
Originally published June 17, 2020
Like many programmers who hold degrees that are not even relevant to computer programming, I was struggling to learn coding by myself since 2019 in the hope to succeed in the job. As a self-taught developer, I’m more practical and goal-oriented about things that I’ve learned. This is why I like web scraping particularly, not only it has a wide variety of use cases such as product monitoring, social media monitoring, content aggregation, etc, but also it’s easy to pick up.
The essential idea of web scraping is to extract information snippets from the websites and export them into an easily readable format. If you’re a data-driven person, you will find great values in web scraping. Luckily, there are free web scraping tools available to capture web data automatically without coding.
The web context is more complex than we could imagine. Having said that, we need to put in the time and effort to maintain the scraping work, not to mention massive scraping from multiple websites. On the flip side, scraping tools save us from writing up codes and endlessly maintaining work.
To give you an idea of the pros and cons of python scraping and website scraping tools, I will walk you through the entire work of python. And then I will compare the process with a web scraping tool.
Let’s get started!
Web Scraping With Python
Project:
-
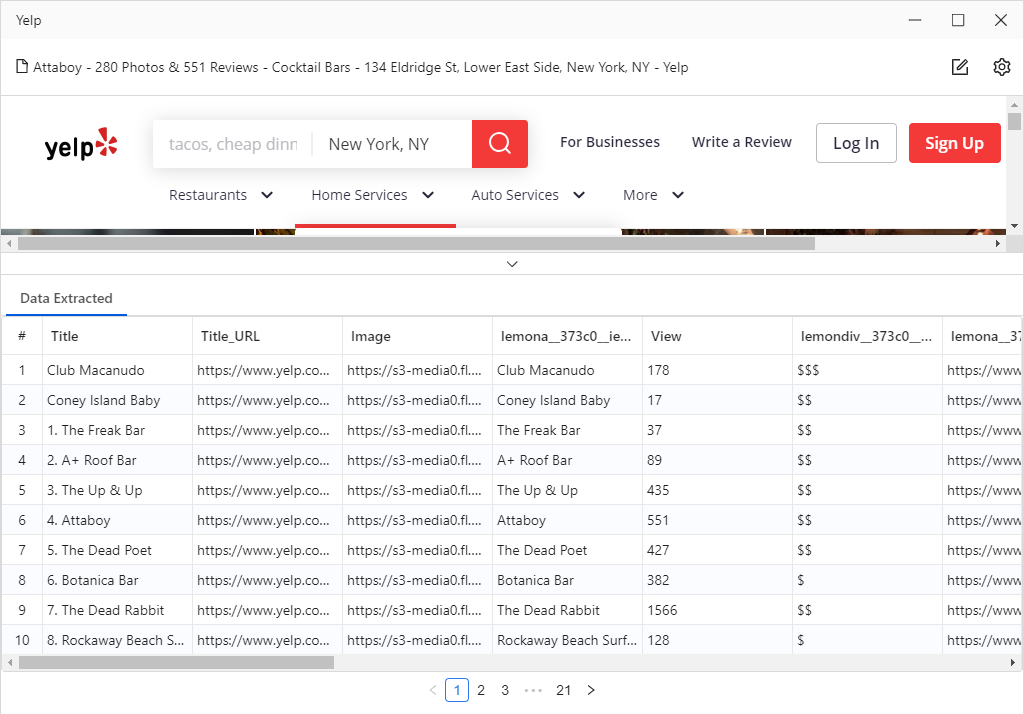
website: Yelp.com
-
Scraping content: business title, ratings, review counts, phone number, price range, address, neighborhood
You will find full coding here: https://github.com/whateversky/yelp
Prerequisite
-
Pycharm — for fast-checking and fixing the coding errors
The general scraping process will look like this:
-
First, we create a spider to define how we will perform and extract data from Yelp. In other words, we send GET requests, and then set rules for scrapers to crawl the website.
-
Then, we parse the web page content and return the dictionary with extracted data. Having said that, we tell the spider that it must return either an Item object or a Requested object.
-
Finally, export extracted data returned from the spider.
I only focus on the spider and parser. However, we certainly need to understand web structures before data extraction. While coding, you will also find yourself constantly inspecting the webpage all the time to access the divs and classes. To inspect the website, go to your favorite browser and right-click. Choose “Inspect” and find the “XHR” tab under the Network.
You will find corresponding listing information including store names, phone numbers, locations, and ratings. As we expand the “PaginationInfo”, it shows us that there are 30 listings on each page, and have a total number of 6932 listings. So by the end of this video, we should be able to get that many results. Now let’s head to the fun part:
Spider
First, open Pycharm and set up a new project. Then set up a python file, and name it “yelp_spider”
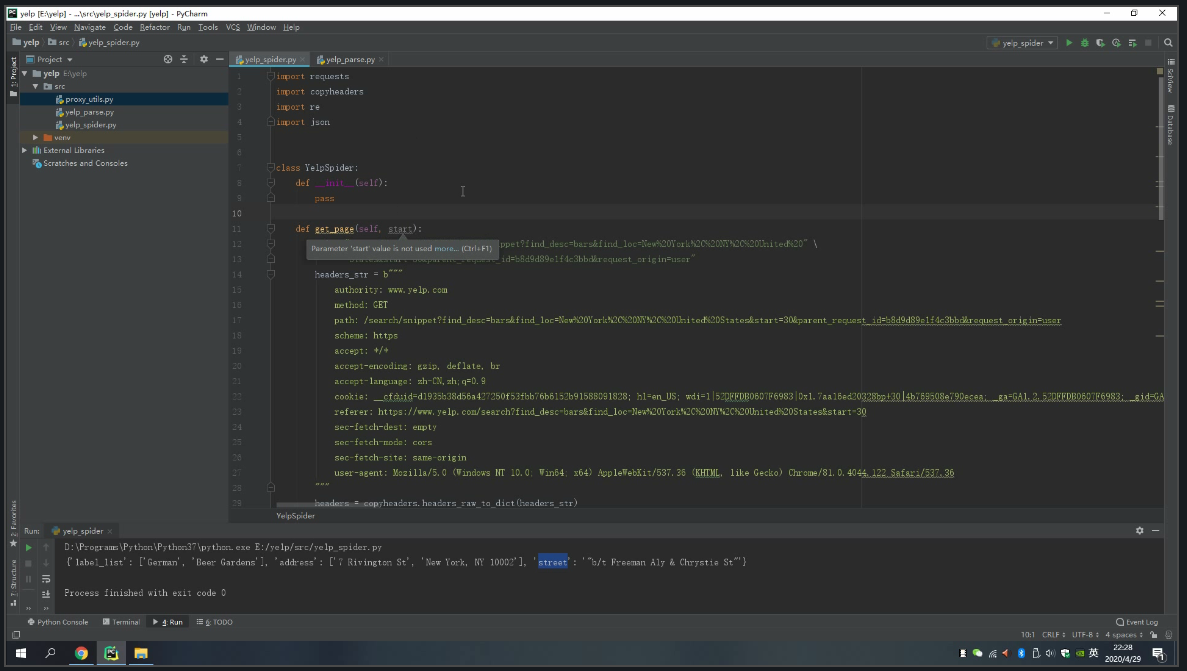

Getting Page:
We create a get_page method. This will pass a query argument that contains all the listing web URLs and then returns the page JSON. Note that I also add a user-agent string to spoof the webserver to bypass any scraper detection. We can just copy and paste the Request Headers. It is not necessary but you will find it useful most of the time if you tend to scrape a website repeatedly.
I add .format argument to format the urls so it returns an endpoint follows a pattern, in this case, all the listing pages from search result of “Bar in New York city”
def get_page(self, start_number):
url = “https://www.yelp.com/search/snippet?find_desc=bars&find_loc=New%20York%2C%20NY%2C%20United%20States&start={}&parent_request_id=dfcaae5fb7b44685&request_origin=user” .format(start_number)
.format(start_number)
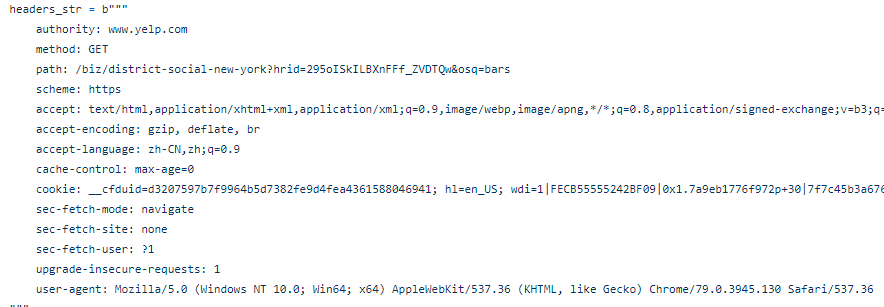
Getting Detail:
We just successfully in harvesting the urls to the listing pages, we can now tell the scraper to visit each detail page using the get_detail method.
The detail page URL consists of a domain name and a path that indicates the business.

As we already gathered the listing URLs, we can simply define the URL pattern which includes a path appended to https://www.yelp.com. This way it will return a list of detail page URLs
xxxxxxxxxx
def get_detail(self, url_suffix): url = “https://www.yelp.com/” + path
Next, we still need to add a header to make the scraper look more human. It’s similar to a common etiquette for us to knock before entering.
Then I created a FOR loop combined with IF statements to locate the tags that we are going to get. In this case, the tags that contain the business name, rating, review, phone, etc.
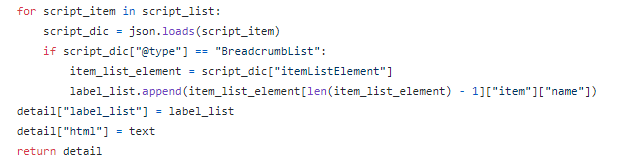
Unlike listing pages that will return JSON format, detail pages normally respond to us in HTML format. Therefore I strip away the punctuations and extra spaces to make them look clean and neat while parsing.
Parsing
As we visit those pages one by one, we can instruct our spider to obtain the detailed information by parsing the page.
First, create a second file called “yelp_parse.py” under the same folder. And start with import and execute YelpSpider.
Here I add a pagination loop since there are 30 listings split across multiple pages. The “start_number” is an offset value, which is “0” in this case. It increases numbers by 30 as we finish crawling the current page. In this manner, the logic will like this:
- Get first 30 listings
- Paginate
- Get 31-60 listings
- Paginate
- Get 61-90 listings….
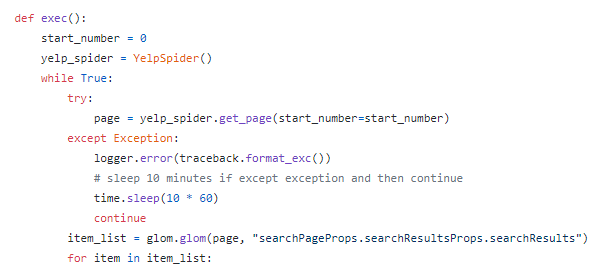
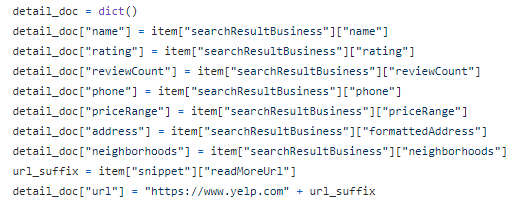
Last but not least, I create a dictionary to pair the key and values with respective data attributes including business name, rating, phone, price range, address, neighborhoods, and so forth.
Scraping with web scraping tool:
With python, we directly interact with the webserver, portals, and source code. Ideally, this method would be more effective but involves programming. As the website is so versatile, we need to constantly edit the scraper and adapt to the changes. So do the Selenium and the Puppeteer, they’re close relatives but come with limitations compared to Python for large-scale extraction.
On the other hand, web scraping tools are more friendly. Let’s take Octoparse as an example:
Octoparse’s latest version OP 8.1 applies the Train Algorithm which detects the data attributes when the web page gets loaded. If you ever experienced the iPhone’s face unlock which applies Artificial Intelligence, “detection” is not a strange term to you.
Likewise, Octoparse will automatically break down the web page and recognize various data attributes, for instance, business name, contacts information, reviews, locations, ratings, etc.
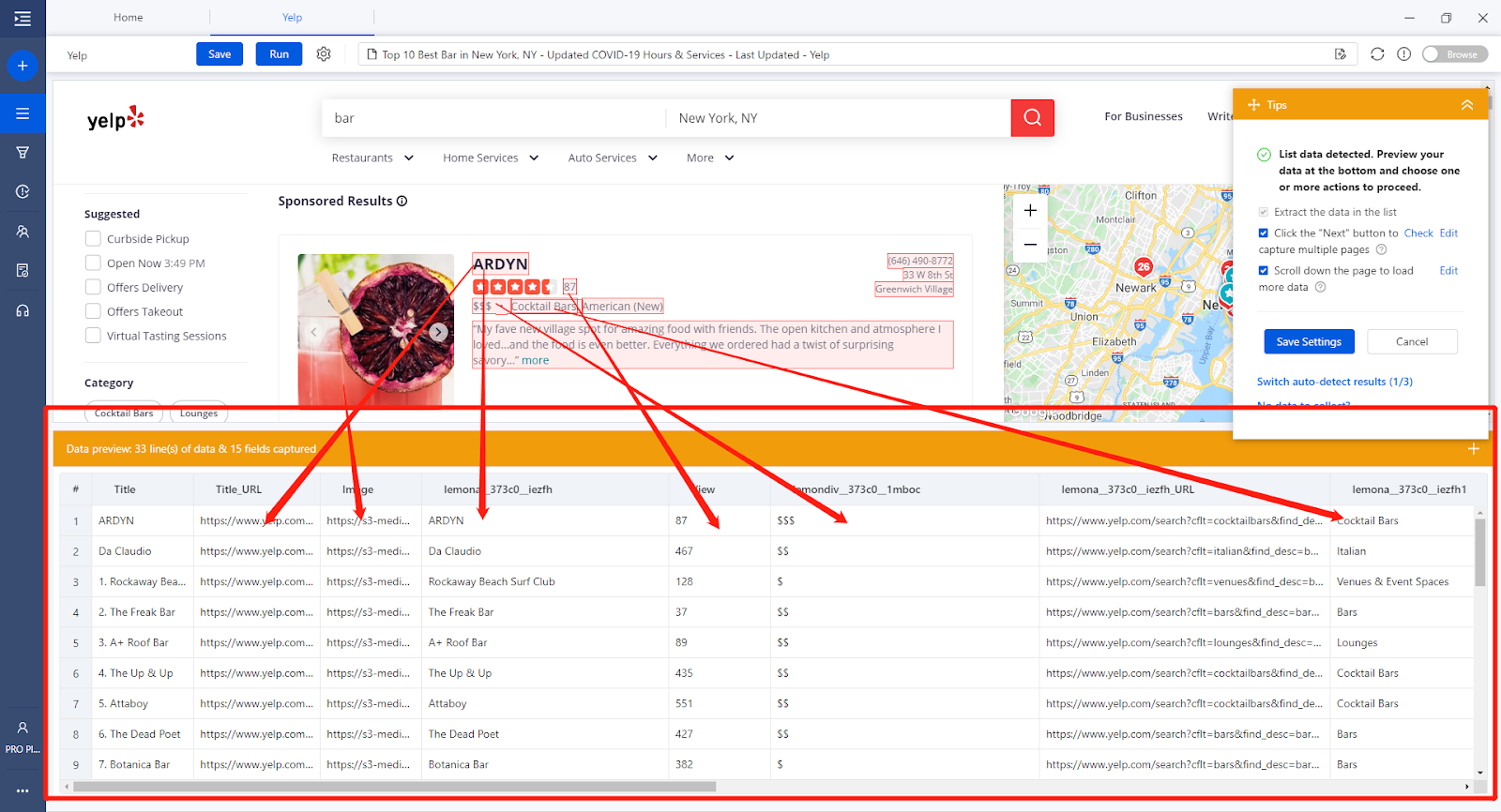
Take yelp as an example. Once the web page gets loaded, it parses the web element automatically and reads the data attributes automatically. Once the detection process gets done, we can see all the data that Octoparse captured for us from the preview section, nice and neat! Then You will notice the workflow has been created automatically. The workflow is like a scraping roadmap, and the scraper will follow the direction to capture the data.
We’ve created the same thing in the python section, but they were not visualized with clear statements and graphs like Octoparse. Programming is more logical and abstract which is not easy to conceptualize without a firm grounding in this field.
But that’s not all, we want to get information from detailed pages. It’s easy peasy. Just follow the guide from the tips panel and find “Collect web data on the page that follows”.
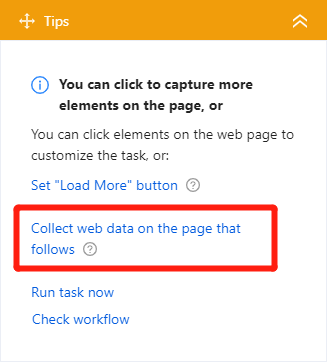
Then choose title_url which can bring us to the detail page.
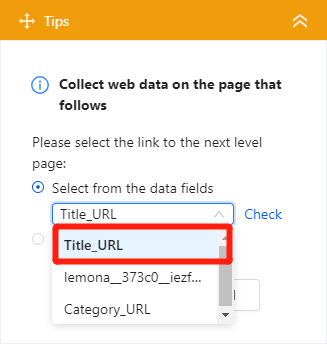
Once we confirm the step, a new step will add to the workflow automatically. Then the browser will display a detail page and we can click any data attribute within the page. For example, when we click the business title “ARDYN”, the tips guide will respond with a set of actions for us to choose from. Simply click the “Extract the text of the selected element” command, it will take care of the rest and add the action to the workflow. Similarly, repeat the above step to get “ratings”, “review counts”, “phone number”, “price range”, “address”.

Once we set all the things up, we can execute the scraper upon confirmation.
Final Thoughts: Scraping Using Python vs Web Scraping Tools
They both can get you similar results but different in performance. With python, there is certainly a lot of groundwork that needs to take place before implementation. Whereas, scraping tools are a lot more friendly on many levels.
If you are new to the world of programming and want to explore the power of web scraping, nonetheless to say, a web scraping tool is a great starting point. As you set foot in the door of coding, there’re wider choices and combinations that I believe will spark new ideas and make things more effortless and easier.
