегодня, le joueur doit se connecter a son compte. En utilisant les parametres, vous devez entrer dans la section «verifier le code promotionnel et entrer la combinaison copiee.
наркологическая скорая [url=https://skoraya-narkologicheskaya-pomoshch15.ru/]наркологическая скорая[/url] .
неотложная наркологическая помощь в москве [url=https://skoraya-narkologicheskaya-pomoshch16.ru/]https://skoraya-narkologicheskaya-pomoshch16.ru/[/url] .
заработок онлайн [url=www.kak-zarabotat-v-internete11.ru]заработок онлайн[/url] .
ручные листогибы [url=stanki-a.ru ]ручные листогибы[/url] .
Промокод для регистрации Фонбет https://autoritm-service.ru/inc/pages/aktualnuy_promokod_fonbet_pri_registracii.html
Использование промокода при регистрации на Фонбет позволяет новым пользователям получить приветственные бонусы и бесплатные ставки. Примером такого промокода является ‘GIFT200’, который предоставляет бонусные ставки для новых игроков. Ввод промокода в специальное поле при регистрации активирует бонусные предложения, что помогает новым игрокам успешно начать игру и увеличить свои шансы на выигрыш.
http mostbet com [url=http://www.casino.mostbet-aviator.com.az]http://www.casino.mostbet-aviator.com.az[/url] mbappe nba casino mostbet aviator .
Qu’est-ce qui donne au joueur la verification dans 1xbet?
La verification est une procedure obligatoire pour les clients du bookmaker промокод 1хбет на сегодня бесплатно без депозита. La procedure prevoit la verification des donnees personnelles du client pour la conformite avec les donnees reelles qui sont presentees sur la carte d’identite.
бизнесы [url=https://biznes-idei11.ru/]https://biznes-idei11.ru/[/url] .
поролон мебельный виды [url=http://porolon-mebelnyj.ru/]http://porolon-mebelnyj.ru/[/url] .
идеи для открытия бизнеса [url=biznes-idei12.ru]biznes-idei12.ru[/url] .
El comercio de opciones binarias es una modalidad de trading en la que los inversores apuestan si el valor de un activo subira o bajara. Plataformas como Quotex ofrecen acceso a mercados para el trading de opciones binarias. Con conocimientos y herramientas, es posible maximizar los beneficios en el trading de opciones binarias. Opciones binarias trading se ha vuelto frecuente en paises como Mexico y en todo el mundo.
quotex una plataforma innovadora para la inversion en linea [url=http://themagicoption.com/]libros de opciones binarias[/url] .
рулонная штора с электроприводом [url=https://rulonnye-shtory-s-elektroprivodom.ru]рулонная штора с электроприводом[/url] .
карниз с приводом [url=elektrokarniz2.ru]карниз с приводом[/url] .
Увлекательное казино Cryptoboss ждет вас, станьте победителем вместе с королем криптовалютных игр, уникальный опыт в мире криптовалютного азарта, попробуйте удачу в казино Cryptoboss, стать криптобоссом легко с Cryptoboss casino, играйте на крипто-максимуме вместе с Cryptoboss, будьте боссом в мире криптовалютных игр с Cryptoboss casino, Cryptoboss casino – ваша площадка для побед, удивительные возможности в казино от Cryptoboss, Cryptoboss casino – ваш путь к криптовалютному успеху, встречайте новый уровень криптовалютных ставок в Cryptoboss casino, Cryptoboss casino – ваш путеводитель в мире криптовалютных игр, играйте и побеждайте с Cryptoboss casino, следуйте за лидером с Cryptoboss casino, попробуйте удачу вместе с Cryptoboss, Cryptoboss casino – гарант криптовалютных побед.
сайт cryptoboss casino [url=https://ikea-expert.ru/]сайт cryptoboss casino[/url] .
листогиб [url=http://stanki-a.ru /]листогиб[/url] .
instagram profile without [url=http://isinstafree.com]instagram profile without[/url] .
1xBet
1xBet offers specific promo codes for sports betting that provide free bets, enhanced odds, or cashback on losses. These codes are popular among sports enthusiasts who want to maximize their betting potential on various sports events.
Встречайте криптовалютного босса в казино, станьте победителем вместе с королем криптовалютных игр, уникальный опыт в мире криптовалютного азарта, выиграйте криптовалюты в казино от Cryptoboss, стать криптобоссом легко с Cryptoboss casino, захватывающий азарт с криптовалютным боссом, ипотека доверия с Cryptoboss casino, Cryptoboss casino – ваша площадка для побед, взломай банк с Cryptoboss casino, играйте и выигрывайте с лучшим криптовалютным казино, революция в криптовалютных играх с Cryptoboss casino, Cryptoboss casino – ваш путеводитель в мире криптовалютных игр, играйте и побеждайте с Cryptoboss casino, встречайте криптовалютного короля в казино, выигрывайте крупные суммы с Cryptoboss casino, присоединяйтесь к лидерам в мире криптовалютных игр с Cryptoboss casino.
скачать cryptoboss [url=https://ikea-expert.ru/]cryptoboss casino криптобосс[/url] .
Заблокировано? Не беда! Находите актуальные зеркала Cryptoboss Casino здесь, играйте без проблем!
Попробуйте свою удачу на новом зеркале Cryptoboss Casino, бесперебойный доступ гарантированы.
Официальное зеркало Cryptoboss Casino ждет вас прямо сейчас, не упустите другие варианты!
Новости и выигрыши ждут вас на зеркале Cryptoboss Casino, играйте и выигрывайте!
Самое надежное зеркало Cryptoboss Casino только у нас, получайте удовольствие без лишних хлопот!
криптобосс зеркало рабочее [url=https://motorola-profi.ru/]криптобосс зеркало cryptoboss ru casino[/url] .
Qu’est-ce qui donne au joueur la verification dans 1xbet?
La verification est une procedure obligatoire pour les clients du bookmaker 1xBet Republique du Congo. La procedure prevoit la verification des donnees personnelles du client pour la conformite avec les donnees reelles qui sont presentees sur la carte d’identite.
barcelona bayern lewandowski [url=http://www.lewandowski.com.az/]www.lewandowski.com.az[/url] barca real tickets http://lewandowski.com.az/ .
мелкий бизнес идеи [url=https://biznes-idei13.ru]https://biznes-idei13.ru[/url] .
Аптечка Онлайн – это уникальный справочник, предоставляющий отзывы о медикаментах, таких как Адаптол, и многих других. На сайте Аптечка Онлайн пользователи могут найти подробной информацией о таких средствах, как Урсодез, показаниях и противопоказаниях и сравнить различные медикаменты для профилактики.
Аптечка Онлайн также предоставляет пользователям возможность ознакомиться с мнениями о различных лекарственных средствах, таких как Адаптол. Эти отзывы помогают сделать выбор, какое лекарство будет подходящим в конкретном случае. Кроме того, на ресурсе доступно сравнение заменителей, что облегчает выбор более выгодных вариантов.
Благодаря удобной навигации на сайте Аптечка Онлайн, пользователи могут быстро найти нужную информацию, будь то подробная инструкция или противопоказания. Это делает ресурс полезным помощником для тех, кто заботится о здоровье близких.
[b]Aptechka Online[/b] предлагает подробные инструкции по применению препаратов, таких как Ксефокам, что помогает читателям лучше понять, как использовать средства для профилактики различных состояний. На сайте также можно найти актуальные данные о противопоказаниях и возможных реакциях, что важно для безопасного применения.
Дополнительно, сайт Аптечка Онлайн предлагает рекомендации по сравнению аналогов, таких как Урсосан. Это помогает пользователям принимать осознанный выбор и находить более доступные варианты лекарственных препаратов, не теряя при этом в качестве.
услуги эскорта москва для мужчин эскорт услуги парни москвы
москва работа эскорт услуги девушки для эскорт услуг москва
Встречайте криптовалютного босса в казино, добейтесь успеха вместе с лучшим криптовалютным казино, криптовалютные ставки для настоящих боссов, выиграйте криптовалюты в казино от Cryptoboss, выиграть криптовалюты легко в Cryptoboss casino, играйте на крипто-максимуме вместе с Cryptoboss, ипотека доверия с Cryptoboss casino, Cryptoboss casino – ваша площадка для побед, качественный сервис и безопасность с Cryptoboss casino, Cryptoboss casino – ваш путь к криптовалютному успеху, встречайте новый уровень криптовалютных ставок в Cryptoboss casino, большие выигрыши ждут вас в Cryptoboss casino, играйте и побеждайте с Cryptoboss casino, Cryptoboss casino – выбор тех, кто ценит качество, попробуйте удачу вместе с Cryptoboss, присоединяйтесь к лидерам в мире криптовалютных игр с Cryptoboss casino.
криптобосс сайт [url=https://ikea-expert.ru/]криптобосс hds5[/url] .
Вас ждут захватывающие игры на сайте Cryptoboss Casino
cryptoboss официальный сайт [url=https://101optovik.ru/]cryptoboss casino официальный сайт[/url] .
эскорт женский услуги москве эскорт услуги мальчики в москве
эскорт услуги москвы эскорт услуги парни москва гей
Кодирование от алкоголизма [url=https://www.kodirovanie-ot-alkoholizma-v-almaty.kz]Кодирование от алкоголизма [/url] .
поиск телефона по номеру телефона через спутник [url=www.poisk-po-nomery.ru]поиск телефона по номеру телефона через спутник[/url] .
Присоединяйтесь к cryptoboss casino сегодня и получите доступ к лучшим играм, Проведите регистрацию на cryptoboss casino за несколько минут, Оформите аккаунт на cryptoboss casino и начните играть в любимые слоты, Cryptoboss casino ждет своих новых игроков – присоединяйтесь, Регистрация на cryptoboss casino – ваш первый шаг к увлекательному миру азартных игр, Cryptoboss casino приглашает вас зарегистрироваться и насладиться игровым процессом, Cryptoboss casino рад приветствовать новых игроков – зарегистрируйтесь прямо сейчас, Присоединяйтесь к cryptoboss casino и начните выигрывать большие суммы денег, Cryptoboss casino готов принять вас – пройдите регистрацию и начните играть, Регистрация на cryptoboss casino – ваш билет в мир азартных развлечений, Присоединяйтесь к cryptoboss casino и получите шанс на крупный выигрыш, Cryptoboss casino: регистрация – быстро, просто, надежно, Пройдите регистрацию на cryptoboss casino и получите шанс выиграть крупный джекпот, Уникальные бонусы ждут вас после регистрации на cryptoboss casino, Cryptoboss casino рад приветствовать новых игроков – присоединяйтесь сейчас, Cryptoboss casino приглашает вас стать его частью – зарегистрируйтесь и начните играть.
cryptoboss регистрация hds5 [url=https://auto-adventures.ru/]криптобосс промокод при регистрации[/url] .
лаки джет сигналы lucky jet регистрация
Заблокировано? Не беда! Находите актуальные зеркала Cryptoboss Casino здесь, играйте без проблем!
Попробуйте свою удачу на новом зеркале Cryptoboss Casino, полный контроль гарантированы.
Самое популярное зеркало Cryptoboss Casino ждет вас прямо сейчас, пропустите другие варианты!
Проводите время с удовольствием на зеркале Cryptoboss Casino!, забирайте джекпот!
Не забудьте использовать зеркало Cryptoboss Casino для безопасной игры, получайте удовольствие без лишних хлопот!
криптобосс зеркало рабочее [url=https://motorola-profi.ru/]cryptoboss зеркало[/url] .
ручные листогибы [url=https://stanki-a.ru/]ручные листогибы[/url] .
Играйте бесплатно в Cryptoboss Casino с бездепозитным бонусом, не упустите возможность!
Заработайте крупный выигрыш без вложений в Cryptoboss Casino – отличный способ испытать свою удачу.
Cryptoboss Casino радует новыми бездепозитными бонусами – лучший способ испытать удачу.
Уникальное предложение от Cryptoboss Casino для новых игроков – играйте и выигрывайте без риска.
Cryptoboss Casino радует бездепозитными бонусами для всех – возможность выиграть крупный джекпот без вложений.
Уникальные возможности для игры без вложений в Cryptoboss Casino – лучший способ испытать свою удачу.
Используйте уникальное предложение от Cryptoboss Casino для новичков – шикарная возможность заработать без вложений.
Играйте без вложений и выигрывайте настоящие деньги в Cryptoboss Casino – возможно, это ваш шанс стать миллионером.
Получите шанс выиграть крупный джекпот без вложений в Cryptoboss Casino – возможность заработать крупный выигрыш бесплатно.
криптобосс промокод на бонус при регистрации [url=https://pitaka-trade.ru/]криптобосс бонус[/url] .
Крутые игровые автоматы в казино Cryptoboss, которые вас увлекут на целый вечер.
Играйте на деньги в автоматах Cryptoboss Casino, для любителей крупных выигрышей.
Не упустите шанс выиграть крупный джекпот в казино Cryptoboss, для тех, кто ищет адреналин.
Увлекательные автоматы ждут вас на сайте Cryptoboss Casino, для азартных игроков.
Играйте в игровые слоты в казино Cryptoboss, для любителей азарта.
Играйте на популярных слотах в Cryptoboss Casino, где выигрыши ждут каждого.
Наслаждайтесь игрой в автоматы на сайте Cryptoboss Casino, для тех, кто мечтает о крупном выигрыше.
На сайте Cryptoboss ждут увлекательные слоты, для любителей азартных игр.
Почувствуйте волнение от игры в казино Cryptoboss на автоматах, которые покорят вас своими возможностями.
Лучшие слоты на сайте Cryptoboss ждут вас, чтобы испытать настоящий азарт.
Не пропустите уникальные предложения для игры в казино Cryptoboss на автоматах, для азартных игроков.
Попробуйте свою удачу в казино Cryptoboss на увлекательных автоматах, для ценителей азарта.
Играйте в казино Cryptoboss и выигрывайте крупные суммы, для тех, кто мечтает о крупном выигрыше.
Играйте в казино Cryptoboss на лучших автоматах, для азартных игроков.
Играйте на деньги в казино Cryptoboss на лучших автоматах, для тех, кто мечтает о крупном выигрыше.
Попробуйте свою удачу в казино Cryptoboss, для тех, кто ищет азарт.
Эмоции бурлят в крови, играя в казино Cryptoboss на автоматах, где каждый может испыт
cryptoboss casino игровые автоматы [url=https://zasport.su/]cryptoboss casino автоматы[/url] .
blacksprut официальный сайт https://dark-blacksprut.com
Текущий курс валют в Казахстане: актуальная информация
Где проверить курс валют в Казахстане
Какие валюты выгодно менять в Казахстане
На сколько выгодно менять валюту в Казахстане
Секреты выгодного обмена валюты в Казахстане
курс доллара на сегодня в алматы [url=https://kursy-valut-online.kz/]курс российского рубля в казахстане[/url] .
Лечение от мефедрона в Казахстане [url=https://narcologiya-kazakhstan.kz/]https://narcologiya-kazakhstan.kz/[/url] .
pin up 2000 [url=https://pin-up.prpc.ru]https://pin-up.prpc.ru[/url] онлайн казино с бонусом за регистрацию http://www.pin-up.prpc.ru .
пин ап официальный сайт играть [url=http://www.pinup-kz.games-tv.ru]pinup-kz.games-tv.ru[/url] онлайн казино бонусы https://www.pinup-kz.games-tv.ru/ .
pin up 200 [url=https://pin-up-kz.belproc.ru]https://pin-up-kz.belproc.ru[/url] xcasino http://www.pin-up-kz.belproc.ru .
Присоединяйтесь к Cryptoboss Casino и покоряйте новые вершины
cryptoboss официальный [url=https://101optovik.ru/]cryptoboss casino официальный зеркало[/url] .
Присоединяйтесь к cryptoboss casino сегодня и получите доступ к лучшим играм, Cryptoboss casino: регистрация проходит быстро и просто, Играйте с удовольствием после регистрации на cryptoboss casino, Cryptoboss casino ждет своих новых игроков – присоединяйтесь, Регистрация на cryptoboss casino – ваш первый шаг к увлекательному миру азартных игр, Не упустите возможность зарегистрироваться на cryptoboss casino и выиграть крупный приз, Пройдите регистрацию на cryptoboss casino и откройте доступ к лучшим играм, Зарегистрируйтесь на cryptoboss casino и окунитесь в захватывающий мир азартных игр, Не упустите шанс зарегистрироваться на cryptoboss casino и получить эксклюзивные бонусы, Регистрация на cryptoboss casino – ваш билет в мир азартных развлечений, Cryptoboss casino приглашает вас зарегистрироваться и испытать удачу, Cryptoboss casino: регистрация – быстро, просто, надежно, Пройдите регистрацию на cryptoboss casino и получите шанс выиграть крупный джекпот, Присоединяйтесь к cryptoboss casino и станьте обладателем эксклюзивных привилегий, Не упустите возможность зарегистрироваться на cryptoboss casino и испытать азартные ощущения, Регистрация на cryptoboss casino – ваш шанс на удачу.
cryptoboss регистрация [url=https://auto-adventures.ru/]cryptoboss casino регистрация на сайте обзор[/url] .
Не упустите шанс, переходите на зеркало Cryptoboss Casino сейчас, выигрывайте без проблем!
Новое зеркало Cryptoboss Casino доступно для всех!, надежная связь гарантированы.
Лучшее зеркало Cryptoboss Casino ждет вас прямо сейчас, пропустите другие варианты!
Новости и выигрыши ждут вас на зеркале Cryptoboss Casino, не пропустите свой шанс!
Не забудьте использовать зеркало Cryptoboss Casino для безопасной игры, зарабатывайте крупные суммы без лишних хлопот!
криптобосс официальное зеркало [url=https://motorola-profi.ru/]криптобосс casino зеркало[/url] .
Крутые игровые автоматы в казино Cryptoboss, для азартных игроков.
Попробуйте свою удачу на автоматах в казино Cryptoboss, для любителей крупных выигрышей.
Не упустите шанс выиграть крупный джекпот в казино Cryptoboss, для тех, кто ищет адреналин.
Увлекательные автоматы ждут вас на сайте Cryptoboss Casino, для тех, кто мечтает выиграть крупный приз.
Получайте удовольствие от игры в автоматы на сайте Cryptoboss Casino, для любителей азарта.
Играйте на популярных слотах в Cryptoboss Casino, где выигрыши ждут каждого.
Наслаждайтесь игрой в автоматы на сайте Cryptoboss Casino, для азартных игроков.
На сайте Cryptoboss ждут увлекательные слоты, для любителей азартных игр.
Почувствуйте волнение от игры в казино Cryptoboss на автоматах, которые покорят вас своими возможностями.
Проведите время с пользой, играя в автоматы на сайте Cryptoboss Casino, чтобы испытать настоящий азарт.
Не пропустите уникальные предложения для игры в казино Cryptoboss на автоматах, где вас ждут крупные выигрыши.
Попробуйте свою удачу в казино Cryptoboss на увлекательных автоматах, для тех, кто ищет адреналин.
Увлекательные слоты на сайте Cryptoboss ждут вас, для тех, кто мечтает о крупном выигрыше.
Игровые автоматы в казино Cryptoboss, которые порадуют вас выигрышами.
Лучшие игровые автоматы на сайте Cryptoboss, для любителей азарта.
Играйте на популярных слотах на сайте Cryptoboss Casino, для любителей крупных выигрышей.
Лучшие игровые автоматы на сайте Cryptoboss, где каждый может испыт
cryptoboss casino автоматы [url=https://zasport.su/]криптобосс игровые автоматы на деньги[/url] .
4rabet casino promo code: A general promo code for the year 2024, offering bonuses for new and existing users. This can be used for sports betting or casino games on 4rabet.
Обновленный курс валют в Казахстане
Способы отслеживания курса валют в Казахстане
Доллар, евро, рубль: актуальный курс в Казахстане
Прогноз курса валют в Казахстане
Точки обмена валюты в Казахстане
курс доллар на тенге [url=https://kursy-valut-online.kz/]курс тенге рубль[/url] .
1xBet
Promocodes of 1xBet are alphanumeric strings that unlock various bonuses on the platform. These codes can be used during registration or deposit to claim bonuses like free bets, deposit matches, or free spins.
порно аниме [url=https://www.admin4web.ru]порно аниме[/url] .
Современные технологии для вашего ребенка
лучшие коляски люльки для новорожденных [url=https://koljaska-ljulka.ru/]https://koljaska-ljulka.ru/[/url] .
Сравнение кровельных материалов и их преимущества
отделочные материалы [url=https://stroitelnye-materialy-optom.ru/]https://stroitelnye-materialy-optom.ru/[/url] .
watch instagram stories [url=https://www.anonstoryinst.com]watch instagram stories[/url] .
Советы по выбору черного плинтуса для дома, Плюсы и минусы черного плинтуса, Топ-10 дизайнерских идей с черным плинтусом, Эффективные способы чистки черного плинтуса, Советы по подбору черного плинтуса для дома, Зачем выбирать черный плинтус для интерьера, Современные тренды в использовании черного плинтуса, Текстуры черного плинтуса: как выбрать подходящую, Как добавить черный плинтус в классическую обстановку, Как использовать черный плинтус для создания атмосферы, Тенденции использования черного плинтуса в современном дизайне, Какое влияние оказывает черный плинтус на общий вид комнаты, Черный плинтус: отличие от других видов плинтусов, Преимущества использования черного плинтуса на стенах, Идеи использования черного плинтуса на кухне, Чем привлекательны черные оттенки в спальном интерьере, Черный плинтус в гостиной: респектабельность и стиль, Черный плинтус: шикарный акцент в ванной комнате, Черный плинтус: творческий подход к оформлению
плинтус напольный черный [url=https://plintus-aljuminievyj-chernyj.ru/]плинтус напольный черный[/url] .
Смешные видео на разные темы
Поднимите себе настроение!
Прикольные картинки http://prikoly-shutki.ru/kartinki-prikolnye Что такое мемы.
охрана техническое обслуживание росгвардия [url=trevozhnaya-knopka-rosgvardii.ru]trevozhnaya-knopka-rosgvardii.ru[/url] .
фургон sollers фургон sollers
Как поднять настроение с помошью мемов. прикольные анекдоты
http://www.tuningevo.club/newforum/index.php?showuser=87488
Лучшие предложения по аренде квартир на сутки|Выберите лучшее жилье на короткий срок|Квартиры на сутки в центре города|Резервируйте жилье на сутки онлайн|Эксклюзивные предложения аренды квартир на короткий срок|Идеальные квартиры на сутки для вашего отдыха|Привлекательные варианты аренды квартир на сутки|Выберите идеальное жилье на короткий срок|Уникальные апартаменты на сутки для вашего отдыха|Выберите комфортное жилье на короткий срок|Бронируйте квартиры на сутки по выгодным ценам|Идеальные предложения аренды жилья на сутки|Выберите лучшее жилье на короткое проживание|Выбор квартир на короткий срок для вашего отдыха|Идеальные варианты жилья для вашего отдыха|Бронирование квартир на сутки без комиссии|Уютные квартиры на короткий срок по доступной стоимости|Привлекательные квартиры на сутки для вашего отпуска|Выбор идеальных квартир для короткого проживания|Уютные жилье на сутки по лучшим ценам
квартира в гомеле посуточно [url=https://gomelsutochno.ru/]квартира в гомеле посуточно[/url] .
Кракен сайт – это онлайн-площадка, работающая в скрытых сетях интернета, где пользователи могут покупать и продавать различные виды наркотиков. Для доступа к Кракен даркнет необходимо использовать специальное программное обеспечение, позволяющее обходить блокировки и обеспечивающее анонимность пользователей.
Букмекерская контора Мелбет предлагает хорошо организованный сервис для пользования услугами оператора. Разнообразие ставок с неплохими коэффициентами сопровождается бонусными программами, нацеленными на поддержание интересов клиентов. Получение бонусов от букмекера позволяет получить новый безболезненный опыт на ставках, что особенно важно для новичков промокод день рождения. Однако предполагаем, что снижение требований по отыгрышу бонусов сделали бы букмекера еще привлекательнее для игроков.
лучшие капперы мира [url=https://www.luchshie-kappery-rossii.ru]лучшие капперы мира[/url] .
wall clocks best clocks coldplay
лучшие капперы россии [url=https://www.luchshie-kappery-rossii11.ru]лучшие капперы россии[/url] .
Бетон от надежного производителя в Нижнем Новгороде, Широкий выбор бетонных смесей в Нижнем Новгороде, с высоким качеством, Бетон от надежных поставщиков в Нижнем Новгороде, по выгодной цене, с гарантией качества, Заказать специальный бетон в Нижнем Новгороде, Купить готовый бетон в Нижнем Новгороде: широкий ассортимент, по доступной цене
купить бетон нижний новгород [url=https://1beton-52.ru/]купить бетон нижний новгород[/url] .
Сайт о биодобавках https://биодобавки.рф подробная информация о видах добавок, их действии и пользе. Рекомендации по выбору для поддержки здоровья на основе актуальных исследований.
Сайт о биодобавках https://биодобавки.рф предлагает проверенную информацию о натуральных добавках для здоровья. Узнайте, как выбрать подходящие средства для улучшения иммунитета, повышения энергии и поддержания активного образа жизни. Подробные описания и советы помогут сделать осознанный выбор.
Как поднять настроение с помошью смешных картинок. Ржачные мемы.
http://centercep.ru/phpbb/profile.php?mode=viewprofile&u=55048&sid=7f9097c99ee492be0d28d72ebff8b6e1
taif моторное масло официальный сайт [url=https://www.e-taif.ru]https://www.e-taif.ru[/url] .
Сайт предоставляет информацию о биодобавках http://биодобавки.рф состав, польза и рекомендации по применению. Здесь вы найдёте обзоры эффективных добавок для улучшения здоровья, иммунитета и энергии на основе научных данных и экспертных мнений.
1xBet
1xBet offers specific promo codes for casino players that provide free spins, deposit bonuses, or cashback on losses. These codes can be used in the casino section of the site to enhance the gaming experience.
Идеальные образы в тактичной одежде, тактичные наряды.
Топ-10 брендов тактичной одежды, для модных мужчин и женщин.
Тактичные наряды для повседневной носки, которые не выйдут из моды.
Как сделать акцент на тактичной одежде, для добавления индивидуальности.
Секреты удачного выбора тактичной одежды, чтобы быть в центре внимания.
одяг тактичний військовий [url=https://alphakit.com.ua/]https://alphakit.com.ua/[/url] .
В Мелбет промокод — это уникальная комбинация из цифр и букв. Он может использоваться в самых разных ситуациях. Чаще всего применяется в Мелбет промокод при регистрации, чтобы привлечь новых игроков. Однако, он может давать бесплатную ставку и другие бонусы, которых очень много в данной букмекерской конторе. Этот материал расскажет о том, что из себя представляет и что дает промокод на бесплатную ставку в. Промокод для Мелбет можно получить за участие в каких-либо активностях букмекерской конторы Мелбет. Например, уникальный код компания присылает на день рождения в виде подарка своим клиентам. Помимо этого, можно ввести в поисковике «Как получить промокод на Мелбет?» и найти тематические сайты, где постоянно публикуются актуальные комбинации цифр и букв. Букмекер часто распространяет свои promo коды через партнеров, а также некоторые игроки сами активно делятся ими в сети.
Сайт предоставляет информацию о биодобавках биодобавки.рф состав, польза и рекомендации по применению. Здесь вы найдёте обзоры эффективных добавок для улучшения здоровья, иммунитета и энергии на основе научных данных и экспертных мнений.
real vinicius jr [url=http://vinicius-junior-az.com]vinicius-junior-az.com[/url] real madrid clothing http://www.vinicius-junior-az.com .
москва проститутки [url=mgtimez.ru]москва проститутки[/url] .
Смешные анекдоты. История анекдотов.
Сервисный центр предлагает чистка системы охлаждения asus r1e замена батареи asus r1e
Бесплатный промокод мелбет ищет каждый потенциальный клиент компании. Почему? Мало кто откажется от щедрой приветственной награды, позволяющей увеличить сумму первого депозита, заработав до ?9100 бонуса (с 24 апреля бонус увеличился до 10 400). Промокоды – это маркетинговый инструмент, с помощью которого рекламные партнеры букмекера привлекают новых бетторов. Поэтому в современной практике сам букмекер редко распространяет коды, за исключением флагманских акций или раздачи купонов в рамках специальных ивентов. Не все бонусы предполагают наличие рекламного кода. Для активации большинства из них достаточно просто пополнить счет или делать ставки на спорт, получая за это баллы активности. В последующем есть возможность в рамках программы лояльности БК «Мелбет» обменивать баллы на коды для бесплатных ставок (фрибеты) или на реальные денежные средства. Раздобыть промокод Melbet Вы всегда сможете на нашем сайте. При этом Вы можете быть уверенными в том, что это именно актуальное предложение. Также рекомендуем подписаться на информационную рассылку БК, где компания при помощи SMS и почтовых уведомлений держит в курсе событий любителей ставок.
Как поддерживать хорошее настроение с помощью забавных приколов
вертушка на входе [url=https://for-gate.ru]вертушка на входе[/url] .
instagram anonymous story viewer [url=www.storyanonviewer.com/]instagram anonymous story viewer[/url] .
скуд стоимость [url=https://northern-computers.ru/]northern-computers.ru[/url] .
выкуп кредитных автомобилей выкуп кредитных авто
1 win ru [url=https://1win.onedivision.ru]1win.onedivision.ru[/url] игровые автоматы онлайн 1win .
Indian porn https://desiporn.one in Hindi. Only high-quality porn videos, convenient search and regular updates.
Porn videos https://thetittyfuck.com watch online for free. A selection of high-quality porn videos, a collection of sex videos
кодирование от алкоголизма последствия [url=http://xn—-7sbbfcijbwcrwtjcjarh1adw8u.xn--p1ai]кодирование от алкоголизма последствия[/url] .
турникет стоимость [url=http://sigmavision.ru]http://sigmavision.ru[/url] .
лечение пивного алкоголизма [url=https://xn—–7kcablenaafvie2ajgchok2abjaz3cd3a1k2h.xn--p1ai/]лечение пивного алкоголизма[/url] .
1x Bet Promocode https://idematapp.com/wp-content/pages/1xbet_promo_codes_free_bonus_offers.html
A 1x Bet promocode is an alphanumeric code that unlocks various bonuses on the 1xBet platform. These codes are often distributed through promotions, social media, or affiliate sites, and can be entered during registration or deposit.
продвижение товаров на вайлдберриз услуги продвижение на wildberries цена
Федерация – это проводник в мир покупки запрещенных товаров, можно купить гашиш, купить мефедрон, купить кокаин, купить меф, купить экстази, купить альфа пвп, купить гаш в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
Лучшие анекдоты
Подними настроение
Лучшие онлайн казино в одном месте
https://www.jobscity.net/pls/jobs/companyprofile?comid=Y0wMO
betstars free bet code: A bet that comes with a promotional offer, such as a free bet or enhanced odds, often tied to a specific event or promotion period.
вывод из запоя на дому в ростове [url=https://vyvod-iz-zapoya-rostov15.ru/]вывод из запоя на дому в ростове[/url] .
вывод из запоя цены на дому ростов [url=https://vyvod-iz-zapoya-rostov16.ru]вывод из запоя цены на дому ростов[/url] .
игровые автоматы gates of olympus гейтс оф олимпус играть на деньги
Лучшие анекдоты
Подними себе настроение
рабочий промокод мостбет 2024 рабочий промокод AZ3202 мостбет
вывод. из. запоя. анонимно. ростов. [url=http://vyvod-iz-zapoya-rostov18.ru/]вывод. из. запоя. анонимно. ростов.[/url] .
нарколог на дом краснодар [url=http://www.narkolog-na-dom-krasnodar15.ru]нарколог на дом краснодар[/url] .
Online casino https://bitbird.biz/2024/10/06/revolutionizing-online-betting-1win-benin with high bonuses, roulette and slots, instant payouts. Register on the official mirror.
вывод из запоя цены ростов-на-дону [url=http://www.vyvod-iz-zapoya-rostov17.ru]http://www.vyvod-iz-zapoya-rostov17.ru[/url] .
lucky jet 1win lucky jet 1win
Авиатор бонусы Авиатор онлайн
helium balloons inexpensively buy an apartment in a new building inexpensively
ржачные картинки. Как они появились.
Secure cross-border payments: the key to global business success, How to safeguard your transactions with secure cross-border payments, Maximizing security with cross-border payment systems, Top reasons to prioritize secure cross-border payments, How to choose the right secure cross-border payment provider, The evolution of secure cross-border payments in a global economy, The role of technology in secure cross-border payments, Improving efficiency with secure cross-border payment platforms, How to protect your business with secure cross-border payment methods, Understanding the importance of secure cross-border payments
complying with international payment regulations [url=https://telegra.ph/how-to-make-secure-international-payments-online-and-protect-your-global-transactions-10-09/]secure international payments for e-commerce[/url] .
1x Bet Promo Cod https://idematapp.com/wp-content/pages/1xbet_promo_codes_free_bonus_offers.html
1x Bet promo cod is a common misspelling of 1xBet promo code. These codes unlock various bonuses on the 1xBet platform, such as free bets, deposit matches, or free spins.
Casino and slot https://penopopa.ru/2024/10/06/master-betting-with-1win-uganda machines online. Play slot machines with bonus, casino for money. Registration and login to the working mirror
Free online https://thetranny.com porn videos and movies. Only girls with dicks. On our site there are trans girls for every taste!
вывод из запоя краснодар на дому [url=vyvod-iz-zapoya-krasnodar15.ru]вывод из запоя краснодар на дому [/url] .
вызов нарколога на дом круглосуточно [url=http://narkolog-na-dom-krasnodar17.ru/]http://narkolog-na-dom-krasnodar17.ru/[/url] .
вызов нарколога на дом круглосуточно [url=https://www.narkolog-na-dom-krasnodar16.ru]https://www.narkolog-na-dom-krasnodar16.ru[/url] .
Porn video https://zeenite.com watch online from pages for free in FullHD quality. Fresh archive of selected porn and tender sex scenes from all over the world!
Прикольные пошлые анекдоты.
Вызов сантехника https://santekhnik-moskva.blogspot.com/p/v-moskve.html на дом в Москве и Московской области в удобное для вас время. Сантехнические работы любой сложности, от ремонта унитаза, устранение засора, до замены труб.
вывод из запоя с выездом краснодар [url=https://vyvod-iz-zapoya-krasnodar16.ru]вывод из запоя с выездом краснодар[/url] .