文章来源于互联网:Intro to Yelp Web Scraping Using Python
发布者:小站,转转请注明出处:http://blog.gzcity.top/4194.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
评论列表(1,234条)
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
quickly and efficiently https://sabanraur.com done instantly with a guarantee
I will create a feed https://undersapr.ru for Yandex Webmaster in the “Doctors” category. The feed is used to promote doctors’ cards in search for free
проститутки царицыно проститутки метро отрадное
проститутки узбечки https://samara.prostitutki.sex
индивидуалки мытищи интим досуг
проститутки балашиха минет в москве
старые проститутки москвы индивидуалки в москве
проститутки перово проститутки узбечки
Самое свежее и актуальное http://barbie-games.ru/ychenym-ydalos-yvidet-dvijenie-eksitonov
Свежие и актуальные http://barbie-games.ru новости современной техники
торт на заказ с доставкой где можно купить торт
Новости высоких технологий http://barbie-games.ru/category/novyie-tehnologii новинки компьютерной техники и мобильных телефонов
Актуальные новости техники http://barbie-games.ru/more-v-monastyrskom-podvale и гаджетов.
Свежие новости http://barbie-games.ru/boevye-roboty-bydyt-predstavleny-na-russiaarmsexpo-2015 технологий новинки компьютерной техники
онлайн предсказания бесплатно виртуальные гадания
Federation of Scout Associations of Spain https://scout.es/scout-academy-2017/ is a non-profit entity whose registered office is located in Lake
transparent balloon https://balloons-sale-dubai.com
трубные решетки теплообменных аппаратов трубные доски
A collection of 18-25-year olds from around the UK https://www.scouts.org.uk/volunteers/running-things-locally/recruiting-and-managing-volunteers/role-descriptions/uk-rep-pool/ who are trained to represent the UK Scouts at events in the UK and abroad.
Federation of Scout Associations of Spain https://scout.es/scout-academy-2017 is a non-profit entity whose registered office is located in Lake
производство грузовых подъемников https://gruzovye-podemniki-zakazat.ru
вызвать такси номер такси город
заказать такси по телефону такси цена
такси цена https://vyzvat-taxi-shahty.ru
индийский пасьянс гадать онлайн бесплатно [url=www.indiyskiy-pasyans-online.ru]www.indiyskiy-pasyans-online.ru[/url] .
вывод из запоя недорого ростов [url=https://vyvod-iz-zapoya-rostov111.ru/]https://vyvod-iz-zapoya-rostov111.ru/[/url] .
электрокарнизы в москве [url=https://provorota.su/]электрокарнизы в москве[/url] .
CVzen https://cvzen.it e il servizio leader per la scrittura di CV e il coaching di carriera, scelto da milioni di candidati globalmente. Offriamo supporto completo: redazione di CV e lettere di presentazione, ottimizzazione di LinkedIn e coaching personalizzato per sbloccare il tuo potenziale e nuove opportunita.
кнопка вневедомственной охраны [url=www.trknpk.ru/]кнопка вневедомственной охраны [/url] .
вывод из запоя срочно ростов [url=http://www.vyvod-iz-zapoya-rostov11.ru]http://www.vyvod-iz-zapoya-rostov11.ru[/url] .
создание и продвижение сайта https://process-seo.ru
seo услуги https://process-seo.ru
вывод из запоя недорого [url=http://www.vyvod-iz-zapoya-rostov112.ru]http://www.vyvod-iz-zapoya-rostov112.ru[/url] .
вывод из запоя в стационаре ростов-на-дону [url=vyvod-iz-zapoya-rostov11.ru]вывод из запоя в стационаре ростов-на-дону[/url] .
врач нарколог на дом [url=https://www.narkolog-na-dom-krasnodar11.ru]https://www.narkolog-na-dom-krasnodar11.ru[/url] .
воздуховоды и комплектующие для вентиляции комплектующие для воздуховодов
пластиковые окна в рассрочку без банка [url=https://remstroyokna.ru/]remstroyokna.ru[/url] .
продать скины кс2 с выводом на карту https://prodat-skiny-ks2.ru
вызвать нарколога на дом [url=http://www.narkolog-na-dom-krasnodar12.ru]http://www.narkolog-na-dom-krasnodar12.ru[/url] .
капельница от запоя [url=xn——7cdhaozbh1ayqhot7ooa6e.xn--p1ai]капельница от запоя[/url] .
уход за тяжелобольными [url=http://xn—–1-43da3arnf4adrboggk3ay6e3gtd.xn--p1ai]уход за тяжелобольными[/url] .
[url=][/url]
Sale of non ferrous metal alloys
At Cliffton Trading, we pride ourselves on being a leading international supplier of non-ferrous metals. Based in Dubai, our company specializes in providing high-quality materials such as copper powder, copper ingots, selenium powder, and nickel wire to industries around the world. Our commitment to excellence ensures that every product we offer meets the highest standards, backed by certifications from top chemical laboratories.
[url=https://cliffton-group.com/catalog/copper-powder/]Copper powder[/url]
Pure high-quality copper powder (Cu) with consistent particle size.
[url=https://cliffton-group.com/catalog/copper-ingots/]Copper ingots[/url]
These bullions have high purity and excellent conductivity, making them indispensable in electronics manufacturing, construction and mechanical engineering.
[url=https://cliffton-group.com/catalog/selenium-powder/]Selenium powder[/url]
Our products include high purity metal dust and microfine powder.
[url=https://cliffton-group.com/catalog/nickel-wire]Nickel wire[/url]
Nickel wire is ideal for use in a variety of industrial applications.
With a strong global distribution network, we serve over 15 countries, catering to diverse sectors like construction, automotive, and electronics. Our approach is centered on reliability, quality, and customer satisfaction, which allows us to build lasting relationships with our clients. We understand the importance of tailored solutions, so we work closely with our customers to meet their specific needs, ensuring that they receive the best possible value.
Our team of experienced professionals is dedicated to maintaining the integrity and efficiency of our supply chains, allowing us to deliver products consistently and on time. Competitive pricing, combined with our extensive product range, makes us a preferred partner for businesses seeking dependable suppliers of non-ferrous metals. At Cliffton Trading, we are not just about transactions; we are about building partnerships that drive success for both our company and our clients.
You can view the products and place an order on our website [url=https://cliffton-group.com/]cliffton-group.com[/url].
[url=][/url]
как заработать денег с нуля [url=http://kak-zarabotat-dengi11.ru]http://kak-zarabotat-dengi11.ru[/url] .
Джип туры по Крыму https://м-драйв.рф/tours/yaltinskij-drajv/ уникальные маршруты и яркие эмоции. Погрузитесь в увлекательнее приключение вместе с нами. Горные, лесные, подземные экскурсии, джиппинг в Крыму с максимальным комфортом.
Джип туры по Крыму https://м-драйв.рф/tours/yaltinskij-drajv/ уникальные маршруты и яркие эмоции. Погрузитесь в увлекательнее приключение вместе с нами. Горные, лесные, подземные экскурсии, джиппинг в Крыму с максимальным комфортом.
лечение наркозависимости в стационаре [url=https://vyvod-iz-zapoya-v-stacionare-voronezh11.ru]лечение наркозависимости в стационаре[/url] .
срочная помощь вывод из запоя краснодар [url=http://vyvod-iz-zapoya-krasnodar12.ru/]http://vyvod-iz-zapoya-krasnodar12.ru/[/url] .
нарколог вывод из запоя краснодар [url=https://www.vyvod-iz-zapoya-krasnodar11.ru]https://www.vyvod-iz-zapoya-krasnodar11.ru[/url] .
срочный вывод из запоя на дому недорого [url=http://vyvod-iz-zapoya-ekaterinburg.ru]срочный вывод из запоя на дому недорого[/url] .
вывод из запоя капельница [url=https://vyvod-iz-zapoya-ekaterinburg11.ru/]https://vyvod-iz-zapoya-ekaterinburg11.ru/[/url] .
Прикольные картинки [url=http://kartinkitop.ru/]Прикольные картинки[/url] .
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Экскурсии и джип-туры по Крыму https://м-драйв.рф/tours/yaltinskij-drajv/
продвижение сайта в топ москва [url=http://prodvizhenie-sajtov-v-moskve213.ru]продвижение сайта в топ москва[/url] .
шуточки [url=korotkieshutki.ru]korotkieshutki.ru[/url] .
вывод из запоя в стационаре [url=http://vyvod-iz-zapoya-v-stacionare.ru/]вывод из запоя в стационаре[/url] .
вывод из запоя круглосуточно нижний новгород [url=http://vyvod-iz-zapoya-v-stacionare13.ru/]http://vyvod-iz-zapoya-v-stacionare13.ru/[/url] .
Авторские джип-туры по Крыму https://м-драйв.рф/tours/krysha-kryma/ из Ялты. Уникальная возможность исследовать самые живописные места Крыма.
прогнозы на спорт бесплатные [url=https://www.rejting-kapperov13.ru]https://www.rejting-kapperov13.ru[/url] .
переезд квартиры минск [url=https://kvartirnyj-pereezd11.ru]https://kvartirnyj-pereezd11.ru[/url] .
вывод из запоя цены сочи [url=https://vyvod-iz-zapoya-sochi11.ru/]vyvod-iz-zapoya-sochi11.ru[/url] .
вывод из запоя в стационаре анонимно [url=https://vyvod-iz-zapoya-sochi12.ru/]вывод из запоя в стационаре анонимно[/url] .
сколько стоит капельница на дому от запоя [url=www.snyatie-zapoya-na-domu11.ru/]сколько стоит капельница на дому от запоя[/url] .
Промокод для Фонбет на сегодня промокод promokod
Для получения актуального промокода на сегодня рекомендуется следить за обновлениями на сайте Фонбет или подписаться на рассылку новостей. Сегодняшние промокоды могут включать бесплатные ставки, увеличение депозита или другие бонусы. Примером такого промокода является ‘GIFT200’, который предоставляет бесплатные ставки для новых пользователей.
[url=][/url]
Лучшая сантехника по низким ценам в Минске
Если вы ищете, где купить сантехнику в Минске, то наш интернет-магазин — для вас.
Большой ассортимент товаров представлен в различных ценовых категориях, а благодаря разнообразию размеров,
форм и других параметров, вы точно найдёте наиболее подходящую модель.
Создайте свой уникальный дизайн ванной комнаты вместе с нами!
Почему Almoni?
Высокое качество: мы работаем с ведущими производителями и брендами с мировым именем,
например: Orans, Ravak, Vitra, Kaldewey, Roca и другие. Все изделия сертифицированы.
Доступные цены: благодаря нашему сотрудничеству напрямую с заводами-изготовителями,
у вас появляется возможность купить сантехнику недорого.
Широкий ассортимент: большой выбор точно позволит вам найти подходящую модель или цвет товара,
чтобы наиболее гармонично вписать его в общий интерьер.
Удобный сервис: заказы обрабатываются в кратчайшие сроки, есть возможность выбрать
подходящий для вас вариант уведомлений (смс/звонок/почта), а оповещения о передвижении
товара позволят вам всегда быть в курсе его местоположения. Оставить онлайн-заказ вы можете
круглосуточно через корзину на сайте, а с 09:00 — 21:00 это можно также сделать через оператора.
Мы любим наших клиентов: при покупке от 3 000 р. вы получаете приятные подарки,
а для наших постоянных покупателей действуют специальные скидки.
Аккуратная доставка в срок курьером доступна по всей Республике Беларусь,
а также более чем в 1000 пунктах самовывоза в России.
Если у Вас возникли вопросы или сложности с заказом, обратитесь к оператору,
который предоставит актуальную информацию, а также проконсультирует по товарам.
Сделать это можно по телефону: +375 (33) 398 66 77.
Интернет-магазин сантехники [url=https://almoni.by/]almoni.by[/url]
[url=][/url]
Промокод на Фонбет на сегодня действующий где взять промокод для
Для получения актуального промокода на Фонбет, действующего сегодня, рекомендуется следить за обновлениями на официальном сайте или подписаться на рассылку новостей. Сегодняшние промокоды могут включать бесплатные ставки, увеличение депозита или другие бонусы. Примером такого промокода является ‘GIFT200’, который предоставляет бесплатные ставки для новых пользователей.
двп дсп мдф [url=http://www.fanera-kupit11.ru]двп дсп мдф[/url] .
железобетонные изделия каталог [url=https://kupit-zhbi.ru]железобетонные изделия каталог[/url] .
[url=][/url]
[url=https://torgdom1.ru/novoe-oborudovanie/]Новое оборудование для ресторанов и кафе[/url]
Предлагаем Новое оборудование для магазинов, ресторанов, гостиниц и других мест общественного питания и обслуживания. В нашем каталоге представлены модели различных габаритов и технических характеристик. На любой товар мы предоставляем гарантийный талон. Доставку осуществляем в течение 1-2 рабочих дней с момента заказа, либо в согласованный день. Предусмотрена оплата для юр.лиц по счету. Чтобы сделать заказ в нашей компании «ТоргХаус», соберите список товаров в корзине, и менеджер свяжется для уточнения способа оплаты и удобного времени доставки.
[url=https://torgdom1.ru/oborudovanie-bu/]БУ оборудование для ресторанов и кафе[/url]
Предлагаем Оборудование для общепита Б/У для магазинов, ресторанов, гостиниц и других мест общественного питания и обслуживания. В нашем каталоге представлены модели различных габаритов и технических характеристик. На любой товар мы предоставляем гарантийный талон.
[url=https://torgdom1.ru/proektirovanie-restoranov/]Проектирование ресторанов и кафе в Екатеринбурге[/url]
Компания «Торгхаус» успешно занимается проектированием предприятий общественного питания.
Заказав проект ресторана у нас, Вы получите:
Отдавая разработку проекта в руки профессионалов, можно быть уверенным в оптимизации и привязке всех систем. Каждое решение органично впишется в общую технологию, снижая затраты, касаемо:
Без соответствующей нормам проектной документации, невозможен запуск ресторана. Схема подводки всех систем обеспечивает безопасность работы в будущем. Соблюдение противопожарных и санитарных норм создаст почву для быстрого прохождения проверок.
Ориентировочная стоимость проектирования
– удачное планировочные решения;
– высокотехнологичную расстановку оборудования;
– верный расчет систем вентиляции и кондиционирования;
– индивидуальный подход к разработке дизайна;
– первоначальных вложений в строительство и перепланировку;
– обслуживание оборудования;
– согласование документации и прочих вопросов.
Цены на всю продукцию [url=https://torgdom1.ru/].[/url]
[url=][/url]
вавада online https://pathiaf.com
вавада вход vavada vavada актуальное
vavada casino регистрация вавада вход vavada
как заработать денег в интернете [url=www.kak-zarabotat-v-internete12.ru]как заработать денег в интернете[/url] .
капельница от похмелья на дому [url=http://snyatie-zapoya-na-domu13.ru]капельница от похмелья на дому[/url] .
Промокод Fonbet на сегодня бесплатно https://kmural.ru/news_importer/inc/aktualnue_promokodu_bukmekerskoy_kontoru_fonbet.html
Для получения бесплатного промокода на сегодня рекомендуется регулярно проверять обновления на официальном сайте Fonbet или подписаться на рассылку новостей. Примером такого промокода может быть ‘GIFT200’, который предоставляет бесплатные ставки или другие бонусы для новых пользователей. Регулярное использование таких промокодов помогает получить дополнительные преимущества и увеличивает шансы на выигрыш.
Fonbet промокод 2024 https://kmural.ru/news_importer/inc/aktualnue_promokodu_bukmekerskoy_kontoru_fonbet.html
В 2024 году Fonbet предлагает различные промокоды, которые предоставляют пользователям бонусы и привилегии. Примером такого промокода является ‘GIFT200’, который активирует бесплатные ставки и другие награды для новых игроков. Использование этих промокодов делает игру на платформе более привлекательной и выгодной.
создание сайтов под ключ недорого продвижение сайтов москва
вывод из запоя стационар [url=http://www.vyvod-iz-zapoya-v-stacionare-samara.ru]http://www.vyvod-iz-zapoya-v-stacionare-samara.ru[/url] .
seo оптимизация в москве цена продвижение сайта москва
как начать зарабатывать в интернете [url=www.kak-zarabotat-v-internete11.ru]как начать зарабатывать в интернете[/url] .
вывод из запоя в стационаре [url=https://www.vyvod-iz-zapoya-v-stacionare-samara11.ru]вывод из запоя в стационаре[/url] .
resume engineer examples sample resume of an engineer
resume builder for engineering students template for engineering resume
Мелбет – это букмекерская контора, которая дает возможность преобразовать хобби в доход. Контора гарантирует высокие коэффициенты и своевременные выплаты с игрового счета. Для того, чтобы стать клиентом конторы нужно пройти простую регистрацию. Здесь разнообразные виды спорта, широкий выбор событий и типов ставок. Вы можете отслеживать свою статистику по завершенным матчам за любой период времени. Доступ к счету можно получить с ПК, смартфона или планшета. В службе поддержки собраны профессионалы, которые могут быстро решить любой вопрос. Предлагается мелбет промокод большой выбор способов ввода средств на игровой счет.
вывод из запоя на дому санкт-петербург [url=www.vyvod-iz-zapoya-v-sankt-peterburge.ru]вывод из запоя на дому санкт-петербург[/url] .
снятие ломки нарколог [url=http://www.snyatie-lomki-narkolog.ru]снятие ломки нарколог[/url] .
seo раскрутка сайта в москве цена продвижение сайтов москва
Мелбет – международный букмекер, основанный в 2012 году. Компания получила официальную лицензию от Кюрасао, ориентирована на пользователей со всех стран мира, но в первую очередь на русскоязычных игроков. Зарегистрированные клиенты имеют прекрасную возможность пользоваться всеми преимуществами компании, принимать участие в акциях, собирать выигрышные экспрессы, получать промокоды и бесплатные ставки. Компания Мелбет регулярно предоставляет своим клиентам большое количество бонусов и промокоды. Что дает рабочий промокод мелбет бонус? Данное поощрение позволяет каждому игроку совершать бесплатные ставки, получать дополнительные денежные средства при пополнении игрового баланса. Кроме этого, благодаря промокодам сумма первого депозита может увеличиться до 100%. Букмекерская контора дарит бесплатные ставки для новых игроков и фрибеты для постоянных пользователей.
карнизы для штор с электроприводом цена [url=https://www.elektrokarniz2.ru]карнизы для штор с электроприводом цена[/url] .
seo раскрутка сайтов москва цена https://seo-5.ru
оптимизация сайта в москве недорого https://seo-5.ru
лучшие онлайн казино [url=https://www.stroy-minsk.by]лучшие онлайн казино[/url] .
интернет магазин саженцы [url=http://rodnoisad.ru]интернет магазин саженцы[/url] .
машина хендай солярис 2024 новый автомобиль хендай солярис
лучшие капперы с бесплатными прогнозами [url=www.rejting-kapperov14.ru/]лучшие капперы с бесплатными прогнозами[/url] .