вывод из запоя на дому похмельная [url=vyvod-iz-zapoya-ekaterinburg14.ru]вывод из запоя на дому похмельная[/url] .
вывод из запоя на дому краснодар цены [url=vyvod-iz-zapoya-krasnodar17.ru]вывод из запоя на дому краснодар цены[/url] .
выведение из запоя [url=vyvod-iz-zapoya-ekaterinburg15.ru]выведение из запоя[/url] .
вывод из запоя на дому екатеринбург [url=vyvod-iz-zapoya-ekaterinburg16.ru]вывод из запоя на дому екатеринбург[/url] .
экокожа купить москва [url=www.ekokozha-kupit11.ru/]экокожа купить москва[/url] .
Веселые анекдоты для взрослых https://ru.pinterest.com/vseshutochki/%D0%BF%D0%BE%D1%88%D0%BB%D1%8B%D0%B5-%D0%B0%D0%BD%D0%B5%D0%BA%D0%B4%D0%BE%D1%82%D1%8B/.
работа по казахстану [url=http://umicum.kz]работа по казахстану[/url] .
работа в алматы график 1/3 [url=https://www.trudvsem.kz]работа в алматы график 1/3[/url] .
Gay Boys Porn https://gay0day.com HD is the best gay porn tube to watch high definition videos of horny gay boys jerking, sucking their mates and fucking on webcam
Вавада казино – Играйте и выигрывайте столько, сколько хотите
http://rem.4nmv.ru/forum/profile.php?action=show&member=1676
Веселые приколы https://prikolyshutki.wordpress.com/2024/10/11/prikoly-umor/.
cs2 gambling csgo betting
csgo gamble cs2 gambling sites
топ онлайн казино [url=https://rating-casino-kz.org]топ 10 казино в Казахстане[/url] riobet casino https://rating-casino-kz.org .
франшиза купить [url=www.franshizy12.ru]франшиза купить[/url] .
список франшиз [url=https://franshizy11.ru/]список франшиз[/url] .
blacksprut
Смешные приколы, шутки и картинки http://anekdotshutka.ru.
mostbet скачать на айфон [url=https://mostbetua.kiev.ua]mostbetua kiev ua[/url] казино без верификации Мостбет Украина .
вывод из запоя в стационаре [url=www.vyvod-iz-zapoya-sochi16.ru]вывод из запоя в стационаре[/url] .
https://sudvgorode.ru/
вывод от запоя в стационаре сочи [url=https://vyvod-iz-zapoya-sochi15.ru]вывод от запоя в стационаре сочи[/url] .
csgo betting csgo gambling sites
https://sudvgorode.ru/sotrudnichestvo/
Веселые анекдоты https://teletype.in/@anekdoty/smeshnye-anekdoty.
музей анимации московский музей анимации
Платформа для ставок 1win с множеством событий и азартных игр. Удобный интерфейс, моментальные выплаты и привлекательные бонусы делают ставки ещё увлекательнее. Откройте мир азарта и выигрышей с надежным сервисом и постоянными акциями для пользователей.
купить диплом задним числом [url=https://orik-diploms.ru/]купить диплом задним числом[/url] .
музей анимации в москве измайлово музей анимации в измайловском кремле официальный
Обслуживание и запчасти для лазерных станков
Мы предоставляем полный комплекс услуг по техническому обслуживанию лазерных станков, а также поставляем оригинальные запчасти для их бесперебойной работы.
станок лазерной резки с чпу цена [url=https://lazernye-stanki.ru/]купить станок лазерной резки металла[/url] .
Команда мегааптека.ру включает высококвалифицированных специалистов, таких как Провизор Асанова Наталья Геннадьевна, которые помогают подобрать подходящие лекарства. Важно отметить и вклад врачей, таких как Кандидат фармацевтических наук Малеева Татьяна Леонидовна, которые обеспечивают надежные рекомендации. На сайте magapteka.ru можно получить консультацию провизоров.
Команда мегааптека.ру гордится нашими квалифицированными специалистами, включая опытного провизора Асанову Наталью, специалиста Рипатти Юлию, а также провизора Зотину Наталью Игоревну. Наш педиатр Богданова Кристина всегда готов оказать профессиональную помощь.
Алёна Подойницына, специалист Наталия Долгих, а также провизор Ибраева Екатерина Анатольевна обеспечивают высокий уровень обслуживания и консультаций.
Наши кандидаты фармацевтических наук: Шильникова Светлана Владимировна – опытные профессионалы, которые предоставляют консультации по поиску лекарств. Также с вами работает Анастасия Черенёва, оказывая поддержку клиентам на высоком уровне.
В мегаптека вы найдете лекарства с помощью нашей опытной команды специалистов.
Оптоволоконные лазерные станки для металлорезки
Предлагаем инновационные оптоволоконные лазерные станки, обеспечивающие точную резку металла с минимальными затратами на обслуживание.
лазерная резка металла оборудование с чпу цена [url=https://lazernye-stanki.ru/]лазер по металлу[/url] .
helium balloons with cheap delivery https://helium-balloon-price.com
Платформа 1вин предлагает широкий выбор спортивных событий, киберспорта и азартных игр. Пользователи получают высокие коэффициенты, быстрые выплаты и круглосуточную поддержку. Программа лояльности и бонусы делают игру выгоднее.
вывод из запоя в наркологическом стационаре [url=http://vyvod-iz-zapoya-sochi17.ru/]http://vyvod-iz-zapoya-sochi17.ru/[/url] .
Купить диплом магистра оказалось возможно, быстрое обучение и диплом на руки
wegug.in/blogs/3629/Где-купить-диплом-быстро-и-безопасно
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Обучение и поддержка операторов лазерных станков
Мы не только продаем лазерные станки, но и обучаем ваших сотрудников их эффективной эксплуатации, а также оказываем поддержку на всех этапах работы.
лазерная резка чпу [url=https://lazernye-stanki.ru/]оптоволоконный лазерный станок[/url] .
Смешные анекдоты http://anekdot-top.ru.
delivery of helium balloons to your home Dubai order balloons with home delivery Dubai
Лазерные станки с гарантией качества и надежности
Все лазерные станки, которые мы предлагаем, поставляются с гарантией качества и надежности. Мы сопровождаем клиента на всех этапах — от покупки до обслуживания.
лазерная резка листового металла [url=https://lazernye-stanki.ru/]оптоволоконный лазерный станок для резки металла[/url] .
resume of a production engineer https://engineer-builder-resume.com
Команда мегааптека.ру включает высококвалифицированных специалистов, таких как Провизор Асанова Наталья Геннадьевна, которые проводят поиск лекарств в аптеках. Важно отметить и опыт специалистов, таких как Провизор Подойницына Алёна Андреевна, которые способствуют качественному обслуживанию. На сайте magapteka.ru можно удобно искать лекарства и препараты.
Команда мегааптека.ру с гордостью представляет нашими квалифицированными специалистами, включая провизора Асанову Наталью Геннадьевну, провизора Рипатти Юлию Игоревну, а также провизора Зотину Наталью Игоревну. Наш врач Кристина Богданова всегда готов оказать профессиональную помощь.
Провизор Подойницына Алёна Андреевна, провизор Долгих Наталия Вадимовна, а также провизор Ибраева Екатерина Анатольевна обеспечивают высокий уровень обслуживания и консультаций.
Наши кандидаты фармацевтических наук: Малеева Татьяна Леонидовна – квалифицированные специалисты, которые предоставляют консультации по поиску лекарств. Также с вами работает Анастасия Черенёва, оказывая поддержку клиентам на высоком уровне.
В мега аптека вы найдете лекарства с помощью нашей опытной команды специалистов.
Официальная покупка диплома вуза с упрощенной программой обучения
вывод из запоя на дому ростов круглосуточно [url=vyvod-iz-zapoya-rostov115.ru]вывод из запоя на дому ростов круглосуточно[/url] .
Можно ли купить аттестат о среднем образовании? Основные рекомендации
freedomrp.getbb.ru/viewtopic.php?f=110&t=1086
Смешные приколы и анекдоты https://teletype.in/@anekdoty/prikoly-nastroenie.
франшизы 2024 [url=http://franshizy13.ru]франшизы 2024[/url] .
купить диплом в москве [url=https://arusak-diploms.ru/]купить диплом в москве[/url] .
Диплом вуза купить официально с упрощенным обучением в Москве
“Правильные перевозки” — это надежная транспортная компания, которая предоставляет услуги по перевозке грузов и вещей по всей России. Мы занимаемся доставкой личных вещей между городами и регионами страны. Благодаря профессиональному подходу и опыту наших специалистов, “транспортная компания правильные перевозки” гарантирует безопасность и сохранность вашего имущества на всех этапах транспортировки.
Для вашего удобства мы предлагаем услуги междугородных переездов с возможностью рассчитать стоимость и сроки онлайн. Независимо от того, нужен ли вам домашний переезд или перевозка личных вещей, наша команда обеспечивает высокий уровень сервиса и индивидуальный подход к каждому клиенту. Уточнить детали или заказать услугу вы можете по телефону 8 (800) 505-18-39 или 88005051839.
Компания предлагает доступные цены на перевозки, обеспечивая оперативную доставку в другой город. Наши специалисты профессионально занимаются домашними перевозками, минимизируя ваши затраты времени и средств. Обращайтесь к нам, и “транспортная компания правильные перевозки” сделает ваш переезд комфортным и безопасным.
Эксперт в сфере грузоперевозок | Надежность и профессионализм | Индивидуальный подход к каждому клиенту | Превосходное качество транспортных услуг | Безукоризненная репутация в сфере грузоперевозок | Профессиональный подход к каждому клиенту | Экономия времени и денег при заказе услуг | Эффективные решения для вашего бизнеса | Оптимальные условия и тарифы для клиентов | Идеальный выбор для вашего груза | Лучшее решение для вашего бизнеса | Безопасность и надежность при перевозках | Оптимизация логистики и транспортировки | Индивидуальный подход к каждому клиенту
Полезные советы по покупке диплома о высшем образовании без риска
где купить диплом инженера [url=https://russa-diploms.ru/]russa-diploms.ru[/url] .
Стоимость дипломов высшего и среднего образования и как избежать подделок
forum.alfonsotesauro.net/showthread.php?tid=50831
карниз для штор с электроприводом купить [url=http://www.elektrokarniz-dlya-shtor11.ru]карниз для штор с электроприводом купить[/url] .
Свежие приколы и анекдоты http://shutki-anekdoty.ru/.
Качественные мотозапчасти для вашего мотоцикла | Обновите свой байк современными деталями | Лучшие решения для обслуживания вашего байка | Оригинальные мотозапчасти от ведущих производителей | Широкий ассортимент запчастей для тюнинга мотоциклов | Улучшайте внешний вид и технические характеристики мотоцикла | Лучшие предложения на запчасти для тюнинга | Официальный дилер лучших производителей запчастей | Оптимальные решения для обслуживания мотоцикла | Широкий ассортимент запчастей по доступным ценам | Найдите все необходимое для обслуживания мотоцикла | Лучшие предложения на мотозапчасти для мотоциклов | Улучшите внешний вид и производительность мотоцикла | Эксклюзивные предложения на запчасти для мотоциклов | Консультации специалистов по выбору деталей для мотоциклов
запчасти для мотоцикла альфа [url=https://motorcyclepartsgdra.kiev.ua/]запчасти для мотоцикла альфа[/url] .
вывод из запоя цены ростов-на-дону [url=www.vyvod-iz-zapoya-rostov116.ru]вывод из запоя цены ростов-на-дону[/url] .
Свежие и смешные анекдоты http://shutki-anekdoty.ru/anekdoty.
Полезные советы по безопасной покупке диплома о высшем образовании
купить диплом об окончании школы [url=https://orik-diploms.ru/]orik-diploms.ru[/url] .
Реально ли приобрести диплом стоматолога? Основные этапы
Мы понимаем, что финансовые трудности могут возникнуть внезапно, и важно быстро найти решение. Именно поэтому наш сервис предлагает быстрый доступ к микрозаймам с минимальными требованиями и высокой скоростью одобрения. Мы помогаем нашим клиентам избежать долгих бюрократических процедур, предлагая только проверенные и надежные финансовые решения, которые можно оформить онлайн в кратчайшие сроки.
микро займы [url=https://microloans.kz/]микрокредит казахстан[/url] .
купить диплом в канске [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
диплом о высшем образовании нового образца купить [url=https://server-diploms.ru/]server-diploms.ru[/url] .
купить чистый диплом о высшем образовании [url=https://man-diploms.ru/]man-diploms.ru[/url] .
Полезные советы по безопасной покупке диплома о высшем образовании
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
magazin.orgsoft.ru/communication/forum/index.php?PAGE_NAME=profile_view&UID=208216
специальная оценка условий труда в москве организации экспертиза соут
вывод из запоя в стационаре ростов [url=www.vyvod-iz-zapoya-rostov117.ru/]вывод из запоя в стационаре ростов[/url] .
Смешные мемы http://shutki-anekdoty.ru/kartinki-prikolnye.
Наша компания является надежным помощником на рынке микрозаймов в Казахстане, предоставляя клиентам полный спектр услуг по подбору самых выгодных условий кредитования. Мы понимаем, что выбор подходящего микрозайма может быть сложной задачей, поэтому предлагаем вам доступ к широкому ассортименту предложений от ведущих финансовых организаций страны. Мы тщательно анализируем рынок и подбираем для вас наиболее выгодные и удобные варианты микрозаймов, исходя из ваших индивидуальных потребностей и возможностей.
микрозаймы [url=https://microloans.kz/]микрозайм[/url] .
Сколько стоит диплом высшего и среднего образования и как его получить?
offmarketbusinessforsale.com/kupit-diplom-859214lueb
Всё о покупке аттестата о среднем образовании: полезные советы
Наша команда специалистов готова оказать вам всю необходимую поддержку и помощь в выборе микрозайма. Мы всегда на связи и готовы ответить на любые вопросы, связанные с процессом кредитования.
микро займ [url=https://microloans.kz/]микрокредит онлайн[/url] .
Процесс получения диплома стоматолога: реально ли это сделать быстро?
erudio.global/blog/index.php?entryid=44395
Сколько стоит диплом высшего и среднего образования и как его получить?
foousrp.listbb.ru/viewtopic.php?f=4&t=993
Как получить диплом техникума с упрощенным обучением в Москве официально
Официальная покупка аттестата о среднем образовании в Москве и других городах
bloby.mn.co/posts/69553227
купить диплом кишинев [url=https://landik-diploms.ru/]купить диплом кишинев[/url] .
Веселые видео http://shutki-anekdoty.ru/videos.
Наша миссия — сделать процесс поиска и оформления микрозаймов в Казахстане максимально простым и прозрачным. Мы не только предоставляем актуальную информацию о различных кредитных предложениях, но и консультируем клиентов по всем вопросам, связанным с оформлением микрозаймов. Благодаря нашему опыту и знаниям рынка, мы помогаем клиентам избежать скрытых комиссий и выбрать наиболее выгодные и прозрачные условия.
микро займ [url=https://microloans.kz/]микрокредит онлайн[/url] .
Реально ли приобрести диплом стоматолога? Основные этапы
Узнайте, как безопасно купить диплом о высшем образовании
grad-360.flybb.ru/viewtopic.php?f=3&t=598&sid=e64573ccf4cb156697c028f246b9d147
Профессиональный сервисный центр по ремонту компьютерных видеокарт по Москве.
Мы предлагаем: ремонт видеокарт gigabyte в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Работая с нами, вы получаете возможность оформить микрозайм быстро, безопасно и с минимальными затратами. Мы предлагаем только проверенные и надежные решения, что делает процесс получения финансовой помощи легким и удобным.
займы Казахстан [url=https://microloans.kz/]займ онлайн[/url] .
Официальная покупка диплома вуза с сокращенной программой в Москве
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт телефон
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
купить диплом нового образца в самаре [url=https://arusak-diploms.ru/]arusak-diploms.ru[/url] .
Как приобрести диплом техникума с минимальными рисками
Веселые приколы http://shutki-anekdoty.ru/.
купить диплом вуза отзывы [url=https://russa-diploms.ru/]купить диплом вуза отзывы[/url] .
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт мобильных телефонов рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
купить диплом ранхигс [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
Реально ли приобрести диплом стоматолога? Основные шаги
Алкоклуб и Alcoclub предлагают быструю и круглосуточную доставку алкоголя. Позвоните по номеру +74951086757, чтобы заказать алкоголь в Москве в любое время суток. Этот сервис обеспечивает оперативную доставку по городу, делая процесс удобным и доступным.
Если вам требуется круглосуточный заказ, Алкоклуб — ваш надежный выбор. Связавшись с Alcoclub по номеру +74951086757, вы сможете легко заказать алкоголь на дом. Сервис предлагает разнообразие алкогольной продукции, что гарантирует качество и удобство клиентов.
С Алкоклуб вы всегда можете рассчитывать на оперативную доставку. Оформите заказ через +74951086757, чтобы воспользоваться доставкой алкоголя круглосуточно. Платформа Alcoclub обеспечивает высокий уровень сервиса, чтобы каждый клиент мог получить желаемый напиток вовремя.
продажа дипломов [url=https://server-diploms.ru/]продажа дипломов[/url] .