промокод Melbet – это шанс для новых пользователей получить больше золота при регистрации. Используйте в Melbet промокод сегодня – и расширяйте линейку бонусов на первый депозит! Промокод Мелбет – это набор символов, который пишется в специальное поле либо при регистрации, либо в игровом кабинете букмекерской конторы. Промокод не только активирует акцию, но и делает ее еще выгоднее. Найти промо коды просто на сайтах партнеров, ютуберов, каналах блогеров и в соц.сетях. Использование кодов выгодно в независимости от того, какой именно версии букмекерской конторы беттер отдает предпочтение. Офшорные букмекер предоставляет награды на спортивные ставки и на казино. На сегодня офшорный портал предоставляет приветственный бонус новичку на первый депозит на 100% от суммы пополнения счета. Максимальная сумма, которая может быть зачислена на бонусный счет – 8000. Она легко увеличивается, при использовании в Мелбет промо кода. Если раньше поднять сумму пополнения можно было до 9100 р., то сегодня награда за первое пополнение — 10400 рублей. Депозит увеличивается не на 100%, а уже на 130%.
заказать грунт для цветов [url=https://www.dachnik18.ru]https://www.dachnik18.ru[/url] .
Промокод 1xBet на сегодня и бесплатно. Промокоды 1хбет 2024 требуется использовать те, которые предоставят игрокам самые лучшие бонусы. Каждый из них позволяет увеличить первый депозит в 2 раза, максимальная сумма увеличения – 100 долларов. Большое количество промокодов — одна из причин того, что на сайте регистрируется огромное количество новых игроков каждый день. На данный момент их количество превышает пятьсот тысяч уникальных пользователей каждый день. Действующие промокоды позволяют увеличить размер приветственных баллов до 32 500 рублей. Для этого нужно лишь активировать при регистрации имеющийся код, скопировав его в соответствующее поле. Букмекерская контора 1ХБет является одной из самых влиятельных на рынке игорного бизнеса в России и не нуждается в особом представлении. Впрочем, букмекер продолжает держать статус одного из самых щедрых и предлагает своим клиентам воспользоваться промокодами для халявы, – более подробно в этом материале https://www.jkfitness.com/wp-content/pags/1xbet___promo_code_for_registration.html.
семена овощей и цветов интернет магазин [url=http://semenaplus74.ru/]http://semenaplus74.ru/[/url] .
после капельницы от запоя на дому [url=https://kapelnica-ot-zapoya-kolomna.ru/]после капельницы от запоя на дому[/url] .
ретрит йога туры https://ретриты.рф
мужской ретрит https://ретриты.рф
ретрит в сочи https://ретриты.рф
Qu’est-ce qui donne au joueur la verification dans 1xbet?
La verification est une procedure obligatoire pour les clients du bookmaker 1xbet официальные промокоды. La procedure prevoit la verification des donnees personnelles du client pour la conformite avec les donnees reelles qui sont presentees sur la carte d’identite.
ретрит туры https://ретриты.рф
Pin up casino official Slot pick up casino website – login and play online
Ретрит http://ретриты.рф международное обозначение времяпрепровождения, посвящённого духовной практике. Ретриты бывают уединённые и коллективные; на коллективных чаще всего проводится обучение практике медитации.
Discover the world of excitement at Pin Up Casino, the world’s leading online casino. The official website Game pic up offers more than 4,000 slot machines. Play online for real money or for free using the working link today
Промокод на Фонбет при регистрации https://primacad.ru/images/pgs/?aktualnuy_promokod_fonbet_pri_registracii.html
Использование промокода при регистрации на Фонбет позволяет новым пользователям получить приветственные бонусы. Например, промокод ‘GIFT200’ предоставляет бесплатные ставки или другие награды. Ввод промокода в специальное поле при регистрации активирует бонусные предложения, что помогает новым игрокам успешно начать игру и увеличить свои шансы на выигрыш.
Le 1xbet novinka промокод, vous offre la possibilite de beneficier d’un bonus de bienvenue de 200% sur votre premier depot en Afrique, au lieu du taux habituel de 100% (voire meme de 130% au lieu de 200% dans certains pays). Vous pouvez obtenir jusqu’a 130€ ou l’equivalent dans votre devise.
Промокод для фрибета Фонбет https://autoritm-service.ru/inc/pages/aktualnuy_promokod_fonbet_pri_registracii.html
Промокоды для фрибета от Фонбет предоставляют пользователям возможность сделать бесплатные ставки. Промокод ‘GIFT200’ активирует фрибеты для новых пользователей, что позволяет сделать ставки без использования собственных средств. Эти промокоды увеличивают шансы на выигрыш и делают игру более увлекательной.
L’inscription a 1xBet est-elle disponible sans passeport?
Vous pouvez vous inscrire a как воспользоваться промокодом в 1xbet sans donnees de passeport, mais a l’avenir, dans votre compte personnel, vous devrez remplir un questionnaire indiquant votre nom, votre nom et votre date de naissance. A l’avenir, avant la premiere Conclusion, il faudra egalement passer par la verification.
промокод тото на 1хбетt utilisez le code bonus pour obtenir un bonus VIP de 100% jusqu’a 130€ pour les Paris sportifs, ainsi qu’un bonus de casino de 1950 € + 150 tours de machines a sous. En utilisant le code promotionnel, vous pouvez vous attendre a ce que vos gains soient aussi eleves que dans le cas du plus grand bookmaker 1xbet. Tous les joueurs des pays suivants peuvent utiliser le code lors de l’inscription et recevoir un bonus de bienvenue:
1x bet promocode
A 1x Bet bonus code is a code that unlocks bonuses such as deposit matches, free bets, or free spins. These codes are often provided as part of welcome offers or special promotions and can be entered during registration or when making a deposit.
Combien de temps faut-il pour retirer des fonds sur une carte Visa ou MasterCard?
Le retrait des fonds sur les cartes bancaires des systemes de paiement Visa et Mastercard depend du montant de la transaction, du jour de la semaine et de l’heure de la journee.Code Promo Republique du Congo En regle generale, les fonds arrivent sur le compte indique dans un delai de 24 heures.
1xBet
A 1xBet promotion code is an alphanumeric string that unlocks special promotions on the platform, such as free bets, deposit bonuses, or free spins. These codes are often provided as part of special events or partnerships.
Le Code Promo Burundi vous offre un bonus de bienvenue pour une simple inscription allant jusqu’a 130 $. Copiez simplement le code promotionnel et utilisez-le lors de l’inscription. Ceci est la version la plus volumineuse de l’enregistrement, cependant, c’est l’enregistrement complet et ouvre le joueur un acces complet aux fonctionnalites de la plate-forme de jeu.
эскорт услуги в москве девушки эскорт услуги частные объявления москва
эскорт в москве цены услуга агентство эскорт услуг москва
эскорт в москве цены услуга мужские эскорт услуги в москве
эскорт услуги девушки москва элитные эскорт услуги москва
лаки джет игра лаки джет на деньги
himera searching bot химера серч бот
эскорт порно услуги в москве услуги эскорта в москве для мужчин
лаки джет регистрация lucky jet регистрация
как найти blacksprut blacksprut зеркала актуальные
Как поднять настроение подруге с помощью смешного анекдота
bot lucky jet lucky jet на деньги
Лечебно-оздоровительный массаж Ивантеевка по выгодным ценам. Стоимость процедуры, порядок проведения, запись на прием.
1xBet
The 1xBet welcome bonus is a special offer available to new users when they sign up on the platform. This bonus usually includes a 100% match on the first deposit, up to a certain amount, giving new users more funds to start betting.
4rabet promo code today telegram: The 4rabet bonus promo code gives both new and existing users access to special bonuses. These can range from first deposit bonuses to free bets or free spins in the casino. Promo codes are often available through official 4rabet channels or affiliate programs.
4rabet free bet promo code: A code that activates special bonus offers, ranging from free spins in the casino to matched deposits on sports bets. These codes are regularly updated and offer varied rewards.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://www.binance.com/en/register?ref=JHQQKNKN
Что такое смешные картинки и как они появились
1xBet
1xBet offers promo codes for users in Pakistan, providing them with bonuses like free bets, deposit matches, or free spins. These codes enhance the betting experience for Pakistani users.
Смешные анекдоты в приложении
Всё шуточки
Забавные приколы на злобу дня
Поднимите себе настроение!
Что такое анекдот? Почему мы любим прикольные анекдоты? История. Читайте об этом
статью
Самые смешные анекдоты на нашем сайте.
Смешные видео на любой вкус
Поднимите себе настроение!
Смешные мемы http://prikoly-shutki.ru/kartinki-prikolnye Что такое мемы.
Бесплатный промокоды на ставки ищет каждый потенциальный клиент компании. Почему? Мало кто откажется от щедрой приветственной награды, позволяющей увеличить сумму первого депозита, заработав до ?9100 бонуса (с 24 апреля бонус увеличился до 10 400). Промокоды – это маркетинговый инструмент, с помощью которого рекламные партнеры букмекера привлекают новых бетторов. Поэтому в современной практике сам букмекер редко распространяет коды, за исключением флагманских акций или раздачи купонов в рамках специальных ивентов. Не все бонусы предполагают наличие рекламного кода. Для активации большинства из них достаточно просто пополнить счет или делать ставки на спорт, получая за это баллы активности. В последующем есть возможность в рамках программы лояльности БК «Мелбет» обменивать баллы на коды для бесплатных ставок (фрибеты) или на реальные денежные средства. Раздобыть промокод Melbet Вы всегда сможете на нашем сайте. При этом Вы можете быть уверенными в том, что это именно актуальное предложение. Также рекомендуем подписаться на информационную рассылку БК, где компания при помощи SMS и почтовых уведомлений держит в курсе событий любителей ставок.
Как поднять настроение с помошью анекдота. Свежие анекдоты
http://azclan.ru/forums/users/vychislavyakov
sollers атлант sollers atlant фургон
sollers атлант sollers atlant купить
Как поднять настроение с помошью смешных картинок. ржачные картинки
http://angelteam.uv.ro/profile.php?mode=viewprofile&u=216647
актуальный промокод стоит ввести для повышенного бонуса на первый депозит. Большинство букмекерских контор используют такую практику привлечения новых игроков и выдают значительные бонусы. Актуальный промокод Мелбет на 2024 год – RS777. Ввести его могут исключительно новые игроки, у которых еще нет аккаунта в Melbet. Не рекомендуем идти на хитрость и заново проходить процесс регистрации, так как служба безопасности тщательно отслеживает мультиаккаунты. Максимальная сумма бонуса при использовании промокода Мелбет – 10400 рублей. Это значит, что при вводе средств на баланс после регистрации новому игроку будет зачислено еще 130% от первого депозита в качестве поощрения от букмекера.
buy mechanical alarm clock buy sunrise imitation alarm clock
1xBet
1xBet sometimes offers no deposit bonus codes, allowing users to claim bonuses without making a deposit. These codes are highly sought after as they provide a risk-free way to explore the platform and win real money.
Кракен сайт – это онлайн-площадка, работающая в скрытых сетях интернета, где пользователи могут покупать и продавать различные виды наркотиков. Для доступа к Kraken onion необходимо использовать специальное программное обеспечение, позволяющее обходить блокировки и обеспечивающее анонимность пользователей.
large clocks face clocks
Профессиональный сервисный центр по ремонту кофемашин по Москве.
Мы предлагаем: мастер по ремонту кофемашин москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Сайт о биодобавках https://биодобавки.рф подробная информация о видах добавок, их действии и пользе. Рекомендации по выбору для поддержки здоровья на основе актуальных исследований.
Сайт о биодобавках https://биодобавки.рф предлагает проверенную информацию о натуральных добавках для здоровья. Узнайте, как выбрать подходящие средства для улучшения иммунитета, повышения энергии и поддержания активного образа жизни. Подробные описания и советы помогут сделать осознанный выбор.
Как поднять настроение с помошью приколов. прикольные мемы
http://fruit-impex.by/user/vychislavyakov/
Актуальный список промокодов в Мелбет при регистрации в 2024 году. Действующий бонус код для новичков и постоянных пользователей. Актуальный промокод в Melbet на фрибет. В Melbet подарки ждут каждого зарегистрированного пользователя. Для новичков подготовлены бонусы за первую регистрацию. Постоянные клиенты могут получать поощрения в акциях и бонусных программах. Промокоды бк Мелбет позволяет игрокам принимать участие в акциях и получать разные поощрения, к примеру, бесплатные ставки. В нашей статье мы узнаем, где взять правила промокода, как его применять при создании аккаунта и ставках.
Сайт предоставляет информацию о биодобавках http://биодобавки.рф состав, польза и рекомендации по применению. Здесь вы найдёте обзоры эффективных добавок для улучшения здоровья, иммунитета и энергии на основе научных данных и экспертных мнений.
1xBet
A 1x Bet bonus code is a code that unlocks bonuses such as deposit matches, free bets, or free spins. These codes are often provided as part of welcome offers or special promotions and can be entered during registration or when making a deposit.
Смешные анекдоты. История анекдотов.
Используя промокод Мелбет при регистрации, игроки получают доступ к участию в приветственной бонусной программе. Полученные привилегии можно использовать, заключая ставки на ММА и другие виды спорта. Ниже рассказываем более подробно о том, какие бонусы предложены на сайте и как их отыграть. Бонусные программы нацелены на то, чтобы обеспечить для игроков возможность получить безболезненный опыт игры на сайте и сгладить первые возможные неудачи. Регистрируйтесь на платформе букмекера, активируйте промокоды на слоты в и пользуйтесь бонусными предложениями от букмекера Мелбет, чтобы получать больше положительных эмоций при заключении пари.
Сайт предоставляет информацию о биодобавках биодобавки.рф состав, польза и рекомендации по применению. Здесь вы найдёте обзоры эффективных добавок для улучшения здоровья, иммунитета и энергии на основе научных данных и экспертных мнений.
Свежие приколы
Как появились приколы. Узнайте, как поднять себе настроение!
Смешные анекдоты. Что такое анекдот.
[url=][/url]
Временная регистрация в СПб: Быстро и Легально!
Ищете, где оформить временную регистрацию в Санкт-Петербурге?
Мы гарантируем быстрое и легальное оформление без очередей и лишних документов.
Ваше спокойствие – наша забота!
Минимум усилий • Максимум удобства • Полная легальность
Свяжитесь с нами прямо сейчас!
Временная регистрация
[url=][/url]
Букмекерская компания “Мелбет”, как, собственно, и десятки других операторов акцентирует внимание на бонусах и других привилегиях для своих игроков. Промокод – это один из вариантов привлечения новых игроков. Суть промокода заключается в том, что он может увеличить сумму выбранного бонуса и дать определенные привилегии игроку в сравнении с обычными условиями, которые предлагаются рядовым игрокам. Сегодня можно найти предложения на разных ресурсах. К примеру, это может быть какой-то блогер на видеохостинге YouTube. Довольно часто у популярных личностей можно встретить рекламные интеграции, где они бесплатно предлагают воспользоваться melbet промокод при регистрации и получить дополнительные привилегии при получении бонуса. Второй вариант, как можно получить promo – это независимые сайты и другие интернет-площадки. Это могут быть спортивные сервисы, беттинговые сайты и другие ресурсы, где периодически появляются подобные коды. Ну и третий вариант – это официальный сайт букмекерской компании. На сайте часто появляются новые акции и бонусы. Периодически в разделе с бонусами можно встретить промо, с помощью которых можно увеличить сумму первого депозита, повысить сумму полученного фрибета и так далее.
His bare ass melts to the lid of the toilet bowl. He sweats from the steam and the exertions from his continued pounding of the fierceness of his cock. He wiggles as his ass opens, squeaking on the plastic surface of the thrown lid, as he takes whiffs from the cum soaked pouch of the jock that covers his face. [url=https://arturzasada.pl/]sex porn mom[/url] Garrett resumes the fondling of his cock while he takes long drawn-out whiffs from his sweat, piss and cum stained jockstrap.
[url=][/url]
Временная регистрация в Санкт-Петербурге: Быстро и Легально!
Ищете, где оформить временную регистрацию в СПб?
Мы гарантируем быстрое и легальное оформление без очередей и лишних документов.
Ваше спокойствие – наша забота!
Минимум усилий • Максимум удобства • Полная легальность
Свяжитесь с нами прямо сейчас!
Временная регистрация в СПб
[url=][/url]
Прикольные анекдоты. История анекдотов.
Бонус Код Букмекерской Мелбет При Регистрации – это код для новых пользователей, так как он дает денежные призы на первый депозит новым игрокам. С их помощью вы получите на 30% больше возврата средств, чем при стандартной регистрации, или фрибет. Букмекерская контора Мелбет работает на рынке беттинга уже довольно долго. За время существования она успела получить доверие многотысячной аудитории игроков и сформировать четкую стратегию взаимодействия с клиентами. Для всех участников БК доступны различные поощрения, подарки и акции. Среди них – melbet промокод при регистрации, расширяющий список привилегий для нового, или активного пользователя.
Смешные анекдоты. Что такое анекдот.
“That your jockstrap on the floor next to you, son?” His dad asks. “But you didn’t though, did you, son?”
Как поддерживать хорошее настроение с помощью смешных приколов
Как поддерживать хорошее настроение с помощью забавных приколов
Как поддерживать хорошее настроение с помощью забавных приколов
Сервисный центр предлагает ремон объектива panasonic lumix dmc-gm1 замена объектива panasonic lumix dmc-gm1
выкуп аварийных автомобилей выкуп кредитных авто
Прикольные анекдоты https://shutochki.wordpress.com/2024/09/27/smeshnye-anekdoty/
выкуп автомобиля после лизинга https://vikup-avto2.ru
Indian porn https://desiporn.one in Hindi. Only high-quality porn videos, convenient search and regular updates.
Смешные анекдоты https://shutochki.wordpress.com/2024/09/27/smeshnye-anekdoty/
Porn videos https://thetittyfuck.com watch online for free. A selection of high-quality porn videos, a collection of sex videos
1x Bet Promo Codes https://actuchomage.org/includes/wkl/code_promo_69.html
1x Bet promo codes are alphanumeric strings that unlock bonuses on the 1xBet platform, such as free bets, deposit matches, or free spins. These codes are often provided as part of welcome offers or special promotions.
“I am fully grown now, Father.” He says in a heated rebuttal to his father’s words. Exactly a week after, daddy texted me with a different tone saying, “ get your ass ready tonight cause daddy is coming to your place tonight.” He was usually really sweet and nice, I was shot when I got the message. But automatically I said, “ yes daddy!” I guess I am a slutty whore for him right at the beginning as I knew my place where is always going to be inferior.
1xBet Best Promo Code https://idematapp.com/wp-content/pages/1xbet_promo_codes_free_bonus_offers.html
The best promo codes for 1xBet are those that offer significant bonuses, such as deposit matches, free bets, or free spins. These codes can greatly enhance the betting experience by providing extra value for both new and existing users.