Официальная покупка диплома вуза с упрощенной программой обучения
Unlu Sahabet Casino’da yeni oyuncular icin en buyuk bonus f?rsat?n? yakalay?n
Sahabet Casino [url=https://t.me/sahabet1194/]Sahabet[/url] .
Выбирайте лучшее для вашего малыша – Peg Perego
peg perego aria коляска [url=https://kolyaska-peg-perego.ru/]https://kolyaska-peg-perego.ru/[/url] .
Легальная покупка диплома о среднем образовании в Москве и регионах
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Быстрая покупка диплома старого образца: возможные риски
купить диплом пожарного [url=https://man-diploms.ru/]man-diploms.ru[/url] .
1с предприятие купить программу цена [url=https://kupit-1s11.ru/]1с предприятие купить программу цена[/url] .
купить меф гашиш бошки соль детское порно кончают
Диплом техникума купить официально с упрощенным обучением в Москве
myparea.mn.co/posts/69998934
куплю диплом куда [url=https://orik-diploms.ru/]orik-diploms.ru[/url] .
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт сотовых
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Диплом техникума купить официально с упрощенным обучением в Москве
севастополь дом престарелых и инвалидов [url=http://xn—-1-6cdshb2cetnmcmp6c5f.xn--p1ai]http://xn—-1-6cdshb2cetnmcmp6c5f.xn--p1ai[/url] .
стационарное выведение из запоя [url=vyvod-iz-zapoya-sochi15.ru]vyvod-iz-zapoya-sochi15.ru[/url] .
Как получить диплом техникума с упрощенным обучением в Москве официально
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: срочный ремонт смартфонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Веселые приколы http://shutki-anekdoty.ru/.
Возможно ли купить диплом стоматолога, и как это происходит
formulaf1.ru/ofitsialnaya-pokupka-diploma-bez-riskov
Свежие приколы, шутки и картинки http://shutki-anekdoty.ru/.
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
tadalive.com/blog/372570/kupit-diplom-470760vcag
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт телефонов в москве рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
капельница от запоя в сочи [url=https://vyvod-iz-zapoya-sochi16.ru/]https://vyvod-iz-zapoya-sochi16.ru/[/url] .
реклама в лифтах дома https://reklama-v-liftah-msk.ru
Купить диплом в Кумертау
kyc-diplom.com/geography/kumertau.html
Профессиональный сервисный центр по ремонту игровых консолей Sony Playstation, Xbox, PSP Vita с выездом на дом по Москве.
Мы предлагаем: ремонт игровых консолей на дому
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как официально купить диплом вуза с упрощенным обучением в Москве
investicos.com/uncategorized/kupit-diplom-934313vmeq
диплом самому купить [url=https://landik-diploms.ru/]landik-diploms.ru[/url] .
Официальная покупка школьного аттестата с упрощенным обучением в Москве
сколько купить диплом о высшем образовании [url=https://prema-diploms.ru/]сколько купить диплом о высшем образовании[/url] .
вывод из запоя стационар [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя стационар [/url] .
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
Стоимость дипломов высшего и среднего образования и процесс их получения
купить дипломы в красноярске недорого [url=https://server-diploms.ru/]server-diploms.ru[/url] .
Профессиональный сервисный центр по ремонту компьютерных видеокарт по Москве.
Мы предлагаем: стоимость замены видеокарты
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как приобрести аттестат о среднем образовании в Москве и других городах
Быстрая покупка диплома старого образца: возможные риски
капельница от запоя цена [url=https://snyatie-zapoya-na-domu15.ru/]snyatie-zapoya-na-domu15.ru[/url] .
капельницы на дому от запоя [url=https://snyatie-zapoya-na-domu17.ru/]капельницы на дому от запоя[/url] .
вывод из запоя нижний новгород [url=http://snyatie-zapoya-na-domu16.ru]вывод из запоя нижний новгород [/url] .
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Легальные способы покупки диплома о среднем полном образовании
купить диплом тамбовского училища педагогического [url=https://man-diploms.ru/]man-diploms.ru[/url] .
Полезные советы по безопасной покупке диплома о высшем образовании
Стоимость дипломов высшего и среднего образования и как избежать подделок
Аттестат школы купить официально с упрощенным обучением в Москве
Официальная покупка школьного аттестата с упрощенным обучением в Москве
network-6063768.mn.co/posts/69548567
Официальная покупка школьного аттестата с упрощенным обучением в Москве
farexpo.ru/club/user/30286/forum/message/4501/4538/#message4538
Официальная покупка аттестата о среднем образовании в Москве и других городах
Тонкий акцент и привлекательный вид, коннелюрный плинтус придаст вашему интерьеру неповторимость
коннелюрный плинтус цена [url=https://konnelyurnyj-plintus-dlya-linoleuma-msk.ru/]коннелюрный плинтус цена[/url] .
Как приобрести аттестат о среднем образовании в Москве и других городах
Рекомендации по безопасной покупке диплома о высшем образовании
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
laviehub.com/blog/kupit-diplom-947393rwum
Диплом вуза купить официально с упрощенным обучением в Москве
Мы занимаемся вывозом мусора газелями разной модификации от стандартных 6 м3 до больших 14 м3 есть также грузчики, работаем по Московской области. Преимущества вывоза мусора газелью в том, что она самая дешёвая услуга вывоза мусора.
Подробный гид по вывозу мусора газелью, с минимальными затратами.
Надежность газели при перевозке мусора, которые должен знать каждый.
Список разрешенных для перевозки грузов газелью, и какие ограничения существуют.
Как сэкономить на вывозе мусора газелью, пользуясь опытом специалистов.
Как избежать неприятностей при вывозе мусора газелью, соблюдая правила перевозки.
вывоз старой мебели на свалку [url=https://vyvoz-musora-gazel-mo.ru/]вывоз строительного мусора газелью[/url] .
диплом аттестат куплю [url=https://orik-diploms.ru/]диплом аттестат куплю[/url] .
Увлекательные факты о смазочно-охлаждающих жидкостях, Как выбрать правильную смазочно-охлаждающую жидкость?, для эффективной работы механизмов, которые гарантируют долгую и безотказную эксплуатацию автомобиля, чтобы избежать неприятных сюрпризов на дороге, для поддержания высокой производительности авто, для предотвращения возможных проблем с оборудованием, для понимания процесса производства, для более грамотного подхода к уходу за механизмами, Советы по уходу за автомобилем с применением смазочно-охлаждающих жидкостей, для долговечности и надежности вашего транспортного средства, Как найти золотую середину между ценой и качеством смазочно-охлаждающих жидкостей?, советы по выбору самой выгодной стратегии
смазочно охлаждающие жидкости [url=https://msk-smazochno-ohlazhdayushchie-zhidkosti.ru/]https://msk-smazochno-ohlazhdayushchie-zhidkosti.ru/[/url] .
подделать диплом [url=https://russa-diploms.ru/]подделать диплом[/url] .
Покупка диплома о среднем полном образовании: как избежать мошенничества?
csexpert.4adm.ru/viewtopic.php?f=70&t=2291
вывод из запоя цены санкт-петербург [url=https://vyvod-iz-zapoya-v-sankt-peterburge15.ru/]vyvod-iz-zapoya-v-sankt-peterburge15.ru[/url] .
вывод из запоя на дому спб цены [url=https://www.azithromycinum.ru]вывод из запоя на дому спб цены[/url] .
Реально ли приобрести диплом стоматолога? Основные этапы
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
investicos.com/uncategorized/kupit-diplom-197601osxp
купить диплом 1992 года [url=https://arusak-diploms.ru/]arusak-diploms.ru[/url] .
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфонов на дому в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
диплома [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
Удивительно, но купить диплом кандидата наук оказалось не так сложно
вывод из запоя в клинике спб [url=vyvod-iz-zapoya-v-sankt-peterburge17.ru]вывод из запоя в клинике спб[/url] .
вывод из запоя на дому спб цены [url=https://vyvod-iz-zapoya-v-sankt-peterburge18.ru/]вывод из запоя на дому спб цены[/url] .
вывод из запоя капельница [url=https://vyvod-iz-zapoya-v-sankt-peterburge16.ru/]вывод из запоя капельница [/url] .
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Диплом пту купить официально с упрощенным обучением в Москве
Реально ли приобрести диплом стоматолога? Основные этапы
купить дипломы о высшем образовании москва [url=https://server-diploms.ru/]server-diploms.ru[/url] .
Официальная покупка диплома вуза с упрощенной программой обучения
Узнайте, как приобрести диплом о высшем образовании без рисков
Узнайте стоимость диплома высшего и среднего образования и процесс получения
купить диплом с регистрацией [url=https://landik-diploms.ru/]купить диплом с регистрацией[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
mir.4admins.ru/posting.php?mode=post&f=10&sid=a4d7fd52f9bebd0e2ec22b5413e65d8d
Легальная покупка диплома ПТУ с сокращенной программой обучения
Свежие и смешные мемы http://shutki-anekdoty.ru/kartinki-prikolnye.
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
сколько стоит купить красный диплом [url=https://man-diploms.ru/]man-diploms.ru[/url] .
Полезные советы по безопасной покупке диплома о высшем образовании
Полезная информация как купить диплом о высшем образовании без рисков
агентство интернет маркетинга [url=https://marketing99.ru/]https://marketing99.ru/[/url] .
бизнес модель цветочного магазина [url=http://cvetov-ray.ru]http://cvetov-ray.ru[/url] .
Диплом вуза купить официально с упрощенным обучением в Москве
sakhd.3nx.ru/viewtopic.php?p=2849#2849
1win
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Как официально приобрести аттестат 11 класса с минимальными затратами времени
Быстрая покупка диплома старого образца: возможные риски
снятие ломки на дому недорого [url=https://snyatie-lomki-narkolog16.ru/]снятие ломки на дому недорого[/url] .
вывод из запоя стационарно [url=www.vyvod-iz-zapoya-v-stacionare-voronezh15.ru]вывод из запоя стационарно[/url] .
снятие ломки на дому недорого [url=www.snyatie-lomki-narkolog15.ru]снятие ломки на дому недорого[/url] .
снятие ломки на дому цена [url=http://snyatie-lomki-narkolog18.ru]снятие ломки на дому цена[/url] .
снятие наркотической ломки [url=http://www.snyatie-lomki-narkolog17.ru]снятие наркотической ломки[/url] .
1win mz
диплом об окончании класса купить [url=https://orik-diploms.ru/]orik-diploms.ru[/url] .
купить аттестат 11 класса [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
Лучший сервис доставки цветов в Нижнем Новгороде, надежно и качественно.
Превратите день волшебства с доставкой цветов в Нижнем Новгороде, не упустите шанс сделать приятное.
Самый широкий ассортимент цветов для доставки в Нижнем Новгороде, закажите прямо сейчас.
Очаруйте своих близких уникальной доставкой цветов в Нижнем Новгороде, доставляем красоту прямо к вам домой.
Устроим цветочный феерверк в Нижнем Новгороде, подарите эмоции и восхищение.
Цветочное настроение с доставкой в Нижнем Новгороде, качество и свежесть гарантированы.
Цветочное настроение от доставки цветов в Нижнем Новгороде, порадуйте себя и других.
Сделайте день особенным: доставка цветов в Нижнем Новгороде, выбирайте лучший сервис.
Идеальный подарок: доставка цветов в Нижнем Новгороде, сделайте заказ у нас.
доставка букетов нижний новгород [url=https://dostavka-cvetov-nizhnij-novgorod.ru/]https://dostavka-cvetov-nizhnij-novgorod.ru/[/url] .
Советы по выбору материала для обивки мебели, чтобы сделать правильный выбор
перетяжка мебели на дому недорого [url=https://csalon.ru/]https://csalon.ru/[/url] .
Лучшие ткани для перетяжки мягкой мебели|Ваш идеальный выбор ткани для перетяжки мебели|Как самому перетянуть мебель: основные моменты|Мастер-класс по перетяжке мягкой мебели|Ткани для перетяжки мебели: как выбрать правильно|Бюджетные варианты перетяжки мягкой мебели|Выбор профессионала для перетяжки мягкой мебели: что учесть|Творческие подходы к перетяжке мягкой мебели|Как обновить интерьер с помощью перетяжки мебели|Как преобразить мебель своими руками: перетяжка как способ обновления|Идеи для перетяжки стульев своими руками|Советы для тех, кто хочет сделать перетяжку мебели своими руками|Модернизация интерьера с помощью перетяжки мебели|Как выбрать цвет ткани для перетяжки мягкой мебели|Зачем перетягивать мягкую мебель: плюсы и минусы|Идеи для перетяжки мебели в современном стиле|Риски перетяжки мебели без профессионалов|Идеи для узоров при обивке мебели: советы по выбору|Шаги по перетяжке мебели: руководство от экспертов
Как быстро получить диплом магистра? Легальные способы
купить диплом о среднем образовании в казани [url=https://landik-diploms.ru/]landik-diploms.ru[/url] .
Официальное получение диплома техникума с упрощенным обучением в Москве
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Полезные советы по безопасной покупке диплома о высшем образовании
вывод из запоя стационар [url=https://vyvod-iz-zapoya-v-stacionare15.ru/]вывод из запоя стационар[/url] .
вывод из запоя нижний новгород стационар [url=www.vyvod-iz-zapoya-v-stacionare14.ru]вывод из запоя нижний новгород стационар[/url] .
вывод из запоя нижний новгород [url=https://vyvod-iz-zapoya-v-stacionare16.ru/]вывод из запоя нижний новгород[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании
Возможно ли купить диплом стоматолога, и как это происходит
Всё, что нужно знать о покупке аттестата о среднем образовании
Официальное получение диплома техникума с упрощенным обучением в Москве
Можно ли купить аттестат о среднем образовании? Основные рекомендации
kawaa.drake.free.fr/index.php?file=Forum&page=viewtopic&forum_id=1&thread_id=6130
Покупка диплома о среднем полном образовании: как избежать мошенничества?
visogo9427.ixbb.ru/viewtopic.php?id=311#p311
купить диплом быстро [url=https://server-diploms.ru/]server-diploms.ru[/url] .
Сервисный центр предлагает ремонт холодильников hauswirt в москве ремонт холодильника hauswirt на дому
Всё, что нужно знать о покупке аттестата о среднем образовании
superforum.spybb.ru/viewtopic.php?id=3252#p51794
Смешные приколы http://shutki-anekdoty.ru.
Аттестат 11 класса купить официально с упрощенным обучением в Москве
Покупка школьного аттестата с упрощенной программой: что важно знать
купить школьный аттестат за 11 классов [url=https://russa-diploms.ru/]russa-diploms.ru[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
купить диплом техника [url=https://man-diploms.ru/]купить диплом техника[/url] .
Explorez notre collection de
Couteaux de cuisine
au meilleur prix
Легальная покупка диплома ПТУ с сокращенной программой обучения
files.4adm.ru/viewtopic.php?f=2&t=803
купить диплом 1992 [url=https://diplomdarom.ru/]diplomdarom.ru[/url] .
купить диплом машиностроение [url=https://realdiplom.ru/]realdiplom.ru[/url] .
Официальная покупка школьного аттестата с упрощенным обучением в Москве
капельницы чтобы выйти из запоя [url=http://www.kapelnica-ot-zapoya-kolomna14.ru]капельницы чтобы выйти из запоя[/url] .
Как правильно купить диплом колледжа и пту в России, подводные камни
Сервисный центр предлагает центр ремонта морозильной камеры liebherr мастерские ремонта морозильных камер liebherr
Смешные анекдоты https://sites.google.com/view/smeshnye-video/anekdoty
Всё, что нужно знать о покупке аттестата о среднем образовании
платная наркологическая помощь на дому [url=http://dexamethazon.ru]платная наркологическая помощь на дому[/url] .
какие капельницы от запоя [url=https://kapelnica-ot-zapoya-kolomna15.ru/]какие капельницы от запоя[/url] .
вызов скорой наркологической помощи [url=skoraya-narkologicheskaya-pomoshch-moskva.ru]skoraya-narkologicheskaya-pomoshch-moskva.ru[/url] .
как вызвать наркологическую бригаду [url=https://www.skoraya-narkologicheskaya-pomoshch-moskva11.ru]https://www.skoraya-narkologicheskaya-pomoshch-moskva11.ru[/url] .
Веселые анекдоты http://shutki-anekdoty.ru/anekdoty
реклама в интернете заказать заказать продвижение сайта в москве
сколько стоит купить диплом бакалавра [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
Диплом вуза купить официально с упрощенным обучением в Москве
купить диплом института в новосибирске [url=https://arusak-diploms.ru/]arusak-diploms.ru[/url] .
Легальная покупка диплома ПТУ с сокращенной программой обучения
Как получить диплом техникума с упрощенным обучением в Москве официально
Аттестат школы купить официально с упрощенным обучением в Москве
купить диплом высшее техническое [url=https://orik-diploms.ru/]orik-diploms.ru[/url] .
Стоимость дипломов высшего и среднего образования и как избежать подделок
продвижение сайта яндекс директ https://is-market.ru
Аттестат школы купить официально с упрощенным обучением в Москве
Где и как купить диплом о высшем образовании без лишних рисков
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Основные моменты Istanbul International Airport, успешные этапы развития.
Интересные факты о Istanbul International Airport, которые вас удивят.
Уникальная архитектура Istanbul International Airport, которые поражают воображение.
Будущее Istanbul International Airport, прогнозы и перспективы.
Что делает аэропорт уникальным, какие услуги понравятся каждому.
istanbul ataturk airport [url=https://airportistanbulinternational.com/]https://airportistanbulinternational.com/[/url] .
Процесс получения диплома стоматолога: реально ли это сделать быстро?
купить диплом об окончании вуза [url=https://landik-diploms.ru/]купить диплом об окончании вуза[/url] .
купить диплом срочно [url=https://server-diploms.ru/]купить диплом срочно[/url] .
Полезная информация как официально купить диплом о высшем образовании
gadjetforyou.ru/kupit-diplom-byistryiy-put-k-uspehu-v-karere
Свежие анекдоты http://shutki-anekdoty.ru/anekdoty
Узнайте, как безопасно купить диплом о высшем образовании
mosreut.flybb.ru/viewtopic.php?f=2&t=287
Официальная покупка диплома ПТУ с упрощенной программой обучения
Узнайте, как безопасно купить диплом о высшем образовании
купить диплом о высшем образовании в сургуте [url=https://man-diploms.ru/]купить диплом о высшем образовании в сургуте[/url] .
купить диплом образования в ярославле [url=https://diplomdarom.ru/]diplomdarom.ru[/url] .
Можно ли быстро купить диплом старого образца и в чем подвох?
Сервисный центр предлагает ремонт msi gt72s в петербурге ремонт msi gt72s в петербурге
вывод из запоя люберцы [url=https://kapelnica-ot-zapoya-lyubercy12.ru/]вывод из запоя люберцы[/url] .
вывод из запоя на дому в люберцах [url=http://kapelnica-ot-zapoya-lyubercy13.ru/]вывод из запоя на дому в люберцах[/url] .
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Быстрое обучение и получение диплома магистра – возможно ли это?
купить диплом санкт [url=https://realdiplom.ru/]realdiplom.ru[/url] .
Сколько стоит диплом высшего и среднего образования и как это происходит?
вывод из запоя цены на дому москва [url=http://www.vyvod-iz-zapoya-moskva13.ru]вывод из запоя цены на дому москва[/url] .
вывод из запоя в клинике балашихи [url=vyvod-iz-zapoya-v-stacionare-balashiha11.ru]вывод из запоя в клинике балашихи[/url] .
капельница от запоя в балашихе [url=https://vyvod-iz-zapoya-v-stacionare-balashiha12.ru/]капельница от запоя в балашихе[/url] .
вывод из запоя в стационаре балашиха [url=https://vyvod-iz-zapoya-v-stacionare-balashiha13.ru/]вывод из запоя в стационаре балашиха[/url] .
1win bet mocambique
Официальная покупка диплома вуза с сокращенной программой в Москве
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Легальные способы покупки диплома о среднем полном образовании
fh9947a1.bget.ru/topic/add
Как официально приобрести аттестат 11 класса с минимальными затратами времени
Полезные советы по безопасной покупке диплома о высшем образовании
vip.7bb.ru/post.php?fid=10
neon54 casino bonus
Быстрая схема покупки диплома старого образца: что важно знать?
запой подольск [url=https://kapelnica-ot-zapoya-podolsk12.ru/]kapelnica-ot-zapoya-podolsk12.ru[/url] .
вывод из запоя на дому в подольске [url=http://kapelnica-ot-zapoya-podolsk13.ru]вывод из запоя на дому в подольске[/url] .
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
eniseiskie-zori.ru/forum/topic/gde-nedorogo-kupit-diplom-ob-obrazovanii/#postid-136
Быстрое обучение и получение диплома магистра – возможно ли это?
neon54 casino login
Официальная покупка школьного аттестата с упрощенным обучением в Москве
купить кандидата наук диплом [url=https://rudik-diploms365.ru/]купить кандидата наук диплом[/url] .
Официальное получение диплома техникума с упрощенным обучением в Москве
meat.ntnn.ru/personal/profile/index.php?register=yes
Узнайте стоимость диплома высшего и среднего образования и процесс получения
Тут можно преобрести огнестойкие сейфы купить купить огнестойкий сейф в москве
Аттестат 11 класса купить официально с упрощенным обучением в Москве
купить проведенный диплом [url=https://3russkiy-diploms.ru/]купить проведенный диплом[/url] .
купить диплом образования воронеж [url=https://2orik-diploms.ru/]2orik-diploms.ru[/url] .
Диплом пту купить официально с упрощенным обучением в Москве
купить диплом повара 4 разряда [url=https://prem-diplom77.ru/]prem-diplom77.ru[/url] .
купить диплом в москве [url=https://servera-diplomy199.ru/]купить диплом в москве[/url] .
купить диплом о образовании в нижнем [url=https://prema365-diploms.ru/]prema365-diploms.ru[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании
Реально ли приобрести диплом стоматолога? Основные этапы
Тут можно купить сейф в дом купить домашний сейф в москве
Тут можно преобрести огнеупорные сейфы сейф противопожарный
Официальное получение диплома техникума с упрощенным обучением в Москве
запой кодирование [url=vyvod-iz-zapoya-ekaterinburg22.ru]запой кодирование[/url] .
вывод из запоя с выездом цена наркология 24 [url=https://www.vyvod-iz-zapoya-chelyabinsk11.ru]вывод из запоя с выездом цена наркология 24[/url] .
вывод из запоя в челябинске [url=https://vyvod-iz-zapoya-chelyabinsk12.ru/]https://vyvod-iz-zapoya-chelyabinsk12.ru/[/url] .
вывод из запоя с выездом цена наркология 24 [url=https://vyvod-iz-zapoya-chelyabinsk13.ru/]вывод из запоя с выездом цена наркология 24[/url] .
вывод из запоя на дому екатеринбург круглосуточно [url=https://vyvod-iz-zapoya-ekaterinburg21.ru/]вывод из запоя на дому екатеринбург круглосуточно[/url] .
Вопросы и ответы: можно ли быстро купить диплом старого образца?
укладка кафельной плитки на пол укладка кафельной плитки в спб цены
Как получить диплом о среднем образовании в Москве и других городах
Как правильно купить диплом колледжа и пту в России, подводные камни
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Процесс получения диплома стоматолога: реально ли это сделать быстро?
нарколог на дом круглосуточно екатеринбург цены [url=https://narkolog-na-dom-ekaterinburg11.ru/]нарколог на дом круглосуточно екатеринбург цены[/url] .
электронный карниз для штор [url=https://elektrokarniz-dlya-shtor15.ru/]электронный карниз для штор[/url] .
цены нарколога на дом в екатеринбурге [url=https://narkolog-na-dom-ekaterinburg12.ru]цены нарколога на дом в екатеринбурге[/url] .
Аттестат 11 класса купить официально с упрощенным обучением в Москве
купить диплом о образовании [url=https://many-diplom77.ru/]купить диплом о образовании[/url] .
купить диплом в салавате [url=https://1russa-diploms.ru/]купить диплом в салавате[/url] .
Тут можно преобрести огнеупорные сейфы сейф противопожарный купить
Аттестат 11 класса купить официально с упрощенным обучением в Москве
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
Полезные советы по безопасной покупке диплома о высшем образовании
cyberpinoy.net/read-blog/74354
Полезные советы по безопасной покупке диплома о высшем образовании
бесплатный сервис накрутки подписчиков в инстаграме [url=www.artmaxboost11.com/]бесплатный сервис накрутки подписчиков в инстаграме[/url] .
купить айфон 13 где купить iphone
Купить диплом о среднем образовании в Москве и любом другом городе
Сколько стоит диплом высшего и среднего образования и как это происходит?
стоимость оформления перепланировки квартиры [url=https://www.stoimost-soglasovaniya-pereplanirovki-kvartiry.ru]стоимость оформления перепланировки квартиры[/url] .
Процесс получения диплома стоматолога: реально ли это сделать быстро?
funnywipes.maxbb.ru/viewtopic.php?f=3&t=893
Как получить диплом техникума с упрощенным обучением в Москве официально
Казино на деньги Казино на деньги
продажа дипломов в москве [url=https://prema365-diploms.ru/]продажа дипломов в москве[/url] .
Официальная покупка диплома ПТУ с упрощенной программой обучения
Легальная покупка школьного аттестата с упрощенной программой обучения
lipetsk-finance.ru/kupit-diplom-1999-goda.html
Как быстро и легально купить аттестат 11 класса в Москве
Возможно ли купить диплом стоматолога, и как это происходит
vseogirls.ru/diplom-v-szhatyie-sroki-shag-k-uspehu-bez-zaderzhek
Полезные советы по покупке диплома о высшем образовании без риска
укладка кафельной плитки цена работы расценки на укладку кафельной плитки
Узнайте, как безопасно купить диплом о высшем образовании
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
Купить диплом о среднем полном образовании, в чем подвох и как избежать обмана?
купить диплом о высшем образовании в хабаровске [url=https://prem-diplom77.ru/]купить диплом о высшем образовании в хабаровске[/url] .
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
диплом гознак высшего образования купить [url=https://servera-diplomy199.ru/]servera-diplomy199.ru[/url] .
сервис накрутки подписчиков youtube [url=https://nakrutkamedia11.com]https://nakrutkamedia11.com[/url] .
Сервисный центр предлагает мастер по ремонту холодильника ginzzu ремонт холодильников ginzzu адреса
Можно ли быстро купить диплом старого образца и в чем подвох?
Легальные способы покупки диплома о среднем полном образовании
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Диплом вуза купить официально с упрощенным обучением в Москве
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
вывод из запоя в ростове на дону [url=https://www.krasnogorsk.anihub.me/viewtopic.php?id=2566]https://www.krasnogorsk.anihub.me/viewtopic.php?id=2566[/url] .
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
Тут можно преобрести сейфы от пожара купить сейф противопожарный
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Легальная покупка диплома о среднем образовании в Москве и регионах
Полезные советы по покупке диплома о высшем образовании без риска
Официальная покупка аттестата о среднем образовании в Москве и других городах
bergha.flybb.ru/viewtopic.php?f=2&t=345
Пошаговая инструкция по официальной покупке диплома о высшем образовании
dianov.bget.ru/forum/thread61974.html#1367942
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Диплом вуза купить официально с упрощенным обучением в Москве
Диплом вуза купить официально с упрощенным обучением в Москве
цены на укладку кафельной плитки https://ukladka-keramogranita-price.ru
Покупка диплома о среднем полном образовании: как избежать мошенничества?
neon54 online casino
Узнайте, как безопасно купить диплом о высшем образовании
как купить диплом в оренбурге [url=https://prema365-diploms.ru/]как купить диплом в оренбурге[/url] .
алкоголизм лечение вывод из запоя ростов [url=www.zal.rolevaya.info/viewtopic.php?id=5357/]алкоголизм лечение вывод из запоя ростов[/url] .
вывод. из. запоя. анонимно. ростов. [url=https://svstrazh.forum24.ru/?1-3-0-00000232-000-0-0-1730725454/]вывод. из. запоя. анонимно. ростов.[/url] .
вывод из запоя стационарно ростов [url=https://automobilist.forum24.ru/?1-19-0-00000137-000-0-0-1730725245/]https://automobilist.forum24.ru/?1-19-0-00000137-000-0-0-1730725245/[/url] .
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
анонимный. вывод. из. запоя. ростов. [url=https://rodoslav.forum24.ru/?1-4-0-00000569-000-0-0-1730725681/]анонимный. вывод. из. запоя. ростов.[/url] .
вывод из запоя круглосуточно ростов-на-дону [url=odessaforum.0pk.me/viewtopic.php?id=10053]odessaforum.0pk.me/viewtopic.php?id=10053[/url] .
Как оказалось, купить диплом кандидата наук не так уж и сложно
Здесь можно преобрести новый сейф модели сейфов
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Тут можно преобрести сейфы от пожара сейф противопожарный
Полезные советы по покупке диплома о высшем образовании без риска
Легальные способы покупки диплома о среднем полном образовании
vavada bonus
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
Сколько стоит диплом высшего и среднего образования и как это происходит?
Рекомендации по безопасной покупке диплома о высшем образовании
Купить диплом о среднем полном образовании, в чем подвох и как избежать обмана?
roomblock.com/diplom-ob-okonchanii-nachalnoy-shkoli-kupit.html
Узнайте, как приобрести диплом о высшем образовании без рисков
Легальная покупка диплома ПТУ с сокращенной программой обучения
вывод из запоя в стационаре ростов-на-дону [url=https://www.kryto.ukrbb.net/viewtopic.php?f=3&t=1164]https://www.kryto.ukrbb.net/viewtopic.php?f=3&t=1164[/url] .
Стоимость дипломов высшего и среднего образования и как избежать подделок
вывод из запоя стационарно ростов [url=https://my.forum2.net/viewtopic.php?id=172]вывод из запоя стационарно ростов[/url] .
вывод из запоя в ростове на дону [url=https://www.internetmoney.bestbb.ru/viewtopic.php?id=31698#p87431]вывод из запоя в ростове на дону[/url] .
Диплом вуза купить официально с упрощенным обучением в Москве
Официальное получение диплома техникума с упрощенным обучением в Москве
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Aviator is ideal for gamers in India who crave real money thrills and strategic play. Master the timing to cash out before the plane crashes! With demo modes and bonus offers, it’s perfect for new and seasoned players alike.
avaitor game [url=https://aviator-games-online.ru/]play aviator online[/url] .
neon58
Сколько стоит диплом высшего и среднего образования и как его получить?
онлайн казино беларусь [url=casino-bonus.by]онлайн казино беларусь[/url] .
вывод из запоя на дому ростов круглосуточно [url=https://honey.ukrbb.net/viewtopic.php?f=45&t=16678/]https://honey.ukrbb.net/viewtopic.php?f=45&t=16678/[/url] .
Тут можно преобрести сейф несгораемый сейф несгораемый купить
Как избежать рисков при покупке диплома колледжа или ПТУ в России
deves.flybb.ru/viewtopic.php?f=2&t=933
Сервисный центр предлагает замена дисплея sony xperia tablet z поменять заднюю крышку sony xperia tablet z
купить диплом парикмахера цена [url=https://1oriks-diplom199.ru/]1oriks-diplom199.ru[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Реально ли приобрести диплом стоматолога? Основные шаги
Быстрое обучение и получение диплома магистра – возможно ли это?
Aviator is ideal for gamers in India who crave real money thrills and strategic play. Master the timing to cash out before the plane crashes! With demo modes and bonus offers, it’s perfect for new and seasoned players alike.
aviator game online [url=https://aviator-games-online.ru/]aviator online game[/url] .
Полезные советы по безопасной покупке диплома о высшем образовании
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
vbocharov-and-friends.ru/viewtopic.php?f=21&t=4133&sid=7c95fa5dfd3301cfe0c188410ff0b9f3
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
neon54 no deposit bonus
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Купить диплом магистра оказалось возможно, быстрое обучение и диплом на руки
Тут можно преобрести огнеупорный сейф сейфы пожаростойкие
Как правильно купить диплом колледжа и пту в России, подводные камни
Официальное получение диплома техникума с упрощенным обучением в Москве
Где и как купить диплом о высшем образовании без лишних рисков
анонимный вывод из запоя ростов [url=https://www.superjackson.ukrbb.net/viewtopic.php?f=28&t=9728]анонимный вывод из запоя ростов [/url] .
Быстрое обучение и получение диплома магистра – возможно ли это?
Официальная покупка диплома ПТУ с упрощенной программой обучения
vavada promo code
Покупка диплома о среднем полном образовании: как избежать мошенничества?
tabloidposmo.co.id/gde-v-rostove-kupit-diplom.html
Сколько стоит получить диплом высшего и среднего образования легально?
Тут можно преобрести купить противопожарный сейф сейфы от пожара
Купить диплом магистра оказалось возможно, быстрое обучение и диплом на руки
Легальные способы покупки диплома о среднем полном образовании
вывод из запоя цены ростов на дону [url=http://masa.forum24.ru/?1-16-0-00002618-000-0-0-1730649347/]http://masa.forum24.ru/?1-16-0-00002618-000-0-0-1730649347/[/url] .
анонимный вывод из запоя ростов [url=https://my.forum2.net/viewtopic.php?id=171/]my.forum2.net/viewtopic.php?id=171[/url] .
алкоголизм лечение вывод из запоя ростов [url=https://sportandpolitics.ukrbb.net/viewtopic.php?f=24&t=17793v/]https://sportandpolitics.ukrbb.net/viewtopic.php?f=24&t=17793v/[/url] .
Узнайте, как безопасно купить диплом о высшем образовании
Как получить диплом техникума официально и без лишних проблем
Как оказалось, купить диплом кандидата наук не так уж и сложно
Полезная информация как официально купить диплом о высшем образовании
fabnews.ru/forum/showthread.php?p=77666
casino 1win
Здесь можно преобрести купить сейф купить сейф в москве цена
Aviator is ideal for gamers in India who crave real money thrills and strategic play. Master the timing to cash out before the plane crashes! With demo modes and bonus offers, it’s perfect for new and seasoned players alike.
aviator game for money [url=https://aviator-games-online.ru/]aviator money game[/url] .
Аттестат 11 класса купить официально с упрощенным обучением в Москве
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
Как получить диплом техникума официально и без лишних проблем
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
Официальная покупка диплома вуза с сокращенной программой в Москве
Get ready to soar with Aviator! This popular game among Indian gamblers lets you cash out at just the right moment for big rewards. With demo mode options, you can perfect your strategy without any risk.
avaitor game [url=https://aviator-games-online.ru/]play aviator online[/url] .