Смешные анекдоты про евреев
Подними настроение
продвижение в поиске wildberries продвижение товаров на wb
продвижение товара на вайлдберриз продвижение товаров на вайлдберриз услуги
Федерация – это проводник в мир покупки запрещенных товаров, можно купить гашиш, купить мефедрон, купить кокаин, купить меф, купить экстази, купить альфа пвп, купить гаш в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
Свежие мемы
Лучшие анекдоты про евреев
Отдохни и посмейся
[url=][/url]
[b]Продажа мини-погрузчиков Lonking[/b]
Продажа мини-погрузчиков Lonking на территории России от официального
дистрибьютора. Новая многофункциональная техника для любых задач.
Наши машины предназначены для того, чтобы упростить вашу работу:
от строительных площадок до складских операций.
Высокая эффективность, надежность и инновационные решения — все,
что вам нужно для успешных проектов. Погрузите свой бизнес в будущее
с мини-погрузчиками Lonking!
47% российских покупателей выбрали мини-погрузчики Lonking в 2023 году
продано более 1200 единиц.
Lonking
[url=][/url]
He does not answer but tilts his head down in an almost subservient nature to his father. “Stoke it, boy! Stroke it! Stroke that beautiful cock!” His father demands as his own cock draws on the wet interior of the glass enclosure shower. “Pound it harder, boy! Pound it harder!”
betting welcome offers: Special offers available on betting sites, such as welcome bonuses, free bets, or cashback offers, aimed at attracting and rewarding users.
Лучшие анекдоты и шутки
Подними настроение
Веселые анекдоты и шутки
Подними себе настроение
автостекло замена продажа в спб лобовое стекло с установкой в спб
sports betting promo code: Special codes provided by sportsbooks that give players access to bonuses such as deposit matches, free bets, or enhanced odds on sports events.
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
игра gates of olympus gates of olympus играть
Смешные анекдоты
Подними настроение
промокод мостбет при регистрации рабочий промокод мостбет при регистрации
gates of olympus слот гейтс оф олимпус автомат
мостбет промокод на сегодня рабочий 2024 мостбет промокод AZ3202 рабочий
Online casino https://spyphonesoftware.net/2024/10/07/slotspalace-suomi-casino-play-now-win-big with high bonuses, roulette and slots, instant payouts. Register on the official mirror.
Как поднять себе настроение? Почитайте
прикольные анекдоты и поделитесь с близкими.
Сервисный центр предлагает ремонт ginzzu r8 dual ремонт ginzzu r8 dual
Online casino https://joho5.biz/2024/10/06/1win-benin-your-gateway-to-online-betting with high bonuses, roulette and slots, instant payouts. Register on the official mirror.
lucky jet сигналы lucky jet регистрация
1xBet Free Bet Promo Code https://idematapp.com/wp-content/pages/1xbet_promo_codes_free_bonus_offers.html
Free bet promo codes from 1xBet allow users to place bets without risking their own money. These codes are often part of special promotions and are popular among users looking to try out the platform or specific bets.
вывод из запоя цены ростов-на-дону [url=www.vyvod-iz-zapoya-rostov16.ru]www.vyvod-iz-zapoya-rostov16.ru[/url] .
вывод из запоя в ростове [url=https://vyvod-iz-zapoya-rostov15.ru/]вывод из запоя в ростове[/url] .
[url=][/url]
Продажа мини-погрузчиков Lonking
Продажа мини-погрузчиков Lonking на территории России от официального
дистрибьютора. Новая многофункциональная техника для любых задач.
Наши машины предназначены для того, чтобы упростить вашу работу:
от строительных площадок до складских операций.
Высокая эффективность, надежность и инновационные решения — все,
что вам нужно для успешных проектов. Погрузите свой бизнес в будущее
с мини-погрузчиками Lonking!
47% российских покупателей выбрали мини-погрузчики Lonking в 2023 году продано более 1200 единиц.
Мини-погрузчики Lonking
[url=][/url]
Прикольные картинки. Как они появились.
Авиатор игра Авиатор регистрация
buy an apartment in a new building prices buy inflatable balloons
Aviator регистрация Авиатор игра
вывод из запоя в стационаре ростова [url=http://vyvod-iz-zapoya-rostov18.ru/]вывод из запоя в стационаре ростова[/url] .
вызвать нарколога на дом [url=https://narkolog-na-dom-krasnodar15.ru/]https://narkolog-na-dom-krasnodar15.ru/[/url] .
Смешные картинки. Как они появились.
вывод из запоя стационар ростов [url=http://www.vyvod-iz-zapoya-rostov17.ru]вывод из запоя стационар ростов[/url] .
1xBet New Promo Code https://actuchomage.org/includes/wkl/code_promo_69.html
1xBet frequently releases new promo codes that provide users with updated bonuses and promotions. These codes can include anything from free bets to deposit matches and are available to both new and existing users.
Прикольные анекдоты.
Casino and slot https://forest2001.net/2024/10/06/how-to-use-1win-benin-for-maximum-profit machines online. Play slot machines with bonus, casino for money. Registration and login to the working mirror
Free online https://thetranny.com porn videos and movies. Only girls with dicks. On our site there are trans girls for every taste!
Porn video https://zeenite.com watch online from pages for free in FullHD quality. Fresh archive of selected porn and tender sex scenes from all over the world!
Смешные пошлые анекдоты.
After I serve daddy’s left one, I was about to move to the right foot. While He stopped me, stood up, and walked towards the couch, he said “Crawling right after me.” I followed daddy. My nose was where daddy’s ass was. I was staring at that crotch while I was crawling, and I didn’t realize daddy stopped one of a sudden in front of the bathroom. My nose is slightly right into that dreaming ass crack.
вывод из запоя капельница краснодар [url=http://vyvod-iz-zapoya-krasnodar15.ru]вывод из запоя капельница краснодар[/url] .
Вызов сантехника https://santekhnik-moskva.blogspot.com/p/v-moskve.html на дом в Москве и Московской области в удобное для вас время. Сантехнические работы любой сложности, от ремонта унитаза, устранение засора, до замены труб.
tagged instagram viewer [url=https://anonimstories.com ]https://anonimstories.com [/url] .
нарколог на дом недорого [url=https://narkolog-na-dom-krasnodar17.ru]нарколог на дом недорого[/url] .
нарколог на дом краснодар [url=http://www.narkolog-na-dom-krasnodar16.ru]нарколог на дом краснодар[/url] .
Прикольные пошлые анекдоты.
bs02.at
Веселые приколы и картинки https://teletype.in/@anekdoty/prikoly-nastroenie.
Свежие анекдоты https://telegra.ph/Smeshnye-anekdoty-10-09.
[url=][/url]
Интернет-магазин плитки и керамики «ИнфоПлитка»
Интернет-магазин керамической плитки и керамогранита «Infoplitka» (infoplitka.ru)
предлагает широкий ассортимент высококачественной плитки и керамогранита от ведущих производителей.
Мы стремимся предложить нашим клиентам только лучшее, поэтому в ассортименте представлены товары,
отвечающие самым высоким стандартам качества и дизайна.
Мы понимаем, что выбор керамической плитки и керамогранита – это важный этап в создании
комфортного и стильного интерьера. Поэтому наша команда профессионалов готова помочь вам в
подборе идеального варианта для вашего проекта. Независимо от того, нужны ли вам плитка
для ванной комнаты, кухни, гостиной, или же керамогранит для облицовки пола, вы всегда найдете
у нас разнообразные и актуальные коллекции, соответствующие последним тенденциям в области
дизайна интерьеров.
Официальный сайт «ИнфоПлитка»
[url=][/url]
как вывести из запоя против воли [url=https://www.vyvod-iz-zapoya-krasnodar16.ru]как вывести из запоя против воли[/url] .
Веселые анекдоты про евреев https://sites.google.com/view/shutki-anekdoty/%D0%B0%D0%BD%D0%B5%D0%BA%D0%B4%D0%BE%D1%82%D1%8B-%D0%BF%D1%80%D0%BE-%D0%B5%D0%B2%D1%80%D0%B5%D0%B5%D0%B2.
лечение запоев на дому [url=www.vyvod-iz-zapoya-ekaterinburg14.ru/]www.vyvod-iz-zapoya-ekaterinburg14.ru/[/url] .
Смешные фотоприколы https://prikoly-tut.blogspot.com/2024/10/smeshnye-kartinki.html.
вывод из запоя кодирование краснодар [url=https://vyvod-iz-zapoya-krasnodar17.ru/]вывод из запоя кодирование краснодар[/url] .
срочный вывод из запоя [url=https://www.vyvod-iz-zapoya-ekaterinburg15.ru]срочный вывод из запоя[/url] .
Свежие картинки с надписями https://prikoly-tut.blogspot.com/2024/10/smeshnye-kartinki.html.
Веселые приколы за день https://prikolnyekartinki.mystrikingly.com/blog/0ade1e0d9a9.
Свежие анекдоты https://vk.com/vseshutochki.
Веселые пошлые анекдоты https://ru.pinterest.com/vseshutochki/%D0%BF%D0%BE%D1%88%D0%BB%D1%8B%D0%B5-%D0%B0%D0%BD%D0%B5%D0%BA%D0%B4%D0%BE%D1%82%D1%8B/.
bs2site.at
нарколог на дом екатеринбург цены [url=https://vyvod-iz-zapoya-ekaterinburg16.ru]нарколог на дом екатеринбург цены[/url] .
Веселые приколы https://prikolyshutki.wordpress.com/2024/10/11/prikoly-umor/.
[url=][/url]
Найти специалиста по независимой экспертизе и оценке!
Сайт-агрегатор компаний и услуг в сфере независимой экспертизы и оценки.
Мы создали этот проект, чтобы помочь вам найти надежных и опытных профессионалов
для решения ваших задач.
Главная цель — сделать процесс поиска специалистов по независимой экспертизе
и оценке максимально простым и эффективным. Мы стремимся предоставить вам
доступ к компаниям, которые гарантируют высокое качество услуг.
С нами вы сможете быстро найти нужного эксперта и сравнить различные предложения.
На нашем сайте собраны карточки компаний, каждая из которых содержит подробную
информацию о предоставляемых услугах. Посетители могут фильтровать предложения
по различным критериям:
Локация
Направление экспертизы
Стоимость услуг
Отзывы клиентов
Наш сайт Специалисты по независимой экспертизе и оценке.
[url=][/url]
работа казахстан [url=http://umicum.kz]работа казахстан[/url] .
требуется в алматы [url=http://trudvsem.kz]требуется в алматы[/url] .
работа на час астана [url=https://sitsen.kz/]работа на час астана[/url] .
Свежие приколы https://prikolyshutki.wordpress.com/2024/10/11/prikoly-umor/.
Свежие приколы https://teletype.in/@anekdoty/prikoly-nastroenie.
bs02.at
bs2site
Свежие приколы http://anekdotshutka.ru.
Смешные приколы и анекдоты http://anekdotshutka.ru.
Смешные приколы и анекдоты http://anekdotshutka.ru.
bs2best at
франшиза купить готовый бизнес [url=https://www.franshizy12.ru]франшиза купить готовый бизнес[/url] .
франшиза [url=https://www.franshizy11.ru]франшиза[/url] .
выведение из запоя в сочи [url=http://vyvod-iz-zapoya-sochi16.ru/]http://vyvod-iz-zapoya-sochi16.ru/[/url] .
Веселые анекдоты https://teletype.in/@anekdoty/smeshnye-anekdoty.
Свежие анекдоты https://prikolyshutki.wordpress.com/2024/10/16/smeshnye-anekdoty/.
https://sudvgorode.ru/sudy-obshhej-yurisdiktsii/
bs2best at
Смешные анекдоты https://teletype.in/@anekdoty/smeshnye-anekdoty.
вывод из запоя сочи [url=www.vyvod-iz-zapoya-sochi15.ru]вывод из запоя сочи[/url] .
Платформа для ставок 1вин с множеством событий и азартных игр. Удобный интерфейс, моментальные выплаты и привлекательные бонусы делают ставки ещё увлекательнее. Откройте мир азарта и выигрышей с надежным сервисом и постоянными акциями для пользователей.
московский музей анимации музей анимации измайлово
Платформа для ставок 1win с множеством событий и азартных игр. Удобный интерфейс, моментальные выплаты и привлекательные бонусы делают ставки ещё увлекательнее. Откройте мир азарта и выигрышей с надежным сервисом и постоянными акциями для пользователей.
1win apk android [url=https://www.1winapkdownload1win.com]https://www.1winapkdownload1win.com[/url] .
Свежие анекдоты http://anekdot-top.ru.
вывод из запоя на дому в сочи [url=http://www.vyvod-iz-zapoya-sochi17.ru]вывод из запоя на дому в сочи[/url] .
Смешные анекдоты http://anekdot-top.ru.
Стоимость дипломов высшего и среднего образования и процесс их получения
driveme.rusff.me/viewtopic.php?id=2369#p105425
куплю диплом качество [url=https://orik-diploms.ru/]orik-diploms.ru[/url] .
Веселые приколы, шутки и картинки https://teletype.in/@anekdoty/prikoly-nastroenie.
Свежие приколы и анекдоты https://teletype.in/@anekdoty/prikoly-nastroenie.
купить высшее образование цена [url=https://landik-diploms.ru/]купить высшее образование цена[/url] .
Веселые приколы http://shutki-anekdoty.ru/.
вывод из запоя ростов на дону [url=http://vyvod-iz-zapoya-rostov115.ru/]вывод из запоя ростов на дону[/url] .
бизнес франшиза [url=www.franshizy13.ru/]бизнес франшиза[/url] .
Как получить диплом стоматолога быстро и официально
Свежие приколы http://shutki-anekdoty.ru/.
Свежие приколы, шутки и картинки http://shutki-anekdoty.ru/.
Вопросы и ответы: можно ли быстро купить диплом старого образца?
naturetour.ru/club/user/186/blog/2205
Смешные приколы, шутки и картинки http://shutki-anekdoty.ru/.
Удивительно, но купить диплом кандидата наук оказалось не так сложно
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
купить диплом официального сайта [url=https://arusak-diploms.ru/]arusak-diploms.ru[/url] .
Узнайте, как безопасно купить диплом о высшем образовании
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
mkbox.ru/communication/forum/user/74975
шторный карниз с электроприводом [url=www.elektrokarniz-dlya-shtor11.ru/]шторный карниз с электроприводом[/url] .
купить диплом цена [url=https://russa-diploms.ru/]купить диплом цена[/url] .
Веселые приколы, шутки и картинки http://shutki-anekdoty.ru/.
Веселые анекдоты http://shutki-anekdoty.ru/anekdoty.
купить диплом о высшем образовании с занесением в реестр [url=https://landik-diploms.ru/]купить диплом о высшем образовании с занесением в реестр[/url] .
Свежие анекдоты http://shutki-anekdoty.ru/anekdoty.
Веселые картинки http://shutki-anekdoty.ru/kartinki-prikolnye.
вывод из запоя в стационаре ростов [url=https://vyvod-iz-zapoya-rostov116.ru]вывод из запоя в стационаре ростов[/url] .
neon54 review
Прикольные картинки http://shutki-anekdoty.ru/kartinki-prikolnye.
Как правильно купить диплом колледжа и пту в России, подводные камни
Легальная покупка школьного аттестата с упрощенной программой обучения
oymalitepe.net/modules.php?name=Your_Account&op=userinfo&username=urewevo
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
синий диплом купить [url=https://orik-diploms.ru/]orik-diploms.ru[/url] .
купил диплом [url=https://server-diploms.ru/]купил диплом[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании
алкоголизм лечение вывод из запоя ростов [url=http://vyvod-iz-zapoya-rostov117.ru]http://vyvod-iz-zapoya-rostov117.ru[/url] .
Смешные видео http://shutki-anekdoty.ru/videos.
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Как приобрести аттестат о среднем образовании в Москве и других городах
laviehub.com/blog/kupit-diplom-562364fpzd
Официальная покупка аттестата о среднем образовании в Москве и других городах
Покупка диплома о среднем полном образовании: как избежать мошенничества?
onelife.forumex.ru/viewtopic.php?f=3&t=138
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Прикольные шутки http://shutki-anekdoty.ru/korotkie-anekdoty.
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: телефон ремонт
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт старых телефонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Свежие и смешные шутки http://shutki-anekdoty.ru/korotkie-anekdoty.
Быстрое обучение и получение диплома магистра – возможно ли это?
minecraftcommand.science/forum/general/topics/f02110b5-403f-4bc8-8c30-5b2ece92b5e9
Покупка диплома о среднем полном образовании: как избежать мошенничества?
купить диплом о высшем образовании в барнауле [url=https://landik-diploms.ru/]landik-diploms.ru[/url] .
Профессиональный сервисный центр по ремонту компьютеров и ноутбуков в Москве.
Мы предлагаем: срочный ремонт макбук
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Веселые приколы, шутки и картинки http://shutki-anekdoty.ru/.
Где и как купить диплом о высшем образовании без лишних рисков
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: где можно починить телефон
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
можно ли купить диплом в москве [url=https://prema-diploms.ru/]можно ли купить диплом в москве[/url] .
Узнайте, как приобрести диплом о высшем образовании без рисков
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт мобильных устройств
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
купить диплом закрытого вуза [url=https://server-diploms.ru/]купить диплом закрытого вуза[/url] .
Официальная покупка диплома вуза с сокращенной программой в Москве
Профессиональный сервисный центр по ремонту игровых консолей Sony Playstation, Xbox, PSP Vita с выездом на дом по Москве.
Мы предлагаем: ремонт игровой консоли
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: диагностика сотовых телефонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Официальная покупка школьного аттестата с упрощенным обучением в Москве
1с купить официальный сайт цена [url=https://kupit-1s11.ru/]1с купить официальный сайт цена[/url] .
купить диплом в петропавловске-камчатском [url=https://man-diploms.ru/]man-diploms.ru[/url] .
Купить диплом о среднем полном образовании, в чем подвох и как избежать обмана?
mohotango.com/diplom-kupit-954813kj
Всё, что нужно знать о покупке аттестата о среднем образовании
polegasm.net/index.php/forum/welcome-mat/152032
купить диплом в ельце [url=https://russa-diploms.ru/]russa-diploms.ru[/url] .
Свежие приколы и анекдоты http://shutki-anekdoty.ru/.
Профессиональный сервисный центр по ремонту компьютерных видеокарт по Москве.
Мы предлагаем: ремонт видеокарты москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
сколько стоит диплом [url=https://orik-diploms.ru/]сколько стоит диплом[/url] .