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Тут можно преобрести сейфы огнестойкие сейф огнестойкий в москве
neon54 sign in
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
вывод из запоя на дому в ростове [url=https://kvitka.ukrbb.net/viewtopic.php?f=58&t=28000]https://kvitka.ukrbb.net/viewtopic.php?f=58&t=28000[/url] .
вывод из запоя круглосуточно ростов-на-дону [url=http://www.family2.quadrobb.me/viewtopic.php?id=1836#p6861]http://www.family2.quadrobb.me/viewtopic.php?id=1836#p6861[/url] .
вывод из запоя в ростове на дону [url=http://www.vishivayu.ukrbb.net/viewtopic.php?f=12&t=13420]http://www.vishivayu.ukrbb.net/viewtopic.php?f=12&t=13420[/url] .
Как оказалось, купить диплом кандидата наук не так уж и сложно
Как быстро и легально купить аттестат 11 класса в Москве
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Как быстро и легально купить аттестат 11 класса в Москве
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Купить диплом в России, предлагает наша компания
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр xiaomi, можете посмотреть на сайте: сервисный центр xiaomi в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Легальная покупка школьного аттестата с упрощенной программой обучения
Купить диплом о среднем полном образовании, в чем подвох и как избежать обмана?
recept-food.ru/diplom-kotoryiy-otkroet-dveri-k-luchshim-vozmozhnostyam
купить диплом в арзамасе [url=https://1oriks-diplom199.ru/]1oriks-diplom199.ru[/url] .
Аттестат 11 класса купить официально с упрощенным обучением в Москве
анонимный вывод из запоя ростов [url=www.uaforum.ukrbb.net/viewtopic.php?f=13&t=3230]www.uaforum.ukrbb.net/viewtopic.php?f=13&t=3230[/url] .
Как оказалось, купить диплом кандидата наук не так уж и сложно
Как безопасно купить диплом колледжа или ВУЗа в России, что важно знать
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
Как официально купить диплом вуза с упрощенным обучением в Москве
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Тут можно преобрести сейф для пистолета и ружья купить оружейный сейф в москве
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
Купить диплом судоводителя
Где и как купить диплом о высшем образовании без лишних рисков
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
fordtransit.5nx.ru/viewtopic.php?f=25&t=13985
Полезные советы по покупке диплома о высшем образовании без риска
Как купить диплом о высшем образовании с минимальными рисками
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Диплом вуза купить официально с упрощенным обучением в Москве
Официальное получение диплома техникума с упрощенным обучением в Москве
вызов нарколога на дом круглосуточно [url=http://flanrp.rolevaya.com/viewtopic.php?id=146/]http://flanrp.rolevaya.com/viewtopic.php?id=146/[/url] .
Возможно ли купить диплом стоматолога, и как это происходит
Всё, что нужно знать о покупке аттестата о среднем образовании
firmy-krasnodar.ru/kupit-attestat-za-9-klass-v-ekaterinburge.html
Как оказалось, купить диплом кандидата наук не так уж и сложно
Всё, что нужно знать о покупке аттестата о среднем образовании
Полезные советы по безопасной покупке диплома о высшем образовании
Всё о покупке аттестата о среднем образовании: полезные советы
Быстрое обучение и получение диплома магистра – возможно ли это?
Top Apps to Make Money in Pakistan, Easy Money Making in Pakistan Through Apps, Secret Methods to Make Money in Pakistan, For Quick Earnings, That Are Suitable for Everyone, Is it possible to earn money in Pakistan through applications?, Verified applications for earning money in Pakistan, Modern ways to earn money in Pakistan through applications, with new opportunities for earning money, to increase financial flow, for active participation in earnings, to increase financial well-being, The most interesting apps for making money in Pakistan, Easy ways to make money in Pakistan through apps, Effective apps for making money in Pakistan: check it out yourself, The easiest apps for making money in Pakistan, which bring real money, which will open up new opportunities for earning moneybest online earning app in pakistan [url=https://makemoneyonlinehappy.com/]how to earn money online in pakistan[/url] .
Купить диплом Барнаул
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Как не попасть впросак при покупке диплома колледжа или ПТУ в России
выезд нарколога на дом [url=https://www.automobilist.forum24.ru/?1-19-0-00000138-000-0-0-1730729674]https://www.automobilist.forum24.ru/?1-19-0-00000138-000-0-0-1730729674[/url] .
нарколог на дом анонимно [url=www.vkontakte.forum.cool/viewtopic.php?id=19612#p53237]нарколог на дом анонимно[/url] .
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
Most Popular Money Making Apps in Pakistan, Money Earning Apps That Are Relevant in Pakistan
earn real money by playing games without investment pakistan [url=https://earningappinpakistan.com/]money earning apps in pakistan[/url] .
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Top Money Making Apps in Pakistan, How to Make Money in Pakistan Through Apps
pakistan online earning apps [url=https://earningappinpakistan.com/]pakistan earning app[/url] .
bcgame app
Сколько стоит диплом высшего и среднего образования и как его получить?
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Best Money Making Apps in Pakistan, Money Making Apps That Are in Demand in Pakistan
money earning apps in pakistan [url=https://earningappinpakistan.com/]online earning apps in pakistan[/url] .
Как приобрести аттестат о среднем образовании в Москве и других городах
fbadult.com/blogs/6658/Диплом-без-усилий
Как купить диплом о высшем образовании с минимальными рисками
Купить диплом экономиста – оптимальное решение
Можно ли купить аттестат о среднем образовании? Основные рекомендации
BBgate MarketPlace 2024 Breaking Bad Gate Forum
BBgate MarketPlace
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Полезные советы по безопасной покупке диплома о высшем образовании
1с купить официальный сайт цена [url=kupit-1s11.ru]1с купить официальный сайт цена[/url] .
casino 1win
вызвать нарколога на дом [url=https://alhambra.bestforums.org/viewtopic.php?f=2&t=46372/]вызвать нарколога на дом[/url] .
выезд нарколога на дом [url=https://www.superogorod.ucoz.org/forum/2-2085-1]https://www.superogorod.ucoz.org/forum/2-2085-1[/url] .
Можно ли быстро купить диплом старого образца и в чем подвох?
Аттестат 11 класса купить официально с упрощенным обучением в Москве
Как оказалось, купить диплом кандидата наук не так уж и сложно
Как быстро получить диплом магистра? Легальные способы
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Top Earning App in Pakistan|Amazing Earning Opportunity in Pakistan|Innovative Earning Method in Pakistan|Efficient Earning Tool in Pakistan|Pakistan High Earning Apps|Trustworthy Earning Platform in Pakistan|Pakistan Right Choice for Processing|Best app for earning in Pakistan: time-tested|Effective methods of earning in Pakistan|Innovative approach to earning in Pakistan
apps to earn money in pakistan [url=https://bestearningappinpakistan.com/]pakistan earn money app[/url] .
vavada promo
Полезные советы по безопасной покупке диплома о высшем образовании
Стоимость дипломов высшего и среднего образования и как избежать подделок
Где и как купить диплом о высшем образовании без лишних рисков
Официальное получение диплома техникума с упрощенным обучением в Москве
Best Earning App in Pakistan|Amazing Earning Opportunity in Pakistan|Earning Potential in Pakistan|Earning App in Pakistan: Benefits|Rate the Best Earning App in Pakistan|Trustworthy Earning Platform in Pakistan|Processing App in Pakistan: Proven Tool|Best app for earning in Pakistan: time-tested|Effective methods of earning in Pakistan|App that will make it easier to earn in Pakistan Pakistan
earn money app pakistan [url=https://bestearningappinpakistan.com/]pk earning app[/url] .
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
Аттестат школы купить официально с упрощенным обучением в Москве
Best Earning App in Pakistan|Easy Way to Earn in Pakistan|Innovative Earning Method in Pakistan|Efficient Earning Tool in Pakistan|Profitable Earning App in Pakistan|Trustworthy Earning Platform in Pakistan|Pakistan Right Choice for Processing|Pakistan High Paying App for earnings|Pakistan: leader in earning|Innovative approach to earning in Pakistan
money making apps in pakistan [url=https://bestearningappinpakistan.com/]earn money app pakistan[/url] .
Узнайте стоимость диплома высшего и среднего образования и процесс получения
Легальная покупка диплома ПТУ с сокращенной программой обучения
Идеальная коляска Bugaboo для вашего малыша, Bugaboo: лучшее решение для малыша и родителей, Почему мамы выбирают коляски Bugaboo, Bugaboo: стиль и функциональность в одном, Bugaboo: легкость и управляемость в каждом краше, Bugaboo Fox: лучший выбор для активных родителей, Bugaboo Ant: компактность и функциональность в одном, Bugaboo Buffalo: коляска для любых приключений.
bugaboo fox 2 купить [url=https://kolyaski-bugaboo-msk.ru/]https://kolyaski-bugaboo-msk.ru/[/url] .
Сколько стоит диплом высшего и среднего образования и как это происходит?
Узнайте, как приобрести диплом о высшем образовании без рисков
Best Earning App in Pakistan|Amazing Earning Opportunity in Pakistan|Earning in Pakistan: New Approach|Pakistan Money Processing Software|Pakistan High Earning Apps|Economic Earning in Pakistan|Pakistan Right Choice for Processing|New level of income in Pakistan|Interesting opportunities for earning in Pakistan|Innovative approach to earning in Pakistan
apps for earning money in pakistan [url=https://bestearningappinpakistan.com/]watch ads for money[/url] .
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Купить диплом ВУЗа России
Best Apps to Make Money in Pakistan, For Extra Income, For Anyone Who Wants to Make Money, Optimal Apps to Make Money in Pakistan, For Beginners and Professionals, with a high rating and positive reviews, for successful earnings, Innovative platforms for earning money in Pakistan, for those who strive for financial independence, which few people know about, Successful ways to make money in Pakistan, which bring a stable income, which are worth trying, Easy ways to make money in Pakistan through apps, Unique ways to make money in Pakistan through apps, which will help you achieve financial stability, for making money at any time of the day, to improve financial situationbest online earning websites in pakistan [url=https://makemoneyonlinehappy.com/]how to earn money online in pakistan for students[/url] .
фонтбет [url=www.fonbet-casino-24.by]фонтбет[/url] .
фонтбет [url=fonbet-kazino-24.by]фонтбет[/url] .
Реально ли приобрести диплом стоматолога? Основные этапы
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Реально ли приобрести диплом стоматолога? Основные шаги
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Всё, что нужно знать о покупке аттестата о среднем образовании
Как правильно купить диплом колледжа и пту в России, подводные камни
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Как приобрести диплом техникума с минимальными рисками
samara.listbb.ru/viewtopic.php?f=3&t=697
Аттестат 11 класса купить официально с упрощенным обучением в Москве
вывод из запоя в стационаре анонимно [url=https://ideya.forums.party/viewtopic.php?id=660/]https://ideya.forums.party/viewtopic.php?id=660/[/url] .
Узнайте, как приобрести диплом о высшем образовании без рисков
vavada casino bonus code
Как официально приобрести аттестат 11 класса с минимальными затратами времени
Полезные советы по безопасной покупке диплома о высшем образовании
Как приобрести диплом о среднем образовании в Москве и других городах
Официальная покупка диплома вуза с сокращенной программой в Москве
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Легальные способы покупки диплома о среднем полном образовании
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Купить диплом судоводителя
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали официальный сервисный центр philips, можете посмотреть на сайте: официальный сервисный центр philips
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Покупка школьного аттестата с упрощенной программой: что важно знать
Сколько стоит диплом высшего и среднего образования и как его получить?
Сколько стоит получить диплом высшего и среднего образования легально?
Быстрая схема покупки диплома старого образца: что важно знать?
Идеальный букет невесты для вашей свадьбы, для вашего особенного дня.
Как сделать букет невесты своими руками, для особенного момента.
Лучшие тренды в букете невесты, для свадебной церемонии.
Секреты выбора бюджетного букета невесты, для экономии на свадьбе.
Свежие цветы или нет: какой букет невесты лучше, чтобы было меньше забот и больше радости.
Букет невесты в стиле минимализм, который подчеркнет вашу нежность и изящество.
Секреты подбора букета невесты к платью, для создания гармоничного образа.
букет невесты [url=https://buketnevestynn.ru/]https://buketnevestynn.ru/[/url] .
Сколько стоит получить диплом высшего и среднего образования легально?
casino neon57
Стоимость дипломов высшего и среднего образования и процесс их получения
Легальная покупка диплома о среднем образовании в Москве и регионах
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Как приобрести диплом техникума с минимальными рисками
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
вывод из запоя стационар [url=https://www.www.bisound.com/forum/showthread.php?p=1218353]вывод из запоя стационар [/url] .
вывод из запоя стационар [url=rodoslav.forum24.ru/?1-4-0-00000572-000-0-0-1730749551]rodoslav.forum24.ru/?1-4-0-00000572-000-0-0-1730749551[/url] .
вывод из запоя стационар [url=http://ya.7bb.ru/viewtopic.php?id=14611]http://ya.7bb.ru/viewtopic.php?id=14611[/url] .
Top Money Making Apps in Pakistan, Money Earning Apps That Are Relevant in Pakistan
money earning apps in pakistan [url=https://earningappinpakistan.com/]top 10 earning apps in pakistan[/url] .
вывод из запоя в стационаре анонимно [url=https://bija089.0pk.me/viewtopic.php?id=2556]https://bija089.0pk.me/viewtopic.php?id=2556[/url] .
Быстрое обучение и получение диплома магистра – возможно ли это?
Как официально приобрести аттестат 11 класса с минимальными затратами времени
Best Apps to Make Money in Pakistan, Simple Ways to Make Money in Pakistan Through an App, Unusual Ways to Make Money in Pakistan, Effective Ways to Make Money in Pakistan Through Apps, Top Ways to Make Money in Pakistan through mobile applications, with a high rating and positive reviews, Verified applications for earning money in Pakistan, Modern ways to earn money in Pakistan through applications, How to make money, without leaving home in Pakistan, to make money without straining, which will help you achieve your financial goal, Original ways to make money in Pakistan through apps, How to make money in Pakistan using mobile apps: simple and profitable, which will lead to financial independence, which will suit every user, Popular apps for making money in Pakistan: choose the best, Earnings in Pakistan using mobile apps: reality or fiction?, which will open up new opportunities for earning moneyhow to earn money online in pakistan for students [url=https://makemoneyonlinehappy.com/]online earning app in pakistan[/url] .
vavada promo
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Сайт помогает выбрать выгодные условия обмена валюты, предоставляя доступ к актуальным курсам обменников по всему Казахстану. Теперь финансы под контролем в несколько кликов.
МФО Казахстана [url=https://finance-online.kz/]Ипотека[/url] .
Как получить диплом стоматолога быстро и официально
Официальная покупка аттестата о среднем образовании в Москве и других городах
Покупка диплома о среднем полном образовании: как избежать мошенничества?
На маркетплейсе собрана полная информация о банковских продуктах: от кредитных карт до ипотеки. Жители Казахстана могут быстро выбрать лучший вариант для своих нужд.
Микрокредиты [url=https://finance-online.kz/]Курсы валют[/url] .
вывод из запоя врачом на дому [url=rubiz.forum.cool/viewtopic.php?id=3749]rubiz.forum.cool/viewtopic.php?id=3749[/url] .
Купить диплом в России, предлагает наша компания
Легальная покупка школьного аттестата с упрощенной программой обучения
Как быстро и легально купить аттестат 11 класса в Москве
Bonsai Casino online https://bonsai-casino.net casino offers thousands of popular slots, no deposit play and a 200% bonus on your first deposit!
Платформа позволяет узнать, какие банки предлагают самые выгодные условия для ипотеки. Сравните ставки, сроки и дополнительные бонусы.
банки Казахстана [url=https://finance-online.kz/]Микрокредиты[/url] .
вывод из запоя [url=http://www.vishivayu.ukrbb.net/viewtopic.php?f=12&t=13445]http://www.vishivayu.ukrbb.net/viewtopic.php?f=12&t=13445[/url] .
neon54 sign in
Покупка диплома о среднем полном образовании: как избежать мошенничества?
povzroslomu.kabb.ru/viewtopic.php?f=3&t=130
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Реально ли приобрести диплом стоматолога? Основные этапы
Идеальное решение для отделки помещений
самоклеющийся багет [url=https://elastichnyj-plintus.ru/]самоклеющийся багет[/url] .
1 с бухгалтерия цена [url=https://1s-buhgalteriya-kupit.ru]1 с бухгалтерия цена[/url] .
вывод из запоя наркологом [url=http://www.pandora.ukrbb.net/viewtopic.php?f=2&t=12307]http://www.pandora.ukrbb.net/viewtopic.php?f=2&t=12307[/url] .