Как получить диплом техникума с упрощенным обучением в Москве официально
купить диплом старого образца в кирове [url=https://arusak-diploms.ru/]arusak-diploms.ru[/url] .
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт телефона москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
услуги домов престарелых [url=www.xn—-1-6cdshb2cetnmcmp6c5f.xn--p1ai]услуги домов престарелых[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт телефонов в москве рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
сколько стоит реклама в лифте https://reklama-v-liftah-msk.ru
Как приобрести диплом о среднем образовании в Москве и других городах
Свежие и смешные анекдоты http://shutki-anekdoty.ru/anekdoty.
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
laviehub.com/blog/kupit-diplom-978564arcx
Профессиональный сервисный центр по ремонту игровых консолей Sony Playstation, Xbox, PSP Vita с выездом на дом по Москве.
Мы предлагаем: профессиональный ремонт игровых консолей
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
реклама в лифте стоимость https://reklama-v-liftah-msk.ru
Ремонт Коттеджей Алматы – ТОО “Ваш-Ремонт” помжет Вам от идеи до реализации. Надежно, качественно и в срок. Мы предлагаем полный спектр услуг: от дизайна интерьера до отделочных работ любой сложности. Доверьте свой ремонт опытным специалистам и получите идеальный результат.
Прикольные анекдоты http://shutki-anekdoty.ru/anekdoty.
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
physmathforum.flybb.ru/viewtopic.php?f=12&t=993
вывод из запоя цены сочи [url=https://vyvod-iz-zapoya-sochi16.ru/]вывод из запоя цены сочи[/url] .
Профессиональный сервисный центр по ремонту компьютерных видеокарт по Москве.
Мы предлагаем: ремонт видеокарт москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Официальная покупка диплома вуза с упрощенной программой обучения
Свежие анекдоты http://shutki-anekdoty.ru/anekdoty.
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
investicos.com/uncategorized/kupit-diplom-218363osjn
buy real instagram followers
The followers I bought seemed authentic at first, but engagement is still low.
Web Tasarım Fiyatları
Web tasarim fiyatlari piyasaya gore uygun. Butcemi asmadilar, kaliteli is cikti.
Всё, что нужно знать о покупке аттестата о среднем образовании
купить диплом 2007 [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
быстрый вывод из запоя в стационаре [url=http://vyvod-iz-zapoya-sochi17.ru/]быстрый вывод из запоя в стационаре[/url] .
Получите доступ к ставкам через официальное приложение 888Starz
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://accounts.binance.com/en-IN/register?ref=UM6SMJM3
Всё о покупке аттестата о среднем образовании: полезные советы
Как получить диплом стоматолога быстро и официально
Официальная покупка аттестата о среднем образовании в Москве и других городах
заказать диплом [url=https://server-diploms.ru/]server-diploms.ru[/url] .
лечение алкоголизма на дому [url=www.snyatie-zapoya-na-domu15.ru/]лечение алкоголизма на дому[/url] .
Аттестат школы купить официально с упрощенным обучением в Москве
капельница от похмелья купить [url=snyatie-zapoya-na-domu16.ru]капельница от похмелья купить[/url] .
капельница на дом круглосуточно [url=https://snyatie-zapoya-na-domu17.ru/]капельница на дом круглосуточно[/url] .
Как не попасть впросак при покупке диплома колледжа или ПТУ в России
Как правильно купить диплом колледжа и пту в России, подводные камни
купить диплом в глазове [url=https://man-diploms.ru/]man-diploms.ru[/url] .
диплом о высшем образовании [url=https://landik-diploms.ru/]landik-diploms.ru[/url] .
Диплом пту купить официально с упрощенным обучением в Москве
obshenie.flybb.ru/viewtopic.php?f=2&t=897
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Стоимость дипломов высшего и среднего образования и как избежать подделок
Официальное получение диплома техникума с упрощенным обучением в Москве
laviehub.com/blog/kupit-diplom-144436nnhq
Покупка школьного аттестата с упрощенной программой: что важно знать
Быстрое обучение и получение диплома магистра – возможно ли это?
rpinnovative.1stbb.ru/viewtopic.php?f=8&t=682
где купить высшее образование [url=https://orik-diploms.ru/]где купить высшее образование[/url] .
Как оказалось, купить диплом кандидата наук не так уж и сложно
mosserg.flybb.ru/viewtopic.php?f=2&t=310
вывод из запоя цены санкт-петербург [url=www.vyvod-iz-zapoya-v-sankt-peterburge15.ru/]www.vyvod-iz-zapoya-v-sankt-peterburge15.ru/[/url] .
Сколько стоит диплом высшего и среднего образования и как это происходит?
yexanin202.ixbb.ru/viewtopic.php?id=308#p308
Попутный груз — это удобный способ доставки груза по доступной цене
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт iphone в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
выведение из запоя санкт петербург [url=www.azithromycinum.ru/]www.azithromycinum.ru/[/url] .
Как официально купить диплом вуза с упрощенным обучением в Москве
Как получить диплом стоматолога быстро и официально
lms.jolt.io/blog/index.php?entryid=3170
Пошаговая инструкция по официальной покупке диплома о высшем образовании
купить чистые дипломы [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфонов в москве недорого
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
выведение из запоя спб [url=http://vyvod-iz-zapoya-v-sankt-peterburge17.ru/]выведение из запоя спб [/url] .
Официальная покупка аттестата о среднем образовании в Москве и других городах
вывод из запоя в клинике спб [url=www.vyvod-iz-zapoya-v-sankt-peterburge16.ru]вывод из запоя в клинике спб[/url] .
вывод из запоя в клинике спб [url=www.vyvod-iz-zapoya-v-sankt-peterburge18.ru]вывод из запоя в клинике спб[/url] .
Официальное получение диплома техникума с упрощенным обучением в Москве
купить диплом техникума в омске [url=https://russa-diploms.ru/]russa-diploms.ru[/url] .
Смешные мемы http://shutki-anekdoty.ru/kartinki-prikolnye.
бытовка разборная купить в москве продажа бытовок
1win mozambique
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
1win bet mocambique
купить школьный аттестат с занесением в реестр [url=https://server-diploms.ru/]server-diploms.ru[/url] .
Легальные способы покупки диплома о среднем полном образовании
Сколько стоит диплом высшего и среднего образования и как его получить?
Узнайте, как приобрести диплом о высшем образовании без рисков
newrealgames.ru/ne-teryayte-vremeni-diplom-uzhe-zhdet-vas
аттестат за 9 класс купить [url=https://landik-diploms.ru/]landik-diploms.ru[/url] .
Купить диплом о среднем полном образовании, в чем подвох и как избежать обмана?
Приобретение диплома ВУЗа с сокращенной программой обучения в Москве
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: сервисный ремонт айфонов в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
neon54 login
купить диплом вуза ссср в красноярске [url=https://arusak-diploms.ru/]arusak-diploms.ru[/url] .
Официальное получение диплома техникума с упрощенным обучением в Москве
купить диплом недорого нижний новгород [url=https://man-diploms.ru/]man-diploms.ru[/url] .
бизнес план цветочный магазин основные расходы [url=cvetov-ray.ru]cvetov-ray.ru[/url] .
маркетинговый аудит компании [url=http://marketing99.ru/]http://marketing99.ru/[/url] .
снятие наркотической ломки [url=https://www.snyatie-lomki-narkolog14.ru]снятие наркотической ломки[/url] .
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
besconeshnocte.flybb.ru/viewtopic.php?f=2&t=1233
1 win bet app
Свежие приколы, шутки и картинки http://shutki-anekdoty.ru/.
Смешные видео https://sites.google.com/view/smeshnye-video/%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F-%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0.
Официальная покупка диплома ПТУ с упрощенной программой обучения
[url=][/url]
Временная регистрация в Москве: Быстро и Легально!
Ищете, где оформить временную регистрацию в Москве? Мы гарантируем быстрое и легальное оформление без очередей и лишних документов. Ваше спокойствие – наша забота!
Минимум усилий • Максимум удобства • Полная легальность
Свяжитесь с нами прямо сейчас!
[url=https://regm7921.ru/].[/url]
[url=][/url]
Как официально приобрести аттестат 11 класса с минимальными затратами времени
снятие ломки наркомана [url=https://snyatie-lomki-narkolog15.ru/]снятие ломки наркомана[/url] .
снятие наркотической ломки на дому [url=https://snyatie-lomki-narkolog16.ru]https://snyatie-lomki-narkolog16.ru[/url] .
снятие ломки клинике [url=https://snyatie-lomki-narkolog18.ru]снятие ломки клинике [/url] .
лечение запоя в стационаре [url=http://vyvod-iz-zapoya-v-stacionare-voronezh15.ru]http://vyvod-iz-zapoya-v-stacionare-voronezh15.ru[/url] .
снятие героиновой ломки [url=https://www.snyatie-lomki-narkolog17.ru]снятие героиновой ломки[/url] .
Как официально приобрести аттестат 11 класса с минимальными затратами времени
купил диплом кандидата наук отзывы [url=https://prema-diploms.ru/]купил диплом кандидата наук отзывы[/url] .
купить диплом ветврач [url=https://orik-diploms.ru/]orik-diploms.ru[/url] .
Сервисный центр предлагает ремонт sony cyber-shot dsc-w215 ремонт sony cyber-shot dsc-w215 в петербурге
Свежие и смешные видеоролики https://sites.google.com/view/smeshnye-video/%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F-%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0.
Смешные приколы, шутки и картинки http://shutki-anekdoty.ru.
Полезная информация как официально купить диплом о высшем образовании
Как получить диплом техникума официально и без лишних проблем
Как быстро и легально купить аттестат 11 класса в Москве
Всё, что нужно знать о покупке аттестата о среднем образовании
Прикольные видео https://sites.google.com/view/smeshnye-video/%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F-%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0.
вывод из запоя в стационаре [url=https://vyvod-iz-zapoya-v-stacionare15.ru/]https://vyvod-iz-zapoya-v-stacionare15.ru/[/url] .
лечение алкогольной зависимости стационаре [url=www.vyvod-iz-zapoya-v-stacionare-voronezh17.ru]www.vyvod-iz-zapoya-v-stacionare-voronezh17.ru[/url] .
Веселые приколы http://shutki-anekdoty.ru.
наркология вывод из запоя в стационаре [url=http://www.vyvod-iz-zapoya-v-stacionare14.ru]наркология вывод из запоя в стационаре[/url] .
Быстрая схема покупки диплома старого образца: что важно знать?
где купить дипломы вуза [url=https://landik-diploms.ru/]где купить дипломы вуза[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании
Сервисный центр предлагает ремонт сигвеев wmotion ремонт сигвеев wmotion на дому
Диплом техникума купить официально с упрощенным обучением в Москве
выведение из запоя в воронеже стационарно [url=vyvod-iz-zapoya-v-stacionare-voronezh16.ru]выведение из запоя в воронеже стационарно[/url] .
Полезные советы по покупке диплома о высшем образовании без риска
купить диплом с оценками [url=https://server-diploms.ru/]server-diploms.ru[/url] .
Веселые анекдоты https://sites.google.com/view/smeshnye-video/anekdoty
Сколько стоит получить диплом высшего и среднего образования легально?
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
antoinegriezmannclub.com/read-blog/8302
Сколько стоит диплом высшего и среднего образования и как его получить?
Смешные анекдоты http://shutki-anekdoty.ru/anekdoty
Официальное получение диплома техникума с упрощенным обучением в Москве
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
trumpbookusa.com/blogs/new
купить диплом колледжа в омске [url=https://man-diploms.ru/]man-diploms.ru[/url] .
Реально ли приобрести диплом стоматолога? Основные шаги
pokypke.flybb.ru/viewtopic.php?f=2&t=507
вывод из запоя в коломне [url=kapelnica-ot-zapoya-kolomna14.ru]вывод из запоя в коломне[/url] .
Пошаговая инструкция по официальной покупке диплома о высшем образовании
russianecuador.com/forum/member.php?u=13207
купить диплом инженер электрик [url=https://diplomdarom.ru/]diplomdarom.ru[/url] .
купить диплом без предоплаты [url=https://realdiplom.ru/]купить диплом без предоплаты[/url] .
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Свежие и смешные анекдоты http://shutki-anekdoty.ru/anekdoty
Сервисный центр предлагает адреса ремонта роботов пылесосов accesstyle качественный ремонт роботов пылесосов accesstyle
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Рекомендации по безопасной покупке диплома о высшем образовании
купить диплом московского института [url=https://russa-diploms.ru/]russa-diploms.ru[/url] .
скорая наркологическая помощь на дому в москве [url=https://dexamethazon.ru]скорая наркологическая помощь на дому в москве[/url] .
стоимость капельницы от запоя [url=www.kapelnica-ot-zapoya-kolomna16.ru]стоимость капельницы от запоя[/url] .
скорая наркологическая помощь в москве [url=http://skoraya-narkologicheskaya-pomoshch-moskva.ru]скорая наркологическая помощь в москве[/url] .
капельница от запоя на дому [url=https://kapelnica-ot-zapoya-kolomna15.ru/]капельница от запоя на дому[/url] .
вызов скорой наркологической помощи [url=https://www.skoraya-narkologicheskaya-pomoshch-moskva11.ru]https://www.skoraya-narkologicheskaya-pomoshch-moskva11.ru[/url] .
Сайт приколов http://humor-kartinki.ru собрание лучших мемов, шуток и смешных видео, чтобы ваш день был ярче. Ежедневное обновление контента для вашего настроения. Легко находите и делитесь забавными моментами с друзьями.
продвижение сайтов в москве https://is-market.ru
Можно ли купить аттестат о среднем образовании? Основные рекомендации
купить диплом колледж петербург [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Возможно ли купить диплом стоматолога, и как это происходит
образование купить [url=https://orik-diploms.ru/]образование купить[/url] .
Полезные советы по покупке диплома о высшем образовании без риска
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Сайт приколов https://www.dermandar.com/user/billybons собрание лучших мемов, шуток и смешных видео, чтобы ваш день был ярче. Ежедневное обновление контента для вашего настроения. Легко находите и делитесь забавными моментами с друзьями.
Как получить диплом техникума с упрощенным обучением в Москве официально
Диплом вуза купить официально с упрощенным обучением в Москве
неотложная наркологическая помощь [url=http://www.skoraya-narkologicheskaya-pomoshch-moskva12.ru]неотложная наркологическая помощь[/url] .
Быстрая схема покупки диплома старого образца: что важно знать?
скорая наркологическая помощь круглосуточно [url=www.skoraya-narkologicheskaya-pomoshch-moskva13.ru]www.skoraya-narkologicheskaya-pomoshch-moskva13.ru[/url] .
Ищете выгодные грузоперевозки в Телеграм? Наш сервис поможет вам сэкономить на доставке.
купить диплом в чапаевске [url=https://arusak-diploms.ru/]arusak-diploms.ru[/url] .
купить диплом советских республик [url=https://landik-diploms.ru/]landik-diploms.ru[/url] .
купить диплом 2007 [url=https://server-diploms.ru/]server-diploms.ru[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
leadrp.listbb.ru/viewtopic.php?f=3&t=671
Официальная покупка аттестата о среднем образовании в Москве и других городах
vsetutonline.com/forum/member.php?u=76509
Купить диплом магистра оказалось возможно, быстрое обучение и диплом на руки
Официальное получение диплома техникума с упрощенным обучением в Москве
Сайт смешных историй http://shutki-anekdoty.ru/istorii собрание лучших веселых усторий. Ежедневное обновление контента для вашего настроения. Легко находите и делитесь забавными моментами с друзьями.
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Смешные приколы на сайте https://subscribe.ru/author/31612079 Самые смешные приколы. делитесь с друзьями. Легко находите и делитесь забавными моментами с друзьями.
купить диплом делопроизводитель [url=https://man-diploms.ru/]man-diploms.ru[/url] .
вывод из запоя на дому в люберцые [url=http://www.kapelnica-ot-zapoya-lyubercy11.ru]вывод из запоя на дому в люберцые[/url] .
где купить готовый диплом [url=https://diplomdarom.ru/]где купить готовый диплом[/url] .
вывод из запоя в люберцые [url=kapelnica-ot-zapoya-lyubercy12.ru]вывод из запоя в люберцые[/url] .
вывод из запоя на дому люберцы [url=http://www.kapelnica-ot-zapoya-lyubercy13.ru]вывод из запоя на дому люберцы[/url] .
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Рћ компании DiplomiKus “Дипломикус”
kyc-diplom.com/o-kompanii.html
bc.game
Официальная покупка аттестата о среднем образовании в Москве и других городах
Сайт смешных историй http://shutki-anekdoty.ru/istorii собрание лучших веселых усторий. Ежедневное обновление контента для вашего настроения. Легко находите и делитесь забавными моментами с друзьями.
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
bcgames
купить диплом электрика цена [url=https://realdiplom.ru/]realdiplom.ru[/url] .
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
срочная помощь вывод из запоя москва [url=www.vyvod-iz-zapoya-moskva12.ru/]www.vyvod-iz-zapoya-moskva12.ru/[/url] .
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
neon54 online casino
Короткие цитаты о смысле жизни. Цитаты известных людей.
Смешные приколы и юмор. Делитесь с друзьями. Всегда есть над чем посмеяться.
1win mozambique
Как получить диплом техникума официально и без лишних проблем
Как избежать рисков при покупке диплома колледжа или ПТУ в России
vavada site
Hi, I want to subscribe for this blog to obtain latest updates, thus where can i do it please help out.
кунилингус
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
вызвать капельнцу от запоя [url=https://www.kapelnica-ot-zapoya-podolsk12.ru]https://www.kapelnica-ot-zapoya-podolsk12.ru[/url] .
врач вывод из запоя королев [url=https://vyvod-iz-zapoya-korolev11.ru/]врач вывод из запоя королев[/url] .
вывод из запоя подольск [url=https://kapelnica-ot-zapoya-podolsk13.ru/]вывод из запоя подольск [/url] .
vavada casino bonus code
Где и как купить диплом о высшем образовании без лишних рисков
Реально ли приобрести диплом стоматолога? Основные шаги
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
купить диплом первокласснику в новосибирске [url=https://rudik-diploms365.ru/]rudik-diploms365.ru[/url] .
Смешные https://smeh.ru и юмор. Делитесь с друзьями. Всегда есть над чем посмеяться.
vavada казино
Покупка диплома о среднем полном образовании: как избежать мошенничества?
karkadan.ru/users/77829
клиника прерывания запоя [url=http://vyvod-iz-zapoya-voronezh13.ru]клиника прерывания запоя [/url] .
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
enriquerp.listbb.ru/viewtopic.php?f=4&t=731
Стоимость дипломов высшего и среднего образования и как избежать подделок
kvitka.ukrbb.net/viewtopic.php?f=58&t=27120
football skills
football skills hello i am a football skiller
Тут можно преобрести огнестойкий сейф купить сейф огнестойкий
cristiano ronaldo skills
cristiano ronaldo skills hello i am a football player
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Диплом вуза купить официально с упрощенным обучением в Москве
купить диплом техникума в новосибирске [url=https://3russkiy-diploms.ru/]3russkiy-diploms.ru[/url] .
Тут можно купить домашний сейф в москве сейфы для дома цены в москве
диплом с занесением в реестр [url=https://prem-diplom77.ru/]диплом с занесением в реестр[/url] .
Полезная информация как официально купить диплом о высшем образовании
дипломная работа на заказ [url=https://servera-diplomy199.ru/]servera-diplomy199.ru[/url] .
Тут можно преобрести сейфы огнестойкие сейф огнестойкий в москве
вывод из запоя нарколог на дом цена [url=http://vyvod-iz-zapoya-chelyabinsk12.ru/]вывод из запоя нарколог на дом цена[/url] .
вывод из запоя вызов [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя вызов[/url] .
помощь при запое [url=http://www.vyvod-iz-zapoya-ekaterinburg21.ru]помощь при запое[/url] .
купить диплом университета в ростове на дону [url=https://prema365-diploms.ru/]prema365-diploms.ru[/url] .
вывод из запоя челябинск [url=https://www.vyvod-iz-zapoya-chelyabinsk13.ru]вывод из запоя челябинск[/url] .
Как правильно купить диплом колледжа и пту в России, подводные камни
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Для удобного доступа скачайте 1xslots на андроид бесплатно и начните игру прямо сейчас!
Как купить диплом о высшем образовании с минимальными рисками
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Как оказалось, купить диплом кандидата наук не так уж и сложно
электрокарниз купить [url=www.elektrokarniz-dlya-shtor15.ru]электрокарниз купить[/url] .
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Официальное получение диплома техникума с упрощенным обучением в Москве
Покупка диплома о среднем полном образовании: как избежать мошенничества?
сколько стоит согласование перепланировки квартиры [url=www.stoimost-soglasovaniya-pereplanirovki-kvartiry.ru/]сколько стоит согласование перепланировки квартиры[/url] .
дермантин для мебели [url=https://www.iskusstvennaya-kozha-dlya-mebeli-kupit.ru]дермантин для мебели[/url] .
best instagram viewer [url=www.freeinstviewer.com]best instagram viewer[/url] .
заказать проект перепланировки квартиры в москве цена [url=https://stoimost-soglasovaniya-pereplanirovki-kvartiry.ru]https://stoimost-soglasovaniya-pereplanirovki-kvartiry.ru[/url] .
дермантин купить [url=https://iskusstvennaya-kozha-dlya-mebeli-kupit.ru/]дермантин купить[/url] .
Полезные советы по безопасной покупке диплома о высшем образовании
Быстрое обучение и получение диплома магистра – возможно ли это?
сервис для накрутки подписчиков в инстаграм [url=https://www.artmaxboost11.com]https://www.artmaxboost11.com[/url] .
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Официальная покупка диплома вуза с сокращенной программой в Москве
winda.top/viewtopic.php?f=17&t=810290
Легальные способы покупки диплома о среднем полном образовании
купить копию диплома о высшем [url=https://1russa-diploms.ru/]купить копию диплома о высшем[/url] .
купить диплом 1995 года [url=https://many-diplom77.ru/]купить диплом 1995 года[/url] .
Нужен безопасный способ начать? Используйте Lucky Jet демоверсия и потренируйтесь.
Как официально приобрести аттестат 11 класса с минимальными затратами времени
Рекомендации по безопасной покупке диплома о высшем образовании
repetitor.ekafe.ru/faq.php
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
view insta stories anonymously [url=www.storyinst.com]www.storyinst.com[/url] .
сколько стоит диплом врача [url=https://prema365-diploms.ru/]сколько стоит диплом врача[/url] .
Как оказалось, купить диплом кандидата наук не так уж и сложно
anneoluyorum.net/kupit-attestat-11-klassov-tsena-v-mariupole.html
Как приобрести аттестат о среднем образовании в Москве и других городах
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
Полезная информация как официально купить диплом о высшем образовании
франшизы 2024 [url=https://franshizy17.ru]франшизы 2024[/url] .
сервис накрутки подписчиков instagram [url=www.nakrutkamedia11.com/]сервис накрутки подписчиков instagram[/url] .
продвижение сайтов город москва [url=https://prodvizhenie-sajtov-v-moskve215.ru/]продвижение сайтов город москва[/url] .
продвижение сайта москва [url=www.prodvizhenie-sajtov-v-moskve214.ru/]продвижение сайта москва[/url] .
быстрое продвижение сайтов москва [url=http://www.prodvizhenie-sajtov-v-moskve216.ru]быстрое продвижение сайтов москва[/url] .
франшиза предложения [url=www.franshizy17.ru]www.franshizy17.ru[/url] .
Тут можно преобрести огнестойкие сейфы сейф несгораемый купить
Полезные советы по безопасной покупке диплома о высшем образовании
Диплом пту купить официально с упрощенным обучением в Москве
Быстрая схема покупки диплома старого образца: что важно знать?
как купить аттестат [url=https://prem-diplom77.ru/]как купить аттестат[/url] .
Как официально приобрести аттестат 11 класса с минимальными затратами времени
Сервисный центр предлагает ремонт кондиционера hisense недорого ремонт кондиционера hisense
Сколько стоит диплом высшего и среднего образования и как его получить?
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Приложения для мобильных ставок на спорт доступны для скачивания. Легальные БК предлагают удобные решения — скачать приложение БК
вывод из запоя на дому ростов цены [url=https://www.krasnogorsk.anihub.me/viewtopic.php?id=2566]https://www.krasnogorsk.anihub.me/viewtopic.php?id=2566[/url] .
какую франшизу открыть [url=https://www.franshizy21.ru]какую франшизу открыть[/url] .
какую франшизу купить [url=franshizy19.ru]какую франшизу купить[/url] .
франшища [url=http://franshizy22.ru]франшища[/url] .
топ франчайзинг [url=franshizy18.ru]franshizy18.ru[/url] .
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Тут можно преобрести пожаростойкие сейфы сейф пожаростойкий
Аттестат 11 класса купить официально с упрощенным обучением в Москве
Вопросы и ответы: можно ли быстро купить диплом старого образца?
bc game app
Как приобрести диплом о среднем образовании в Москве и других городах
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
t.me/hamsTer_kombat_bot/start?startapp=kentId670607571
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Официальная покупка диплома вуза с сокращенной программой в Москве
вывод из запоя на дому ростов-на-дону [url=http://spilkuvannya.rolevaya.com/viewtopic.php?id=65]http://spilkuvannya.rolevaya.com/viewtopic.php?id=65[/url] .
вывод из запоя цены ростов на дону [url=http://vkontakte.forum.cool/viewtopic.php?id=19611]http://vkontakte.forum.cool/viewtopic.php?id=19611[/url] .
вывод из запоя на дому ростов-на-дону [url=http://pelsh.forum24.ru/?1-8-0-00000124-000-0-0-1730725547/]http://pelsh.forum24.ru/?1-8-0-00000124-000-0-0-1730725547/[/url] .
вывод из запоя цены ростов на дону [url=https://www.rodoslav.forum24.ru/?1-4-0-00000569-000-0-0-1730725681]вывод из запоя цены ростов на дону[/url] .
вывод. из. запоя. ростов. [url=http://www.aktivnoe.forum24.ru/?1-7-0-00012822-000-0-0-1730725137]http://www.aktivnoe.forum24.ru/?1-7-0-00012822-000-0-0-1730725137[/url] .
Как получить диплом о среднем образовании в Москве и других городах
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Пошаговая инструкция по официальной покупке диплома о высшем образовании
mirnuy.forumieren.de/t8539-topic#13824
Аттестат школы купить официально с упрощенным обучением в Москве
купить диплом бакалавра в москве [url=https://prema365-diploms.ru/]купить диплом бакалавра в москве[/url] .
1win juegos
Легальная покупка диплома ПТУ с сокращенной программой обучения
Испытайте удачу с Лаки джет игра и получите уникальные ощущения.
Здесь можно преобрести сейф цена сейф
Как быстро получить диплом магистра? Легальные способы
1win casino
Тут можно преобрести сейф огнеупорный купить огнеупорные сейфы
вывод из запоя на дому ростов цены [url=https://www.vip.mybb.rocks/viewtopic.php?id=7671]https://www.vip.mybb.rocks/viewtopic.php?id=7671[/url] .
вывод из запоя на дому ростов на дону [url=https://svarog.forum24.ru/?1-0-0-00000223-000-0-0-1730725970/]вывод из запоя на дому ростов на дону[/url] .
Home decor Promo Codes [url=www.skidki-i-kupony.ru/]www.skidki-i-kupony.ru/[/url] .
вывод из запоя цены ростов на дону [url=www.motik13.0pk.me/viewtopic.php?id=1994/]вывод из запоя цены ростов на дону[/url] .
Тут можно преобрести оружейный сейф цена шкаф для оружия цена
вывод из запоя в ростове [url=http://rubiz.forum.cool/viewtopic.php?id=3745]http://rubiz.forum.cool/viewtopic.php?id=3745[/url] .
нарколог на дом вывод из запоя ростов [url=http://snatkina.borda.ru/?1-11-0-00000199-000-0-0-1730726180]http://snatkina.borda.ru/?1-11-0-00000199-000-0-0-1730726180[/url] .
bc game apk download latest version
Сколько стоит диплом высшего и среднего образования и как его получить?
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
промокод на продамус скидка подключение [url=http://prodamus-promokod1.ru]промокод на продамус скидка подключение[/url] .
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
vavada
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
1win juegos
вывод из запоя в ростове [url=http://tatuheart.ukrbb.net/viewtopic.php?f=8&t=15065]http://tatuheart.ukrbb.net/viewtopic.php?f=8&t=15065[/url] .
вывод из запоя на дому [url=www.ideya.forums.party/viewtopic.php?id=654]вывод из запоя на дому[/url] .
нарколог вывод из запоя ростов [url=ekonomimvmeste.ukrbb.net/viewtopic.php?f=14&t=65339]нарколог вывод из запоя ростов[/url] .
нарколог на дом вывод из запоя ростов [url=http://pokupki.bestforums.org/viewtopic.php?f=7&t=24037]http://pokupki.bestforums.org/viewtopic.php?f=7&t=24037[/url] .
вывод из запоя дешево ростов на дону [url=http://www.honey.ukrbb.net/viewtopic.php?f=45&t=16678]http://www.honey.ukrbb.net/viewtopic.php?f=45&t=16678[/url] .
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Сколько стоит диплом высшего и среднего образования и как это происходит?
Стоимость дипломов высшего и среднего образования и как избежать подделок
Сервисный центр предлагает ремонт hp elitebook 8540p в петербурге ремонт hp elitebook 8540p в петербурге
Тут можно преобрести огнеупорный сейф огнеупорный сейф
bc fun
vavada casino
Как официально купить диплом вуза с упрощенным обучением в Москве
купить дубликат диплома о среднем профессиональном образовании [url=https://1oriks-diplom199.ru/]купить дубликат диплома о среднем профессиональном образовании[/url] .
Как получить диплом техникума с упрощенным обучением в Москве официально
orthograf.getbb.ru/viewtopic.php?f=2&t=768
Полезные советы по безопасной покупке диплома о высшем образовании
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Диплом вуза купить официально с упрощенным обучением в Москве
Диплом техникума купить официально с упрощенным обучением в Москве
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Диплом вуза купить официально с упрощенным обучением в Москве
bioniclerpg.getbb.ru/viewtopic.php?f=6&t=2757
Полезная информация как купить диплом о высшем образовании без рисков
вывод из запоя ростовская область [url=https://superjackson.ukrbb.net/viewtopic.php?f=28&t=9728]вывод из запоя ростовская область[/url] .
лучшие онлайн казино [url=www.online-kazino.by]www.online-kazino.by[/url] .
вывод из запоя в стационаре ростов-на-дону [url=www.ya.7bb.ru/viewtopic.php?id=14592#p40831]www.ya.7bb.ru/viewtopic.php?id=14592#p40831[/url] .
Тут можно преобрести огнеупорный сейф купить сейфы огнестойкие
1win juegos
вывод из запоя ростов [url=http://www.superjackson.ukrbb.net/viewtopic.php?f=28&t=9728]вывод из запоя ростов[/url] .
Сколько стоит диплом высшего и среднего образования и как его получить?
вывод из запоя цена ростов [url=http://svstrazh.forum24.ru/?1-3-0-00000230-000-0-0-1730648739/]вывод из запоя цена ростов[/url] .
вывод из запоя круглосуточно ростов-на-дону [url=http://www.vkontakte.forum.cool/viewtopic.php?id=19596]http://www.vkontakte.forum.cool/viewtopic.php?id=19596[/url] .
Как получить диплом техникума с упрощенным обучением в Москве официально
Как получить диплом техникума официально и без лишних проблем
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
reflections.listbb.ru/viewtopic.php?f=45&t=1091
neon54 casino
Быстрая схема покупки диплома старого образца: что важно знать?
Узнайте, как безопасно купить диплом о высшем образовании
Как официально приобрести аттестат 11 класса с минимальными затратами времени
Access exclusive rewards with 888Starz bonus codes and play big.
вывод из запоя цена ростов [url=http://familyportal.forumrom.com/viewtopic.php?id=28559/]http://familyportal.forumrom.com/viewtopic.php?id=28559/[/url] .
вывод из запоя ростов [url=https://vip.mybb.rocks/viewtopic.php?id=7670]https://vip.mybb.rocks/viewtopic.php?id=7670[/url] .
принудительный вывод из запоя ростов [url=familyportal.forumrom.com/viewtopic.php?id=28544#p70286]familyportal.forumrom.com/viewtopic.php?id=28544#p70286[/url] .
вывод из запоя цены ростов [url=www.rubiz.forum.cool/viewtopic.php?id=3742/]www.rubiz.forum.cool/viewtopic.php?id=3742/[/url] .
вывод из запоя круглосуточно [url=https://my.forum2.net/viewtopic.php?id=171/]my.forum2.net/viewtopic.php?id=171[/url] .
нарколог на дом вывод из запоя на дому [url=http://alhambra.bestforums.org/viewtopic.php?f=2&t=46349]http://alhambra.bestforums.org/viewtopic.php?f=2&t=46349[/url] .
Полезные советы по покупке диплома о высшем образовании без риска
вывод из запоя дешево ростов-на-дону [url=http://mymoscow.forum24.ru/?1-6-0-00022899-000-0-0-1730709378/]http://mymoscow.forum24.ru/?1-6-0-00022899-000-0-0-1730709378/[/url] .
Тут можно преобрести сейфы огнестойкие сейфы пожаростойкие
neon56
Стоимость дипломов высшего и среднего образования и процесс их получения
Легальная покупка диплома ПТУ с сокращенной программой обучения
accostkpyo.online/diplom-devstvennika-kupit.html
Всё о покупке аттестата о среднем образовании: полезные советы
Полезная информация как официально купить диплом о высшем образовании
Официальная покупка диплома вуза с сокращенной программой в Москве
mastercode.ru/forum/?PAGE_NAME=profile_view&UID=4856
Официальная покупка аттестата о среднем образовании в Москве и других городах
Всё, что нужно знать о покупке аттестата о среднем образовании
Полезная информация как купить диплом о высшем образовании без рисков
1win casino online
Купить диплом о среднем полном образовании, в чем подвох и как избежать обмана?
Как приобрести диплом о среднем образовании в Москве и других городах
Как правильно купить диплом колледжа и пту в России, подводные камни
алкоголизм лечение вывод из запоя ростов [url=www.kryto.ukrbb.net/viewtopic.php?f=3&t=1161/]алкоголизм лечение вывод из запоя ростов[/url] .
Ruleta Jugabet [url=https://jugabet777.com/]Ruleta Jugabet[/url] .
вывод из запоя на дому ростов [url=https://www.golosa.ukrbb.net/viewtopic.php?f=3&t=7466]https://www.golosa.ukrbb.net/viewtopic.php?f=3&t=7466[/url] .
вывод из запоя ростов [url=https://superstar.ukrbb.net/viewtopic.php?f=3&t=680/]https://superstar.ukrbb.net/viewtopic.php?f=3&t=680/[/url] .
вывод из запоя на дому [url=stranaua.ukrbb.net/viewtopic.php?f=2&t=59741]stranaua.ukrbb.net/viewtopic.php?f=2&t=59741[/url] .
нарколог вывод из запоя ростов [url=http://kryto.ukrbb.net/viewtopic.php?f=3&t=1161/]нарколог вывод из запоя ростов[/url] .
Тут можно преобрести сейф огнестойкий сейф несгораемый
Официальная покупка диплома ПТУ с упрощенной программой обучения
Можно ли быстро купить диплом старого образца и в чем подвох?
Быстрая схема покупки диплома старого образца: что важно знать?
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Можно ли быстро купить диплом старого образца и в чем подвох?
Полезные советы по безопасной покупке диплома о высшем образовании
купить диплом вуза в нижнем новгороде [url=https://1oriks-diplom199.ru/]купить диплом вуза в нижнем новгороде[/url] .
Как приобрести аттестат о среднем образовании в Москве и других городах
вывод из запоя дешево ростов [url=http://ukroenergo.ukrbb.net/viewtopic.php?f=13&t=21376/]http://ukroenergo.ukrbb.net/viewtopic.php?f=13&t=21376/[/url] .
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали официальный сервисный центр xiaomi, можете посмотреть на сайте: сервисный центр xiaomi в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
вывод. из. запоя. ростов. на. дону. [url=http://rio16.ukrbb.net/viewtopic.php?f=3&t=1112/]http://rio16.ukrbb.net/viewtopic.php?f=3&t=1112/[/url] .
вывод из запоя цены ростов-на-дону [url=www.www.rolandus.org/forum/viewtopic.php?p=106422/]www.www.rolandus.org/forum/viewtopic.php?p=106422/[/url] .
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Рекомендации по безопасной покупке диплома о высшем образовании
hobby-svarka.ru/viewtopic.php?f=11&t=7032
Как получить диплом о среднем образовании в Москве и других городах
Возможно ли купить диплом стоматолога, и как это происходит
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
вывод из запоя дешево ростов на дону [url=http://www.avtomobili.creartuforo.com/viewtopic.php?id=730]http://www.avtomobili.creartuforo.com/viewtopic.php?id=730[/url] .
Как оказалось, купить диплом кандидата наук не так уж и сложно
врач нарколог на дом платный [url=http://www.krut.forumno.com/viewtopic.php?id=6025]врач нарколог на дом платный[/url] .