Как оказалось, купить диплом кандидата наук не так уж и сложно
Mostbet O‘zbekistonda eng yaxshi o‘yin tanlovlarini taklif etadi | Mostbet-da yangi o‘yinlarni sinab ko‘ring va yutuqlar qo‘lga kiriting | Mostbet-da yuqori koeffitsiyent va bonuslar bilan yutish imkoniyatiga ega bo‘ling | Mostbet-da yangi foydalanuvchilar uchun qiziqarli bonuslar | Mostbet-ning bonusli dasturidan foydalaning va qo‘shimcha yutuqlar oling [url=https://mostbetazcasino.com.az/]mostbet регистрация[/url]
Купить диплом о среднем образовании в Москве и любом другом городе
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Полезная информация о применении индустриальных масел, Лучшие виды индустриальных масел, которые обязательно стоит попробовать, чтобы оптимизировать работу оборудования, Секреты успеха в выборе индустриальных масел, Советы по оптимизации использования индустриальных масел, Как индустриальные масла влияют на окружающую среду, для уменьшения негативного воздействия на экосистему, для повышения производительности предприятия, для сокращения издержек производства
и 20а вязкость [url=https://industrialnyemasla.ru/]и 20а вязкость[/url] .
Купить диплом Барнаул
организация проведения специальной оценки условий труда в москве https://sout213.ru
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
https://getbits.info/novosti/19032-plyusy-virtualnogo-nomera-udobstvo-i-ekonomiya-dlya-sovremennogo-biznesa-i-chastnyh-licz.html
Возможно ли купить диплом стоматолога, и как это происходит
Сколько стоит получить диплом высшего и среднего образования легально?
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
jetour dashing 1.6 luxury jetour dashing цена в россии
нарколог на дом екатеринбург цены [url=https://zarabotokdoma.creartuforo.com/viewtopic.php?id=11486]https://zarabotokdoma.creartuforo.com/viewtopic.php?id=11486[/url] .
вывод из запоя на дому похмельная [url=http://stranaua.ukrbb.net/viewtopic.php?f=2&t=59794]вывод из запоя на дому похмельная[/url] .
Как получить диплом о среднем образовании в Москве и других городах
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Реально ли приобрести диплом стоматолога? Основные шаги
Реально ли приобрести диплом стоматолога? Основные этапы
Быстрое обучение и получение диплома магистра – возможно ли это?
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Наша вакансии доска объявлений — это удобный и надежный сервис, который объединяет тех, кто ищет работу, и тех, кто ищет сотрудников.
Полезная информация как купить диплом о высшем образовании без рисков
Федерация – это проводник в мир покупки запрещенных товаров, можно купить альфа пвп, купить кокаин, купить меф, купить экстази в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
Выбор отеля https://koffer-spb.ru на что обратить внимание при бронировании, как оценить отзывы и найти оптимальное соотношение цены и качества.
Купить диплом судоводителя
Легальная покупка школьного аттестата с упрощенной программой обучения
Правовой сервис «ТвойЮрист» https://tvoyurist.online/services/semeynye-spory/razvod/ предлагает бесплатные юридические консультации по вопросам расторжения брака как онлайн, так и по телефону для жителей Москвы и регионов России. Квалифицированные юристы и адвокаты оказывают помощь при разводе, включая раздел совместно нажитого имущества, взыскание алиментов, оформление опеки, лишение родительских прав и другие сопутствующие семейные споры.
Можно ли быстро купить диплом старого образца и в чем подвох?
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
Диплом техникума купить официально с упрощенным обучением в Москве
Полезные советы по безопасной покупке диплома о высшем образовании
Реально ли приобрести диплом стоматолога? Основные этапы
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
нарколог краснодар [url=http://www.rodoslav.forum24.ru/?1-4-0-00000573-000-0-0-1730786694]http://www.rodoslav.forum24.ru/?1-4-0-00000573-000-0-0-1730786694[/url] .
Стоимость дипломов высшего и среднего образования и процесс их получения
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Можно ли быстро купить диплом старого образца и в чем подвох?
быстрый вывод из запоя в стационаре [url=angelladydety.getbb.ru/viewtopic.php?f=44&t=42948]быстрый вывод из запоя в стационаре[/url] .
вывод из запоя в стационаре анонимно [url=www.ximki.ukrbb.net/viewtopic.php?f=12&t=3703/]вывод из запоя в стационаре анонимно[/url] .
Купить диплом о среднем образовании в Москве и любом другом городе
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Как правильно купить диплом колледжа и пту в России, подводные камни
вывод из запоя анонимно [url=http://pokupki.bestforums.org/viewtopic.php?f=7&t=24072/]вывод из запоя анонимно[/url] .
Быстрая схема покупки диплома старого образца: что важно знать?
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Как официально приобрести аттестат 11 класса с минимальными затратами времени
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Купить диплом судоводителя
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
Реально ли приобрести диплом стоматолога? Основные этапы
newru.getbb.ru/viewtopic.php?f=29&t=2107
Как приобрести аттестат о среднем образовании в Москве и других городах
Как приобрести аттестат о среднем образовании в Москве и других городах
Как быстро получить диплом магистра? Легальные способы
Можно ли быстро купить диплом старого образца и в чем подвох?
Полезные советы по безопасной покупке диплома о высшем образовании
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Всё, что нужно знать о покупке аттестата о среднем образовании
Купить диплом Барнаул
Всё, что нужно знать о покупке аттестата о среднем образовании
капельница от запоя нижний новгород [url=https://superjackson.ukrbb.net/viewtopic.php?f=28&t=9746/]капельница от запоя нижний новгород [/url] .
кухни москва [url=http://www.mebeldinastiya.ru]кухни москва[/url] .
[url=][/url]
Временная регистрация в СПб: Быстро и Легально!
Ищете, где оформить временную регистрацию в Санкт-Петербурге?
Мы гарантируем быстрое и легальное оформление без очередей и лишних документов.
Ваше спокойствие – наша забота!
Минимум усилий • Максимум удобства • Полная легальность
Свяжитесь с нами прямо сейчас!
Временная регистрация
[url=][/url]
Рекомендации по безопасной покупке диплома о высшем образовании
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Узнайте стоимость диплома высшего и среднего образования и процесс получения
Купить диплом экономиста – оптимальное решение
Быстрая схема покупки диплома старого образца: что важно знать?
[url=][/url]
Временная регистрация в Санкт-Петербурге: Быстро и Легально!
Ищете, где оформить временную регистрацию в СПб?
Мы гарантируем быстрое и легальное оформление без очередей и лишних документов.
Ваше спокойствие – наша забота!
Минимум усилий • Максимум удобства • Полная легальность
Свяжитесь с нами прямо сейчас!
Временная регистрация в СПб
[url=][/url]
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Как получить диплом о среднем образовании в Москве и других городах
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Полезные советы по безопасной покупке диплома о высшем образовании
Полезная информация как купить диплом о высшем образовании без рисков
Всё, что нужно знать о покупке аттестата о среднем образовании
[url=][/url]
Временная регистрация в Санкт-Петербурге: Быстро и Легально!
Ищете, где оформить временную регистрацию в СПБ?
Мы гарантируем быстрое и легальное оформление без очередей и лишних документов.
Ваше спокойствие – наша забота!
Минимум усилий • Максимум удобства • Полная легальность
Свяжитесь с нами прямо сейчас!
Временная регистрация в СПБ
[url=][/url]
сделать капельницу на дому от алкоголя [url=www.fanfiction.borda.ru/?1-1-0-00000234-000-0-0-1730813920/]сделать капельницу на дому от алкоголя[/url] .
Купить диплом Барнаул
Как избежать рисков при покупке диплома колледжа или ПТУ в России
капельница от похмелья купить [url=https://aqvakr.forum24.ru/?1-7-0-00011597-000-0-0-1730815014]капельница от похмелья купить[/url] .
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
вывод. из. запоя. на. дому. [url=vkontakte.forum.cool/viewtopic.php?id=19642]вывод. из. запоя. на. дому.[/url] .
капельница от запоя на дому нижний новгород [url=https://zarabotokdoma.creartuforo.com/viewtopic.php?id=11491]капельница от запоя на дому нижний новгород[/url] .
капельница на дому круглосуточно [url=www.mymoscow.forum24.ru/?1-6-0-00022952-000-0-0-1730815603/]капельница на дому круглосуточно[/url] .
Как правильно купить диплом колледжа и пту в России, подводные камни
Купить диплом Барнаул
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Сколько стоит диплом высшего и среднего образования и как его получить?
вывод из запоя в наркологическом стационаре [url=http://tatuheart.ukrbb.net/viewtopic.php?f=8&t=15087]вывод из запоя в наркологическом стационаре[/url] .
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров samsung, можете посмотреть на сайте: ремонт телевизоров samsung адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Аттестат школы купить официально с упрощенным обучением в Москве
Всё, что нужно знать о покупке аттестата о среднем образовании
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Как приобрести аттестат о среднем образовании в Москве и других городах
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
анонимный вывод из запоя в стационаре [url=https://uaportal.ukrbb.net/viewtopic.php?f=2&t=3728]анонимный вывод из запоя в стационаре[/url] .
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Купить диплом Барнаул
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
Диплом техникума купить официально с упрощенным обучением в Москве
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Официальная покупка диплома вуза с сокращенной программой в Москве
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Полезные советы по безопасной покупке диплома о высшем образовании
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Купить диплом экономиста – оптимальное решение
Официальная покупка диплома вуза с упрощенной программой обучения
Официальная покупка диплома вуза с упрощенной программой обучения
Как получить диплом техникума с упрощенным обучением в Москве официально
капельницу коломна от запоя [url=https://stranaua.ukrbb.net/viewtopic.php?f=2&t=59801/]капельницу коломна от запоя [/url] .
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense в москве, можете посмотреть на сайте: ремонт телевизоров hisense
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense цены, можете посмотреть на сайте: ремонт телевизоров hisense адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense, можете посмотреть на сайте: ремонт телевизоров hisense
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Легальная покупка диплома о среднем образовании в Москве и регионах
Полезная информация как официально купить диплом о высшем образовании
Как приобрести диплом техникума с минимальными рисками
Купить диплом судоводителя
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense адреса, можете посмотреть на сайте: ремонт телевизоров hisense адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense, можете посмотреть на сайте: ремонт телевизоров hisense в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense сервис, можете посмотреть на сайте: ремонт телевизоров hisense адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Купить диплом в России, предлагает наша компания
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Официальная покупка аттестата о среднем образовании в Москве и других городах
Как приобрести аттестат о среднем образовании в Москве и других городах
Купить диплом о среднем полном образовании, в чем подвох и как избежать обмана?
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
Купить диплом Барнаул
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Всё о покупке аттестата о среднем образовании: полезные советы
Производство ангаров и складов под ключ.
Подробная информация и заказ быстровозводимый складов
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
Производство ангаров и складов под ключ.
Подробная информация и заказ быстровозводимый складов
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Диплом пту купить официально с упрощенным обучением в Москве
Официальная покупка диплома ПТУ с упрощенной программой обучения
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
[url=][/url]
DESIGN, FABRICATION & INSTALLATION OF CUSTOM MADE LOUVERS!
DK Construction & Design provides comprehensive, custom solutions for louvres,
sunshades, privacy screens, awnings, and balustrades made from aluminium, glass, and steel.
Our end-to-end service covers on-site measurements, design development, detailed drawings,
engineering, fabrication, and installation.
We work closely with designers, architects, and homeowners to deliver tailored shading,
privacy, and safety solutions. Our team ensures that every project meets the highest
standards of quality and durability, with a focus on functionality and aesthetics.
Whether you’re after sleek sun control systems or secure balustrading, we’ve got
the expertise to bring your vision to life.
Tel: +61475 617 720
Сайт компании DK Construction & Design
[url=][/url]
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Официальная покупка диплома ПТУ с упрощенной программой обучения
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
Создайте уютную атмосферу с помощью велас ароматических, Какие ароматы выбрать для разных помещений, оригинальный подарок – велас ароматическая свеча
velas para [url=https://scentalle.com/]https://scentalle.com/[/url] .
Легальная покупка диплома о среднем образовании в Москве и регионах
Легальная покупка школьного аттестата с упрощенной программой обучения
Официальная покупка диплома вуза с упрощенной программой обучения
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров lg в москве, можете посмотреть на сайте: срочный ремонт телевизоров lg
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как оказалось, купить диплом кандидата наук не так уж и сложно
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали срочный ремонт телефонов xiaomi, можете посмотреть на сайте: ремонт телефонов xiaomi в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов realme, можете посмотреть на сайте: ремонт телефонов realme
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов sony адреса, можете посмотреть на сайте: ремонт телефонов sony рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как купить диплом о высшем образовании с минимальными рисками
Диплом пту купить официально с упрощенным обучением в Москве
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Узнайте, как безопасно купить диплом о высшем образовании
юань в тенге [url=https://converter-valut.kz/]евро в тенге[/url] .
Получите доступ к точным курсам валют и бесплатной конвертации. На сайте можно легко перевести тенге, доллары, рубли и юани в нужном направлении за несколько секунд.
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Официальная покупка диплома вуза с сокращенной программой в Москве
Здесь можно оружейные шкафы в москвешкафы для оружия
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов nothing в москве, можете посмотреть на сайте: ремонт телефонов nothing адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов samsung сервис, можете посмотреть на сайте: ремонт телефонов samsung сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Здесь можно сейф купить для дома магазин купить сейф домашний
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов poco сервис, можете посмотреть на сайте: срочный ремонт телефонов poco
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов meizu, можете посмотреть на сайте: ремонт телефонов meizu сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как приобрести аттестат о среднем образовании в Москве и других городах
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов infinix, можете посмотреть на сайте: ремонт телефонов infinix цены
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов honor цены, можете посмотреть на сайте: ремонт телефонов honor
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Здесь можно сейф домашний купить москва купить сейф в дом
Тут можно преобрести взломостойкие сейфы цена взломостойкие сейфы купить
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин zanussi в москве, можете посмотреть на сайте: ремонт стиральных машин zanussi
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин siemens рядом, можете посмотреть на сайте: ремонт стиральных машин siemens в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
Узнайте, как безопасно купить диплом о высшем образовании
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали срочный ремонт стиральных машин smeg, можете посмотреть на сайте: срочный ремонт стиральных машин smeg
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин indesit в москве, можете посмотреть на сайте: ремонт стиральных машин indesit в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин lg, можете посмотреть на сайте: ремонт стиральных машин lg сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Пошаговая инструкция по официальной покупке диплома о высшем образовании
рубли в тенге [url=https://converter-valut.kz/]конвертер валют[/url] .
Сервис обновляет курсы валют в режиме реального времени, позволяя пользователям конвертировать тенге в рубли, доллары США и другие валюты мгновенно и без комиссии.
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин kuppersbusch в москве, можете посмотреть на сайте: ремонт стиральных машин kuppersbusch
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали срочный ремонт приставок xbox, можете посмотреть на сайте: ремонт приставок xbox рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин aeg в москве, можете посмотреть на сайте: ремонт стиральных машин aeg цены
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин siemens цены, можете посмотреть на сайте: ремонт посудомоечных машин siemens в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт приставок sony playstation сервис, можете посмотреть на сайте: ремонт приставок sony playstation в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин miele адреса, можете посмотреть на сайте: ремонт посудомоечных машин miele сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин dexp, можете посмотреть на сайте: ремонт стиральных машин dexp рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин beko сервис, можете посмотреть на сайте: ремонт посудомоечных машин beko адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин midea цены, можете посмотреть на сайте: ремонт посудомоечных машин midea
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как оказалось, купить диплом кандидата наук не так уж и сложно
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Можно ли купить аттестат о среднем образовании? Основные рекомендации
купить диплом в калуге
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин hotpoint ariston, можете посмотреть на сайте: ремонт посудомоечных машин hotpoint ariston
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин aeg, можете посмотреть на сайте: ремонт посудомоечных машин aeg рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Возможности выигрыша в онлайн казино, где ставки высоки.
Получайте азарт и адреналин вместе с нами, и ощутите атмосферу азарта и волнения.
Выберите свое любимое казино онлайн, и начните играть уже сегодня.
Играйте и побеждайте в режиме живого казино, не покидая своего уютного кресла.
Ставьте на победу с нашими играми, и почувствуйте себя настоящим чемпионом.
Насладитесь игровым процессом вместе с игроками со всех уголков планеты, и станьте лучшим из лучших.
Получите бонусы и призы за активную игру, которые принесут вам еще больше радости и азарта.
Играйте и наслаждайтесь азартом в каждой ставке, и погрузитесь в мир бесконечных перспектив.
Получите доступ к уникальным играм и выигрывайте крупные суммы, с минимум затрат времени и усилий.
онлайн казино беларусь [url=https://casino-on-line.by/]онлайн казино[/url] .
Ваша удача ждет вас в онлайн казино, где ставки высоки.
Попробуйте свои силы вместе с нами, и почувствуйте вкус победы.
Выберите свое любимое казино онлайн, и начните играть уже сегодня.
Играйте и побеждайте в режиме живого казино, не тратя время на поездки.
Ставьте на победу с нашими играми, и почувствуйте себя настоящим чемпионом.
Играйте вместе с друзьями и соперниками со всего мира, и докажите свое превосходство.
Начните играть и получите ценные подарки, которые принесут вам еще больше радости и азарта.
Почувствуйте свободу и возможность выбора в каждой игре, и наслаждайтесь бесконечными возможностями.
Играйте в игры, недоступные где-либо еще, сделав всего несколько кликов мыши.
казино беларусь [url=https://casino-on-line.by/]казино беларусь[/url] .
Как быстро и легально купить аттестат 11 класса в Москве
Ваша удача ждет вас в онлайн казино, где ставки высоки.
Играйте и выигрывайте вместе с нами, и ощутите атмосферу азарта и волнения.
Обнаружьте свое новое казино онлайн, и начните выигрывать уже сегодня.