вывод из запоя ростов и область [url=zarabotokdoma.creartuforo.com/viewtopic.php?id=11471]zarabotokdoma.creartuforo.com/viewtopic.php?id=11471[/url] .
вызов нарколога на дом краснодар [url=www.planeta.mybb.social/viewtopic.php?id=2227/]www.planeta.mybb.social/viewtopic.php?id=2227/[/url] .
нарколог на дом краснодар [url=www.recordrpservak.ukrbb.net/viewtopic.php?f=31&t=1158]www.recordrpservak.ukrbb.net/viewtopic.php?f=31&t=1158[/url] .
вызов нарколога на дом краснодар [url=www.krasnogorsk.anihub.me/viewtopic.php?id=2568]www.krasnogorsk.anihub.me/viewtopic.php?id=2568[/url] .
Тут можно преобрести интернет магазин сейфов для оружия интернет магазин сейфов для оружия
Купить диплом экономиста – оптимальное решение
Полезные советы по безопасной покупке диплома о высшем образовании
нарколог на дом срочно [url=www.motik13.0pk.me/viewtopic.php?id=1995]www.motik13.0pk.me/viewtopic.php?id=1995[/url] .
Официальная покупка школьного аттестата с упрощенным обучением в Москве
BBgate MarketPlace 2024 Breaking Bad Gate Forum
BBgate MarketPlace
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Быстрая схема покупки диплома старого образца: что важно знать?
Быстрая схема покупки диплома старого образца: что важно знать?
Быстрая схема покупки диплома старого образца: что важно знать?
Как получить диплом стоматолога быстро и официально
Как купить диплом о высшем образовании с минимальными рисками
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Купить диплом в России, предлагает наша компания
I’m not sure exactly why but this weblog is loading extremely slow for me. Is anyone else having this issue or is it a problem on my end? I’ll check back later on and see if the problem still exists.
best online casino Australia
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
карниз для эркера настенный купить [url=www.elektrokarniz495.ru]www.elektrokarniz495.ru[/url] .
вызов нарколога на дом краснодар [url=https://masa.forum24.ru/?1-16-0-00002626-000-0-0-1730730156/]https://masa.forum24.ru/?1-16-0-00002626-000-0-0-1730730156/[/url] .
вызов нарколога на дом краснодар [url=http://ya.7bb.ru/viewtopic.php?id=14601]http://ya.7bb.ru/viewtopic.php?id=14601[/url] .
врач нарколог на дом платный [url=http://vkontakte.forum.cool/viewtopic.php?id=19612#p53237]врач нарколог на дом платный[/url] .
выезд нарколога на дом [url=spilkuvannya.rolevaya.com/viewtopic.php?id=66]spilkuvannya.rolevaya.com/viewtopic.php?id=66[/url] .
1win casino mocambique
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Легальные способы покупки диплома о среднем полном образовании
BBgate MarketPlace 2024 Breaking Bad Gate Forum
BBgate MarketPlace
1win casino
Легальная покупка диплома о среднем образовании в Москве и регионах
Как приобрести аттестат о среднем образовании в Москве и других городах
Официальная покупка аттестата о среднем образовании в Москве и других городах
vavada casino
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Легальная покупка школьного аттестата с упрощенной программой обучения
Аттестат 11 класса купить официально с упрощенным обучением в Москве
вызов нарколога на дом [url=https://www.rolandus.org/forum/viewtopic.php?p=106435&sid=7021c085aed96d9b1661d87aaaac1325/]https://www.rolandus.org/forum/viewtopic.php?p=106435&sid=7021c085aed96d9b1661d87aaaac1325/[/url] .
vavada free spins
вызов нарколога на дом круглосуточно [url=www.rubiz.forum.cool/viewtopic.php?id=3746]www.rubiz.forum.cool/viewtopic.php?id=3746[/url] .
программа 1с купить с установкой цена [url=https://www.kupit-1s11.ru]программа 1с купить с установкой цена[/url] .
нарколог на дом срочно [url=https://belbeer.borda.ru/?1-6-0-00000756-000-0-0-1730730133/]belbeer.borda.ru/?1-6-0-00000756-000-0-0-1730730133[/url] .
вызвать нарколога на дом [url=http://kryto.ukrbb.net/viewtopic.php?f=3&t=1165]http://kryto.ukrbb.net/viewtopic.php?f=3&t=1165[/url] .
вызвать нарколога на дом [url=https://www.superogorod.ucoz.org/forum/2-2085-1]https://www.superogorod.ucoz.org/forum/2-2085-1[/url] .
Быстрое обучение и получение диплома магистра – возможно ли это?
kbrg.ru/club/user/282/blog/?b24statAction=addLogEntry
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
neon54 login
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Как приобрести аттестат о среднем образовании в Москве и других городах
Как официально купить диплом вуза с упрощенным обучением в Москве
Аттестат 11 класса купить официально с упрощенным обучением в Москве
Купить диплом Барнаул
vavada bg
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
Как приобрести аттестат о среднем образовании в Москве и других городах
Как получить диплом стоматолога быстро и официально
вывод из запоя дешево краснодар [url=www.family2.quadrobb.me/viewtopic.php?id=1838/]www.family2.quadrobb.me/viewtopic.php?id=1838/[/url] .
вывод из запоя краснодар стационар [url=wisdomtarot.tforums.org/viewtopic.php?f=16&t=11706]wisdomtarot.tforums.org/viewtopic.php?f=16&t=11706[/url] .
вывод из запоя цены краснодар [url=https://www.belbeer.borda.ru/?1-6-0-00000757-000-0-0-1730745253]https://www.belbeer.borda.ru/?1-6-0-00000757-000-0-0-1730745253[/url] .
neon54 casino
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
Реально ли приобрести диплом стоматолога? Основные этапы
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр samsung в москве, можете посмотреть на сайте: официальный сервисный центр samsung
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр sony в москве, можете посмотреть на сайте: сервисный центр sony в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Легальная покупка школьного аттестата с упрощенной программой обучения
Как приобрести диплом техникума с минимальными рисками
Узнайте, как приобрести диплом о высшем образовании без рисков
вывод из запоя в стационаре воронежа [url=www.to.iboard.ws/viewtopic.php?id=8064]вывод из запоя в стационаре воронежа[/url] .
вывод из запоя лечение краснодар [url=https://forumsilverstars.forum24.ru/?1-2-0-00000149-000-0-0-1730745615/]https://forumsilverstars.forum24.ru/?1-2-0-00000149-000-0-0-1730745615/[/url] .
фонт бет [url=https://fonbet-casino-24.by/]фонт бет[/url] .
вывод из запоя круглосуточно краснодар на дому [url=http://belbeer.borda.ru/?1-6-0-00000758-000-0-0-1730745372]http://belbeer.borda.ru/?1-6-0-00000758-000-0-0-1730745372[/url] .
fonbet by [url=http://www.fonbet-kazino-24.by]fonbet by[/url] .
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Как быстро получить диплом магистра? Легальные способы
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали официальный сервисный центр samsung, можете посмотреть на сайте: официальный сервисный центр samsung
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Легальная покупка диплома о среднем образовании в Москве и регионах
Как не попасть впросак при покупке диплома колледжа или ПТУ в России
Стоимость дипломов высшего и среднего образования и как избежать подделок
Полезная информация как официально купить диплом о высшем образовании
Как избежать рисков при покупке диплома колледжа или ПТУ в России
лечение наркозависимости в стационаре [url=www.domsadremont.ukrbb.net/viewtopic.php?f=3&t=906/]www.domsadremont.ukrbb.net/viewtopic.php?f=3&t=906/[/url] .
Быстрое обучение и получение диплома магистра – возможно ли это?
вывод из запоя в стационаре анонимно [url=https://domsadremont.ukrbb.net/viewtopic.php?f=3&t=906/]https://domsadremont.ukrbb.net/viewtopic.php?f=3&t=906/[/url] .
Полезные советы по безопасной покупке диплома о высшем образовании
лечение наркозависимости в стационаре [url=www.ideya.forums.party/viewtopic.php?id=660/]www.ideya.forums.party/viewtopic.php?id=660/[/url] .
bc fun game
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Покупка диплома о среднем полном образовании: как избежать мошенничества?
derivsocial.org/read-blog/4366
neon54 promo code
Как быстро получить диплом магистра? Легальные способы
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
вывод из запоя воронеж [url=www.ukroenergo.ukrbb.net/viewtopic.php?f=13&t=21384/]вывод из запоя воронеж [/url] .
вывод из запоя воронеж [url=www.ideya.forums.party/viewtopic.php?id=661/]www.ideya.forums.party/viewtopic.php?id=661/[/url] .
вывод из запоя воронеж [url=http://tatuheart.ukrbb.net/viewtopic.php?f=8&t=15073]вывод из запоя воронеж [/url] .
лечение наркозависимости в стационаре [url=https://uaforum.ukrbb.net/viewtopic.php?f=13&t=3240/]https://uaforum.ukrbb.net/viewtopic.php?f=13&t=3240/[/url] .
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
вывод из запоя в стационаре [url=http://www.mozaisk.anihub.me/viewtopic.php?id=4371]http://www.mozaisk.anihub.me/viewtopic.php?id=4371[/url] .
vavada
Диплом пту купить официально с упрощенным обучением в Москве
Вопросы и ответы: можно ли быстро купить диплом старого образца?
vavada casino
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр philips, можете посмотреть на сайте: официальный сервисный центр philips
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
Узнайте, как приобрести диплом о высшем образовании без рисков
Можно ли быстро купить диплом старого образца и в чем подвох?
Приобретение диплома ВУЗа с сокращенной программой обучения в Москве
вывод из запоя в стационаре воронежа [url=https://www.severussnape.borda.ru/?1-4-0-00000318-000-0-0-1730749124]вывод из запоя в стационаре воронежа[/url] .
вывод из запоя в стационаре воронежа [url=https://vkontakte.forum.cool/viewtopic.php?id=19623#p53261/]https://vkontakte.forum.cool/viewtopic.php?id=19623#p53261/[/url] .
Как избежать рисков при покупке диплома колледжа или ПТУ в России
вывод из запоя воронеж [url=https://severussnape.borda.ru/?1-4-0-00000318-000-0-0-1730749124/]вывод из запоя воронеж [/url] .
neon54 casino bonus
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
вывод из запоя в стационаре анонимно [url=https://nsk.ukrbb.net/viewtopic.php?f=45&t=29677/]https://nsk.ukrbb.net/viewtopic.php?f=45&t=29677/[/url] .
Можно ли быстро купить диплом старого образца и в чем подвох?
Официальное получение диплома техникума с упрощенным обучением в Москве
bcgame crash
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Сколько стоит диплом высшего и среднего образования и как его получить?
Легальная покупка диплома о среднем образовании в Москве и регионах
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
вывод из запоя в екатеринбурге [url=http://gonochki.forum24.ru/?1-10-0-00001138-000-0-0-1730749908]http://gonochki.forum24.ru/?1-10-0-00001138-000-0-0-1730749908[/url] .
лечение запоев на дому [url=http://sergiev.0pk.me/viewtopic.php?id=3463/]http://sergiev.0pk.me/viewtopic.php?id=3463/[/url] .
вывод из запоя дома [url=www.rubiz.forum.cool/viewtopic.php?id=3749/]www.rubiz.forum.cool/viewtopic.php?id=3749/[/url] .
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
vavada promo
вывод из запоя капельница [url=https://sportandpolitics.ukrbb.net/viewtopic.php?f=24&t=17827/]https://sportandpolitics.ukrbb.net/viewtopic.php?f=24&t=17827/[/url] .
выведение из запоя врачом наркологом [url=https://kryto.ukrbb.net/viewtopic.php?f=3&t=1168]https://kryto.ukrbb.net/viewtopic.php?f=3&t=1168[/url] .
Купить диплом о среднем образовании в Москве и любом другом городе
Купить диплом в России, предлагает наша компания
вывод из запоя на дому в екатеринбурге [url=zarabotokdoma.creartuforo.com/viewtopic.php?id=11484]zarabotokdoma.creartuforo.com/viewtopic.php?id=11484[/url] .
нарколог на дом екатеринбург цены [url=http://www.ximki.ukrbb.net/viewtopic.php?f=12&t=3702]http://www.ximki.ukrbb.net/viewtopic.php?f=12&t=3702[/url] .
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
Сколько стоит диплом высшего и среднего образования и как это происходит?
настроить 1с бухгалтерия цена [url=1s-buhgalteriya-kupit.ru]настроить 1с бухгалтерия цена[/url] .
выведение из запоя на дому в екатеринбурге [url=http://honey.ukrbb.net/viewtopic.php?f=45&t=16709]http://honey.ukrbb.net/viewtopic.php?f=45&t=16709[/url] .
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
выведение из запоя [url=http://domsadremont.ukrbb.net/viewtopic.php?f=3&t=907]http://domsadremont.ukrbb.net/viewtopic.php?f=3&t=907[/url] .
bc gaming
Полезная информация как купить диплом о высшем образовании без рисков
domkodeks.ru/question/ofitsialnyj-diplom-bez-lishnih-usilij-prosto-i-bystro
Сколько стоит диплом высшего и среднего образования и как его получить?
услуги по оценке условий труда аттестация соут
Как получить диплом техникума с упрощенным обучением в Москве официально
Как получить диплом техникума официально и без лишних проблем
Реально ли приобрести диплом стоматолога? Основные шаги
Покупка диплома о среднем полном образовании: как избежать мошенничества?
“Damn it, son! Damn it! Damn it, you hit the mirror above the sink!” His father shouts as the bullets of cum shoot forth from his son’s cock and hits the adjacent mirror directly in front of the porcelain bathroom thrown.
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Jugabet registro [url=www.jugabet777.com/]Jugabet registro[/url] .
вывод из запоя на дому в екатеринбурге [url=https://zarabotokdoma.creartuforo.com/viewtopic.php?id=11486]https://zarabotokdoma.creartuforo.com/viewtopic.php?id=11486[/url] .
нарколог на дом екатеринбург цены [url=www.rio16.ukrbb.net/viewtopic.php?f=3&t=1121]www.rio16.ukrbb.net/viewtopic.php?f=3&t=1121[/url] .
вывести из запоя цена [url=http://advance2.ukrbb.net/viewtopic.php?f=2&t=781/]http://advance2.ukrbb.net/viewtopic.php?f=2&t=781/[/url] .
выведение из запоя на дому в екатеринбурге [url=http://pokupki.bestforums.org/viewtopic.php?f=7&t=24066/]http://pokupki.bestforums.org/viewtopic.php?f=7&t=24066/[/url] .
His father rakes the clear juice of his son’s leaking manhood over the boy’s tensed cockhead.
Полезные советы по безопасной покупке диплома о высшем образовании
Полезные советы по безопасной покупке диплома о высшем образовании
Диплом вуза купить официально с упрощенным обучением в Москве
Аттестат 11 класса купить официально с упрощенным обучением в Москве
Узнайте стоимость диплома высшего и среднего образования и процесс получения
Как оказалось, купить диплом кандидата наук не так уж и сложно
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Купить диплом экономиста – оптимальное решение
вывод из запоя [url=http://ideya.forums.party/viewtopic.php?id=663/]вывод из запоя[/url] .
лечение запоев на дому [url=https://krut.forumno.com/viewtopic.php?id=6053/]https://krut.forumno.com/viewtopic.php?id=6053/[/url] .
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
Сколько стоит диплом высшего и среднего образования и как его получить?
Как получить диплом о среднем образовании в Москве и других городах
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
Полезные советы по покупке диплома о высшем образовании без риска
Как оказалось, купить диплом кандидата наук не так уж и сложно
нарколог на дом круглосуточно [url=automobilist.forum24.ru/?1-19-0-00000141-000-0-0-1730786242]automobilist.forum24.ru/?1-19-0-00000141-000-0-0-1730786242[/url] .
нарколог на дом краснодар [url=https://dubna.myqip.ru/?1-5-0-00000285-000-0-0-1730786889/]dubna.myqip.ru/?1-5-0-00000285-000-0-0-1730786889[/url] .
Официальное получение диплома техникума с упрощенным обучением в Москве
injectorcar.ru/forum/member.php?u=34916
Как получить диплом техникума с упрощенным обучением в Москве официально
Полезные советы по покупке диплома о высшем образовании без риска
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр asus в москве, можете посмотреть на сайте: сервисный центр asus цены
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
Рекомендации по безопасной покупке диплома о высшем образовании
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
Конструкторы оружия России https://guns.org.ru история создания легендарного оружия, биографии инженеров, технические характеристики разработок.
Сколько стоит диплом высшего и среднего образования и как это происходит?
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
вывод из запоя стационар [url=https://www.dexanet.ukrbb.net/viewtopic.php?f=14&t=20399]вывод из запоя стационар [/url] .
вывод из запоя цена [url=www.4dkp.forum24.ru/?1-18-0-00002750-000-0-0-1730806797/]вывод из запоя цена[/url] .
Как быстро получить диплом магистра? Легальные способы
Сколько стоит диплом высшего и среднего образования и как его получить?
выведение из запоя на дому в сочи [url=www.nsk.ukrbb.net/viewtopic.php?f=41&t=29707/]выведение из запоя на дому в сочи[/url] .
онлайн казино беларусь [url=https://t.me/s/casinobelorus]онлайн казино беларусь[/url] .
казино молдов [url=online-kazino.md]казино молдов[/url] .
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Купить диплом ВУЗа России
Легальные способы покупки диплома о среднем полном образовании
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Сколько стоит получить диплом высшего и среднего образования легально?
Официальная покупка диплома вуза с сокращенной программой в Москве
vsetutonline.com/forum/member.php?u=76509
Сколько стоит диплом высшего и среднего образования и как его получить?
Быстрое обучение и получение диплома магистра – возможно ли это?
Полезные советы по безопасной покупке диплома о высшем образовании
Как быстро и легально купить аттестат 11 класса в Москве
Купить диплом о среднем полном образовании, в чем подвох и как избежать обмана?
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Как приобрести аттестат о среднем образовании в Москве и других городах
Диплом вуза купить официально с упрощенным обучением в Москве
выведение из запоя в нижнем новгороде [url=http://gonochki.forum24.ru/?1-10-0-00001141-000-0-0-1730810673/]выведение из запоя в нижнем новгороде[/url] .
вывод из запоя в стационаре нижний новгород [url=http://vip.rolevaya.info/viewtopic.php?id=6923]вывод из запоя в стационаре нижний новгород[/url] .
Как избежать рисков при покупке диплома колледжа или ВУЗа в России
Как быстро и легально купить аттестат 11 класса в Москве
вывод из запоя круглосуточно [url=http://www.stranaua.ukrbb.net/viewtopic.php?f=2&t=59798]вывод из запоя круглосуточно[/url] .