Играйте и побеждайте в режиме живого казино, не тратя время на поездки.
Играйте в увлекательные игры с высокими коэффициентами выигрыша, и покажите всем, кто здесь главный.
Насладитесь игровым процессом вместе с игроками со всех уголков планеты, и докажите свое превосходство.
Получите бонусы и призы за активную игру, которые принесут вам еще больше радости и азарта.
Почувствуйте свободу и возможность выбора в каждой игре, и готовьтесь к бесконечным выигрышам.
Получите доступ к уникальным играм и выигрывайте крупные суммы, с минимум затрат времени и усилий.
онлайн казино беларусь [url=https://casino-on-line.by/]онлайн казино[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
евро в тенге [url=https://converter-valut.kz/]юань в тенге[/url] .
На платформе собраны самые свежие курсы валют Казахстана и мира. Бесплатная конвертация тенге, рублей, юаней и других валют доступна круглосуточно.
With its Curacao license and PAGCOR legitimacy, Taya365 guarantees a fair and regulated gaming experience. Filipino players trust its transparency and dedication to ethical operations.
taya365 slot [url=https://taya365-casino.pro/]taya365 download[/url] .
Остекление балконов по выгодной цене в Петербурге, подберем идеальное решение.
Элитное остекление для балконов в Санкт-Петербурге, с установкой и долговечной эксплуатацией.
Индивидуальное остекление балконов в СПб, с учетом всех пожеланий клиента.
Быстрое остекление для балконов в Санкт-Петербурге, с оригинальными комплектующими и возможностью долгосрочного сотрудничества.
Удобное остекление балконов в Петербурге, с учетом всех требований и технических норм.
застеклить балкон в спб [url=https://balkon-spb-1.ru/]https://balkon-spb-1.ru/[/url] .
Полезная информация как официально купить диплом о высшем образовании
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Join Taya365 to experience Filipino gaming at its best. Whether you’re a seasoned player or a beginner, the platform offers tailored promotions, a vast game selection, and robust security measures.
taya365 casino [url=https://taya365-casino.pro/]taya365 register[/url] .
1 юань в тенге [url=https://converter-valut.kz/]рубли в тенге[/url] .
Платформа предлагает простой интерфейс и бесплатную конвертацию валют. Будь то тенге, рубли или юани – все расчеты происходят моментально с использованием актуальных данных.
Taya365 ensures convenience for Filipino players with quick and secure transactions via popular methods like GCash, Bitcoin, and Ethereum, catering to modern gaming preferences.
taya 365 [url=https://taya365-casino.pro/]taya365[/url] .
Качественные натяжные потолки в Санкт-Петербурге|Скидки на натяжные потолки в СПб|Лучшие специалисты по натяжным потолкам в Петербурге|Разнообразие натяжных потолков в Петербурге|Советы по выбору натяжных потолков в Петербурге|Тепло и гармония с натяжными потолками в Санкт-Петербурге|Современный дизайн с натяжными потолками в Санкт-Петербурге|Красота и практичность с натяжными потолками в Санкт-Петербурге|Долговечные и стойкие натяжные потолки в Санкт-Петербурге|Инновационные технологии для натяжных потолков в СПб|Легко и быстро: установка натяжных потолков в СПб|Идеальный выбор: натяжные потолки в СПб|Инновации и креативность в сфере натяжных потолков в Санкт-Петербурге|Экономьте на натяжных потолках в Санкт-Петербурге|Дизайнерские потолки в Петербурге: натяжные|Профессиональные консультации по выбору натяжных потолков в СПб|Комфорт и эстетика с натяжными потолками в Санкт-Петербурге|Натяжные потолки в СПб: надежность и качество|Индивидуальный подход к каждому клиенту: натяжные потолки в СПб|Плюсы натяжных потолков в Петербурге|Инновационные материалы для натяжных потолков в Петербурге|Высококлассное обслуживание по установке натяжных потолков в Санкт-Петербурге|Тенденции в дизайне потолков: натяжные потолки в СПб|Идеальное сочетание цены и качества: натяжные потолки в СПб
купить натяжной потолок [url=https://potolki-spb-1.ru/]https://potolki-spb-1.ru/[/url] .
Тегін 888starz apk ж?ктеп, спортты? ставкаларды баста?ыз.
купить диплом в волгограде
Полезная информация как купить диплом о высшем образовании без рисков
Узнайте, как безопасно купить диплом о высшем образовании
Быстрая покупка диплома старого образца: возможные риски
Пошаговая инструкция по официальной покупке диплома о высшем образовании
купить диплом в кисловодске [url=https://4russkiy365-diplomy.ru/]4russkiy365-diplomy.ru[/url] .
Как приобрести диплом техникума с минимальными рисками
Официальное получение диплома техникума с упрощенным обучением в Москве
диплом о высшем образовании купить в москве
Попробуйте свою удачу в лучших онлайн казино, где возможности бесконечны.
Играйте и выигрывайте вместе с нами, и почувствуйте вкус победы.
Обнаружьте свое новое казино онлайн, и начните играть уже сегодня.
Играйте и побеждайте в режиме живого казино, не покидая своего уютного кресла.
Выигрывайте крупные суммы при помощи наших игр, и покажите всем, кто здесь главный.
Коммуницируйте и соревнуйтесь с игроками со всего мира, и покажите свои лучшие результаты.
Получите бонусы и призы за активную игру, которые сделают вашу игру еще более увлекательной.
Играйте и наслаждайтесь азартом в каждой ставке, и погрузитесь в мир бесконечных перспектив.
Играйте в игры, недоступные где-либо еще, с минимум затрат времени и усилий.
онлайн казино беларусь [url=https://casino-on-line.by/]онлайн казино[/url] .
Лучшее остекление балконов в СПб, предложим оптимальный вариант.
Профессиональное остекление балконов в Петербурге, под ключ и без переплат.
Эксклюзивное остекление для балконов в Санкт-Петербурге, с учетом всех пожеланий клиента.
Быстрое остекление для балконов в Санкт-Петербурге, с оригинальными комплектующими и возможностью долгосрочного сотрудничества.
Удобное остекление балконов в Петербурге, с учетом всех требований и технических норм.
застеклить балкон в спб [url=https://balkon-spb-1.ru/]https://balkon-spb-1.ru/[/url] .
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Лучшие натяжные потолки в СПб|Скидки на натяжные потолки в СПб|Опытные мастера по натяжным потолкам в Санкт-Петербурге|Разнообразие натяжных потолков в Петербурге|Как выбрать идеальный натяжной потолок в СПб|Натяжные потолки в Петербурге для вашего уюта|Современный дизайн с натяжными потолками в Санкт-Петербурге|Натяжные потолки в СПб: лучший выбор для вашего дома|Долговечные и стойкие натяжные потолки в Санкт-Петербурге|Технологичные решения для натяжных потолков в Санкт-Петербурге|Легко и быстро: установка натяжных потолков в СПб|Совершенство с натяжными потолками в Санкт-Петербурге|Инновации и креативность в сфере натяжных потолков в Санкт-Петербурге|Лучшие цены на натяжные потолки в СПб|Натяжные потолки в СПб: выбор современных людей|Уникальные решения в области натяжных потолков в Санкт-Петербурге|Стильные потолки в Петербурге: натяжные|Натяжные потолки в СПб: надежность и качество|Уникальный дизайн вашего потолка: натяжные потолки в Санкт-Петербурге|Преимущества натяжных потолков в СПб|Инновационные материалы для натяжных потолков в Петербурге|Эксклюзивные услуги по монтажу натяжных потолков в Петербурге|Современные тренды в создании потолков: натяжные потолки в Санкт-Петербурге|Компр
натяжные потолки цена за 1м2 под ключ спб [url=https://potolki-spb-1.ru/]https://potolki-spb-1.ru/[/url] .
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Реально ли приобрести диплом стоматолога? Основные этапы
купить диплом о высшем образовании с занесением
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Стоимость дипломов высшего и среднего образования и процесс их получения
купить диплом в омске о высшем образовании [url=https://4russkiy365-diplomy.ru/]4russkiy365-diplomy.ru[/url] .
https://idematapp.com/wp-content/pages/download_453.html 888starz
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
Попробуйте свою удачу в лучших онлайн казино, где возможности бесконечны.
Попробуйте свои силы вместе с нами, и почувствуйте вкус победы.
Сделайте свой выбор в пользу казино онлайн, и начните выигрывать уже сегодня.
Почувствуйте атмосферу настоящего казино в режиме онлайн, не покидая своего уютного кресла.
Ставьте на победу с нашими играми, и покажите всем, кто здесь главный.
Насладитесь игровым процессом вместе с игроками со всех уголков планеты, и покажите свои лучшие результаты.
Играйте и выигрывайте, получая щедрые бонусы, которые сделают вашу игру еще более увлекательной.
Ощутите азарт в каждой игре казино онлайн, и наслаждайтесь бесконечными возможностями.
Станьте частью казино онлайн и получите доступ к эксклюзивным играм, сделав всего несколько кликов мыши.
казино беларусь [url=https://casino-on-line.by/]казино беларусь[/url] .
Как правильно купить диплом колледжа и пту в России, подводные камни
888starz ilovasini yuklab oling va sportga stavka qilish, kazino o‘yinlaridan bahramand bo‘lish imkoniyatidan foydalaning. Ushbu dastur Android va iOS foydalanuvchilari uchun ishlab chiqilgan bo‘lib, xavfsizlik va qulaylikni ta’minlaydi. Ilova tezkor ishlashni, yuqori funksionallikni va jonli efirlarni qo‘llab-quvvatlaydi. 888starz yuklab olish oynasi orqali barcha blokirovkalarni chetlab o‘tishingiz va o‘yinni davom ettirishingiz mumkin.
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
купить аттестат в санкт петербурге
Официальная покупка диплома вуза с сокращенной программой в Москве
сколько стоит аттестат за 11 класс [url=https://4russkiy365-diplomy.ru/]сколько стоит аттестат за 11 класс[/url] .
купить диплом средне специальное образование
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Возможности выигрыша в онлайн казино, где ставки высоки.
Играйте и выигрывайте вместе с нами, и получите незабываемые впечатления.
Сделайте свой выбор в пользу казино онлайн, и начните зарабатывать уже сегодня.
Ощутите волнение в режиме реального времени, не выходя из дома.
Выигрывайте крупные суммы при помощи наших игр, и станьте настоящим мастером азарта.
Коммуницируйте и соревнуйтесь с игроками со всего мира, и станьте лучшим из лучших.
Играйте и выигрывайте, получая щедрые бонусы, которые принесут вам еще больше радости и азарта.
Играйте и наслаждайтесь азартом в каждой ставке, и готовьтесь к бесконечным выигрышам.
Играйте в игры, недоступные где-либо еще, сделав всего несколько кликов мыши.
казино онлайн беларусь [url=https://casino-on-line.by/]казино онлайн[/url] .
Купить диплом о высшем образовании в Волжском
Ваша удача ждет вас в онлайн казино, где каждый может стать победителем.
Попробуйте свои силы вместе с нами, и получите незабываемые впечатления.
Сделайте свой выбор в пользу казино онлайн, и начните играть уже сегодня.
Почувствуйте атмосферу настоящего казино в режиме онлайн, не тратя время на поездки.
Ставьте на победу с нашими играми, и станьте настоящим мастером азарта.
Насладитесь игровым процессом вместе с игроками со всех уголков планеты, и докажите свое превосходство.
Играйте и выигрывайте, получая щедрые бонусы, которые принесут вам еще больше радости и азарта.
Играйте и наслаждайтесь азартом в каждой ставке, и готовьтесь к бесконечным выигрышам.
Играйте в игры, недоступные где-либо еще, с минимум затрат времени и усилий.
казино онлайн [url=https://casino-on-line.by/]онлайн казино беларусь[/url] .
Ваша удача ждет вас в онлайн казино, где возможности бесконечны.
Получайте азарт и адреналин вместе с нами, и получите незабываемые впечатления.
Сделайте свой выбор в пользу казино онлайн, и начните играть уже сегодня.
Почувствуйте атмосферу настоящего казино в режиме онлайн, не покидая своего уютного кресла.
Выигрывайте крупные суммы при помощи наших игр, и почувствуйте себя настоящим чемпионом.
Насладитесь игровым процессом вместе с игроками со всех уголков планеты, и докажите свое превосходство.
Начните играть и получите ценные подарки, которые увеличат ваши шансы на победу.
Ощутите азарт в каждой игре казино онлайн, и погрузитесь в мир бесконечных перспектив.
Станьте частью казино онлайн и получите доступ к эксклюзивным играм, с минимум затрат времени и усилий.
казино онлайн [url=https://casino-on-line.by/]онлайн казино беларусь[/url] .
Как оказалось, купить диплом кандидата наук не так уж и сложно
Сколько стоит получить диплом высшего и среднего образования легально?
купить диплом о высшем образовании дешево
Попробуйте свою удачу в лучших онлайн казино, где ставки высоки.
Попробуйте свои силы вместе с нами, и почувствуйте вкус победы.
Выберите свое любимое казино онлайн, и начните зарабатывать уже сегодня.
Почувствуйте атмосферу настоящего казино в режиме онлайн, не тратя время на поездки.
Играйте в увлекательные игры с высокими коэффициентами выигрыша, и покажите всем, кто здесь главный.
Насладитесь игровым процессом вместе с игроками со всех уголков планеты, и докажите свое превосходство.
Получите бонусы и призы за активную игру, которые увеличат ваши шансы на победу.
Играйте и наслаждайтесь азартом в каждой ставке, и наслаждайтесь бесконечными возможностями.
Станьте частью казино онлайн и получите доступ к эксклюзивным играм, с минимум затрат времени и усилий.
онлайн казино [url=https://casino-on-line.by/]Казино[/url] .
купить аттестат доцента [url=https://4russkiy365-diplomy.ru/]купить аттестат доцента[/url] .
Возможности выигрыша в онлайн казино, где каждый может стать победителем.
Получайте азарт и адреналин вместе с нами, и ощутите атмосферу азарта и волнения.
Сделайте свой выбор в пользу казино онлайн, и начните выигрывать уже сегодня.
Ощутите волнение в режиме реального времени, не выходя из дома.
Играйте в увлекательные игры с высокими коэффициентами выигрыша, и почувствуйте себя настоящим чемпионом.
Насладитесь игровым процессом вместе с игроками со всех уголков планеты, и покажите свои лучшие результаты.
Начните играть и получите ценные подарки, которые принесут вам еще больше радости и азарта.
Ощутите азарт в каждой игре казино онлайн, и погрузитесь в мир бесконечных перспектив.
Играйте в игры, недоступные где-либо еще, буквально за несколько секунд.
казино беларусь [url=https://casino-on-line.by/]казино беларусь[/url] .
ШҐШ°Ш§ ЩѓЩ†ШЄ ШЄШЁШШ« Ш№Щ† Щ…Щ†ШµШ© Щ…Щ€Ш«Щ€Щ‚Ш© Щ„Щ„Щ…Ш±Ш§Щ‡Щ†Ш§ШЄШЊ ЩЃШҐЩ† https://888starz-egypt.online/ Щ‡Щ€ Ш®ЩЉШ§Ш±Щѓ Ш§Щ„ШЈЩ…Ш«Щ„. Щ‚Щ… ШЁШІЩЉШ§Ш±ШЄЩ‡ Ш§Щ„ШўЩ†.
купить диплом в минеральных водах [url=https://2orik-diploms.ru/]2orik-diploms.ru[/url] .
Официальная покупка диплома вуза с сокращенной программой в Москве
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
сколько в среднем стоит диплом о высшем образовании с занесением в реестр [url=https://prema-diploms.ru/]сколько в среднем стоит диплом о высшем образовании с занесением в реестр[/url] .
Как быстро получить диплом магистра? Легальные способы
Быстрое обучение и получение диплома магистра – возможно ли это?
купить диплом психолога
купить среднее образование [url=https://4russkiy365-diplomy.ru/]купить среднее образование[/url] .
Официальное получение диплома техникума с упрощенным обучением в Москве
купить диплом в кемерово [url=https://2orik-diploms.ru/]2orik-diploms.ru[/url] .
купить диплом волонтера [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
где купить дипломы о высшем образовании отзывы [url=https://4russkiy365-diplomy.ru/]где купить дипломы о высшем образовании отзывы[/url] .
Как получить диплом техникума с упрощенным обучением в Москве официально
Вопросы и ответы: можно ли быстро купить диплом старого образца?
купить диплом в пензе
купить диплом института
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Где и как купить диплом о высшем образовании без лишних рисков
купить диплом о высшем образовании
Приобретение диплома ВУЗа с сокращенной программой обучения в Москве
купить диплом спо
диплом купить в ижевске
Всё о покупке аттестата о среднем образовании: полезные советы
диплом о среднем полном образовании купить
купить аттестат в ульяновске
1win app
Лучшие советы по выбору металлической входной двери, которая прослужит долгие годы.
Где купить надежную входную металлическую дверь по выгодной цене.
Советы по избежанию ошибок при покупке металлической входной двери.
Преимущества металлических входных дверей перед другими видами.
купить входную дверь [url=https://dver-metallicheskaya-vhodnaya.ru/]заказать входную дверь[/url] .
В чем отличия входных металлических дверей разных производителей.
Официальная покупка диплома вуза с сокращенной программой в Москве
Lemon casino