вывод из запоя стационарно [url=https://sportandpolitics.ukrbb.net/viewtopic.php?f=24&t=17839/]вывод из запоя стационарно[/url] .
кухни москва купить [url=mebeldinastiya.ru]кухни москва купить[/url] .
вывод из запоя стационар [url=www.golosa.ukrbb.net/viewtopic.php?f=3&t=7479/]вывод из запоя стационар[/url] .
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Полезные советы по безопасной покупке диплома о высшем образовании
Как официально купить диплом вуза с упрощенным обучением в Москве
Официальная покупка диплома вуза с сокращенной программой в Москве
Купить диплом Барнаул
сколько стоит капельница на дому от запоя [url=http://gaslo.ukrbb.net/viewtopic.php?f=13&t=3419/]сколько стоит капельница на дому от запоя[/url] .
выведение из запоя на дому круглосуточно [url=www.helene.borda.ru/?1-13-0-00000115-000-0-0-1730813378]выведение из запоя на дому круглосуточно[/url] .
капельница при алкогольной интоксикации на дому цена [url=http://www.klin.0pk.me/viewtopic.php?id=4414]капельница при алкогольной интоксикации на дому цена[/url] .
нижний новгород вывод из запоя на дому [url=http://airlady.forum24.ru/?1-8-0-00000026-000-0-0-1730813282/]нижний новгород вывод из запоя на дому[/url] .
капельницы на дому от запоя [url=http://uaportal.ukrbb.net/viewtopic.php?f=2&t=3726/]капельницы на дому от запоя[/url] .
Официальная покупка диплома вуза с сокращенной программой в Москве
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Полезные советы по безопасной покупке диплома о высшем образовании
Официальная покупка диплома вуза с упрощенной программой обучения
капельница при алкогольной интоксикации на дому цена [url=http://www.pelsh.forum24.ru/?1-8-0-00000131-000-0-0-1730814617]капельница при алкогольной интоксикации на дому цена[/url] .
вывод из запоя на дому нижний [url=https://pelsh.forum24.ru/?1-8-0-00000131-000-0-0-1730814617/]вывод из запоя на дому нижний[/url] .
нарколог на дом вывод из запоя цена [url=chesskomi.borda.ru/?1-6-0-00000051-000-0-0-1730813773]нарколог на дом вывод из запоя цена[/url] .
нарколог на дом вывод из запоя цена [url=https://ya.7bb.ru/viewtopic.php?id=14624/]нарколог на дом вывод из запоя цена[/url] .
Сколько стоит диплом высшего и среднего образования и как это происходит?
вывод. из. запоя. на. дому. [url=https://www.ideya.forums.party/viewtopic.php?id=668]вывод. из. запоя. на. дому.[/url] .
капельница на дом круглосуточно [url=http://www.belbeer.borda.ru/?1-6-0-00000775-000-0-0-1730814738]капельница на дом круглосуточно[/url] .
вывод из запоя нижний [url=https://www.belbeer.borda.ru/?1-6-0-00000776-000-0-0-1730815220]вывод из запоя нижний[/url] .
для доступа к актуальной информации о vavada переходите по ссылке https://t.me/qvavada. в нашем телеграм-канале вы найдёте всё необходимое: бонусы, а также новости о свежих обновлениях. не упустите шанс получить максимум возможностей от игры!
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
вывод запой нижний [url=http://www.sportandpolitics.ukrbb.net/viewtopic.php?f=24&t=17847]вывод запой нижний[/url] .
капельница от похмелья купить [url=http://ekonomimvmeste.ukrbb.net/viewtopic.php?f=14&t=65404]капельница от похмелья купить[/url] .
Купить диплом судоводителя
Как получить диплом техникума с упрощенным обучением в Москве официально
[url=][/url]
Временная регистрация в Санкт-Петербурге: Быстро и Легально!
Ищете, где оформить временную регистрацию в СПБ?
Мы гарантируем быстрое и легальное оформление без очередей и лишних документов.
Ваше спокойствие – наша забота!
Минимум усилий • Максимум удобства • Полная легальность
Свяжитесь с нами прямо сейчас!
Временная регистрация в СПБ
[url=][/url]
вывод из запоя в стационаре Самары [url=http://tatuheart.ukrbb.net/viewtopic.php?f=8&t=15087]вывод из запоя в стационаре Самары[/url] .
поздравления с днем рождения женщине на вы [url=http://pro-happy-birthday.ru/]поздравления с днем рождения женщине на вы[/url] .
Купить диплом о среднем образовании в Москве и любом другом городе
Как получить диплом о среднем образовании в Москве и других городах
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали срочный ремонт телевизоров samsung, можете посмотреть на сайте: ремонт телевизоров samsung сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Удивительно, но купить диплом кандидата наук оказалось не так сложно
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Легальная покупка диплома ПТУ с сокращенной программой обучения
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Узнайте, как безопасно купить диплом о высшем образовании
выводу из запоя в стационаре [url=http://uaportal.ukrbb.net/viewtopic.php?f=2&t=3728]выводу из запоя в стационаре[/url] .
Полезные советы по покупке диплома о высшем образовании без риска
Купить диплом о среднем полном образовании, в чем подвох и как избежать обмана?
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Купить диплом судоводителя
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Быстрая схема покупки диплома старого образца: что важно знать?
Стоимость дипломов высшего и среднего образования и процесс их получения
Покупка диплома о среднем полном образовании: как избежать мошенничества?
капельницы на дому от запоя [url=http://www.kyevlyn.ukrbb.net/viewtopic.php?f=2&t=13688]капельницы на дому от запоя[/url] .
капельницу коломна от запоя [url=https://www.domsadremont.ukrbb.net/viewtopic.php?f=3&t=913]капельницу коломна от запоя [/url] .
вывод из запоя самара стационар [url=https://my.forum2.net/viewtopic.php?id=179]вывод из запоя самара стационар[/url] .
вывод из запоя самара стационар [url=forumbar.anihub.me/viewtopic.php?id=9763]вывод из запоя самара стационар[/url] .
капельницы от запоя [url=http://vip.mybb.rocks/viewtopic.php?id=7705]капельницы от запоя[/url] .
капельница от запоя стоимость [url=www.ekonomimvmeste.ukrbb.net/viewtopic.php?f=14&t=65415]капельница от запоя стоимость[/url] .
Узнайте, как безопасно купить диплом о высшем образовании
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense цены, можете посмотреть на сайте: ремонт телевизоров hisense рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Можно ли быстро купить диплом старого образца и в чем подвох?
капельница от запоя коломна [url=ivanovo.forum24.ru/?1-15-0-00000578-000-0-0-1730821749]капельница от запоя коломна [/url] .
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense рядом, можете посмотреть на сайте: ремонт телевизоров hisense адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Betflare Live Casino [url=http://www.betflare888.com]Betflare Live Casino[/url] .
Betflare Cashback [url=https://betflare8.com]Betflare Cashback[/url] .
капельницы от запоя [url=https://uaforum.ukrbb.net/viewtopic.php?f=13&t=3256/]капельницы от запоя[/url] .
капельницу коломна от запоя [url=https://skoleoz.borda.ru/?1-8-0-00001111-000-0-0-1730821724/]капельницу коломна от запоя [/url] .
капельница от запоя стоимость [url=https://gov.ukrbb.net/viewtopic.php?f=3&t=6390/]капельница от запоя стоимость[/url] .
Купить диплом судоводителя
Как официально купить диплом вуза с упрощенным обучением в Москве
Как получить диплом техникума с упрощенным обучением в Москве официально
Полезные советы по покупке диплома о высшем образовании без риска
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense, можете посмотреть на сайте: ремонт телевизоров hisense адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Диплом вуза купить официально с упрощенным обучением в Москве
Официальное получение диплома техникума с упрощенным обучением в Москве
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense рядом, можете посмотреть на сайте: ремонт телевизоров hisense
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Купить диплом судоводителя
Производство ангаров и складов под ключ.
Подробная информация и заказ быстровозводимый складов
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали срочный ремонт телевизоров hisense, можете посмотреть на сайте: ремонт телевизоров hisense адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense в москве, можете посмотреть на сайте: срочный ремонт телевизоров hisense
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров hisense, можете посмотреть на сайте: ремонт телевизоров hisense
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Всё о покупке аттестата о среднем образовании: полезные советы
Пошаговая инструкция по безопасной покупке диплома о высшем образовании
Купить диплом о среднем образовании в Москве и любом другом городе
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
продамус промокод скидка на подключение [url=www.promokod-prod.ru/]продамус промокод скидка на подключение[/url] .
Покупка школьного аттестата с упрощенной программой: что важно знать
Быстрая покупка диплома старого образца: возможные риски
Можно ли купить аттестат о среднем образовании? Основные рекомендации
Официальная покупка диплома ПТУ с упрощенной программой обучения
Быстрое обучение и получение диплома магистра – возможно ли это?
Возможно ли купить диплом стоматолога, и как это происходит
Официальная покупка диплома вуза с упрощенной программой обучения
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Полезная информация как официально купить диплом о высшем образовании
Производство ангаров и складов под ключ.
Подробная информация и заказ быстровозводимый складов
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
Узнайте стоимость диплома высшего и среднего образования и процесс получения
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Всё, что нужно знать о покупке аттестата о среднем образовании
Сколько стоит диплом высшего и среднего образования и как его получить?
Полезные советы по покупке диплома о высшем образовании без риска
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров haier рядом, можете посмотреть на сайте: ремонт телевизоров haier цены
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Покупка школьного аттестата с упрощенной программой: что важно знать
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Реально ли приобрести диплом стоматолога? Основные этапы
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телевизоров lg адреса, можете посмотреть на сайте: ремонт телевизоров lg
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Официальная покупка диплома вуза с упрощенной программой обучения
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали срочный ремонт телефонов xiaomi, можете посмотреть на сайте: ремонт телефонов xiaomi сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как быстро и легально купить аттестат 11 класса в Москве
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
продамус промокод скидка [url=http://www.krasnogorsk.anihub.me/viewtopic.php?id=18111#p23006]http://www.rubiz.forum.cool/viewtopic.php?id=3874#[/url] .
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов vivo адреса, можете посмотреть на сайте: срочный ремонт телефонов vivo
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов realme адреса, можете посмотреть на сайте: ремонт телефонов realme в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Официальная покупка диплома ВУЗа с упрощенной программой обучения
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов sony цены, можете посмотреть на сайте: ремонт телефонов sony
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
продамус промокод скидка [url=https://www.krut.forumno.com/viewtopic.php?id=6698#p26083]https://www.my.forum2.net/viewtopic.php?id=191#p22[/url] .
Полезные советы по покупке диплома о высшем образовании без риска
Сколько стоит получить диплом высшего и среднего образования легально?
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
Процесс получения диплома стоматолога: реально ли это сделать быстро?
Здесь можно оружейные шкафы москвасейф для пистолета и ружья
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов nothing, можете посмотреть на сайте: ремонт телефонов nothing
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов samsung адреса, можете посмотреть на сайте: ремонт телефонов samsung рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
продамус промокод скидка [url=www.vip.mybb.rocks/viewtopic.php?id=8484#p22318/]продамус промокод скидка[/url] .
продамус промокод скидка на подключение [url=www.severussnape.borda.ru/?1-4-0-00000385-000-0-0-1734553080]www.severussnape.borda.ru/?1-4-0-00000385-000-0-0-1734553080[/url] .
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов poco адреса, можете посмотреть на сайте: ремонт телефонов poco цены
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов meizu цены, можете посмотреть на сайте: ремонт телефонов meizu адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Купить диплом магистра оказалось возможно, быстрое обучение и диплом на руки
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов infinix, можете посмотреть на сайте: срочный ремонт телефонов infinix
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт телефонов honor рядом, можете посмотреть на сайте: ремонт телефонов honor
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Здесь можно сейфы для дома какой сейф купить для дома
I delight in, lead to I discovered exactly what I used to be taking a look for. You have ended my four day lengthy hunt! God Bless you man. Have a nice day. Bye
смотреть фильм
Тут можно преобрести цена взломостойких сейфов взломостойкий сейф для дома
Всё о покупке аттестата о среднем образовании: полезные советы
Легальная покупка школьного аттестата с упрощенной программой обучения
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин zanussi рядом, можете посмотреть на сайте: ремонт стиральных машин zanussi адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Hey there! I’m at work surfing around your blog from my new iphone 4! Just wanted to say I love reading your blog and look forward to all your posts! Carry on the fantastic work!
https://yoppa.org/wp-content/pgs/1xbet-promo-code_bonus-code.html
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин siemens в москве, можете посмотреть на сайте: ремонт стиральных машин siemens рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин smeg сервис, можете посмотреть на сайте: ремонт стиральных машин smeg адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Официальная покупка диплома вуза с сокращенной программой в Москве
Официальная покупка аттестата о среднем образовании в Москве и других городах
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин indesit, можете посмотреть на сайте: ремонт стиральных машин indesit
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин lg рядом, можете посмотреть на сайте: срочный ремонт стиральных машин lg
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как оказалось, купить диплом кандидата наук не так уж и сложно
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин kuppersbusch рядом, можете посмотреть на сайте: ремонт стиральных машин kuppersbusch
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Рекомендации по безопасной покупке диплома о высшем образовании
Где и как купить диплом о высшем образовании без лишних рисков
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт приставок xbox, можете посмотреть на сайте: ремонт приставок xbox адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин aeg сервис, можете посмотреть на сайте: ремонт стиральных машин aeg
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как оказалось, купить диплом кандидата наук не так уж и сложно
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин siemens, можете посмотреть на сайте: срочный ремонт посудомоечных машин siemens
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт приставок sony playstation адреса, можете посмотреть на сайте: ремонт приставок sony playstation цены
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин miele адреса, можете посмотреть на сайте: ремонт посудомоечных машин miele
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт стиральных машин dexp цены, можете посмотреть на сайте: ремонт стиральных машин dexp
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как оказалось, купить диплом кандидата наук не так уж и сложно
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин beko цены, можете посмотреть на сайте: ремонт посудомоечных машин beko цены
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин midea, можете посмотреть на сайте: ремонт посудомоечных машин midea в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Сколько стоит диплом высшего и среднего образования и как это происходит?
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин hotpoint ariston в москве, можете посмотреть на сайте: срочный ремонт посудомоечных машин hotpoint ariston
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт посудомоечных машин aeg сервис, можете посмотреть на сайте: срочный ремонт посудомоечных машин aeg
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
купить диплом ссср о среднем образовании
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Как получить диплом техникума с упрощенным обучением в Москве официально
Покупка школьного аттестата с упрощенной программой: что важно знать
Вопросы и ответы: можно ли быстро купить диплом старого образца?
Как получить диплом техникума с упрощенным обучением в Москве официально
Стоимость дипломов высшего и среднего образования и как избежать подделок
Возможно ли купить диплом стоматолога, и как это происходит
купить диплом о средне техническом образовании
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт ноутбуков sony сервис, можете посмотреть на сайте: ремонт ноутбуков sony адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
диплом купить в москве
Официальная покупка диплома ПТУ с упрощенной программой обучения
подделка диплома о высшем образовании [url=https://4russkiy365-diplomy.ru/]подделка диплома о высшем образовании[/url] .
Как избежать рисков при покупке диплома колледжа или ПТУ в России
Как оказалось, купить диплом кандидата наук не так уж и сложно
диплом о среднем специальном купить
Its like you read my mind! You appear to know a lot about this, like you wrote the book in it or something. I think that you could do with a few pics to drive the message home a little bit, but other than that, this is magnificent blog. A fantastic read. I will certainly be back.
#@G@G@G@G#
http://www.waltbabylove.com/upload/image/inc/?1xbet_india_promo_codes.html
Сколько стоит диплом высшего и среднего образования и как его получить?
Как безопасно купить диплом колледжа или ПТУ в России, что важно знать
купить диплом о высшем образовании старого образца
Как быстро и легально купить аттестат 11 класса в Москве
Можно ли быстро купить диплом старого образца и в чем подвох?
где купить диплом техникума [url=https://4russkiy365-diplomy.ru/]где купить диплом техникума[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании
школьный аттестат купить
Покупка диплома о среднем полном образовании: как избежать мошенничества?
Как приобрести аттестат о среднем образовании в Москве и других городах
купить диплом о высшем образовании в магнитогорске [url=https://4russkiy365-diplomy.ru/]4russkiy365-diplomy.ru[/url] .
диплом купить казань
Легальные способы покупки диплома о среднем полном образовании
Купить диплом о высшем образовании в Курске
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
Официальная покупка школьного аттестата с упрощенным обучением в Москве
купить диплом разработка [url=https://4russkiy365-diplomy.ru/]4russkiy365-diplomy.ru[/url] .
купить диплом специалиста
купить диплом вуза в иркутске [url=https://2orik-diploms.ru/]2orik-diploms.ru[/url] .
сколько стоит купить красный диплом [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
Как официально приобрести аттестат 11 класса с минимальными затратами времени
Официальная покупка диплома вуза с сокращенной программой в Москве
Диплом вуза купить официально с упрощенным обучением в Москве
купить диплом судоводителя
менеджер по продажам вакансии екатеринбург [url=https://4russkiy365-diplomy.ru/]менеджер по продажам вакансии екатеринбург[/url] .
Официальная покупка школьного аттестата с упрощенным обучением в Москве
Как не стать жертвой мошенников при покупке диплома о среднем полном образовании
Процесс получения диплома стоматолога: реально ли это сделать быстро?
купить диплом о высшем образовании с занесением [url=https://2orik-diploms.ru/]купить диплом о высшем образовании с занесением[/url] .
купить диплом в волгограде [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
купить аттестат в москве
где можно купить настоящий диплом об образовании [url=https://4russkiy365-diplomy.ru/]4russkiy365-diplomy.ru[/url] .
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
Как оказалось, купить диплом кандидата наук не так уж и сложно
Процесс получения диплома стоматолога: реально ли это сделать быстро?
диплом сестринское дело купить
Как официально купить диплом вуза с упрощенным обучением в Москве
диплом купить
WOW just what I was searching for. Came here by searching for %keyword%
https://millionigrushek.ru/
Как безопасно купить диплом колледжа или ВУЗа в России, что важно знать
диплом слесаря купить
диплом купить в рязани
Приобретение диплома ВУЗа с сокращенной программой обучения в Москве
Hi there, after reading this awesome piece of writing i am too cheerful to share my knowledge here with mates.
https://ch-z.com.ua/bi-led-linzy-dlya-avto-pokrashchit-vydymist-ta-bezpeku-na-dorozi
888starz Rocket X Cameroun
1win bet Colombia
Vavada
купить диплом техника